目标检测算法SSD与FasterRCNN
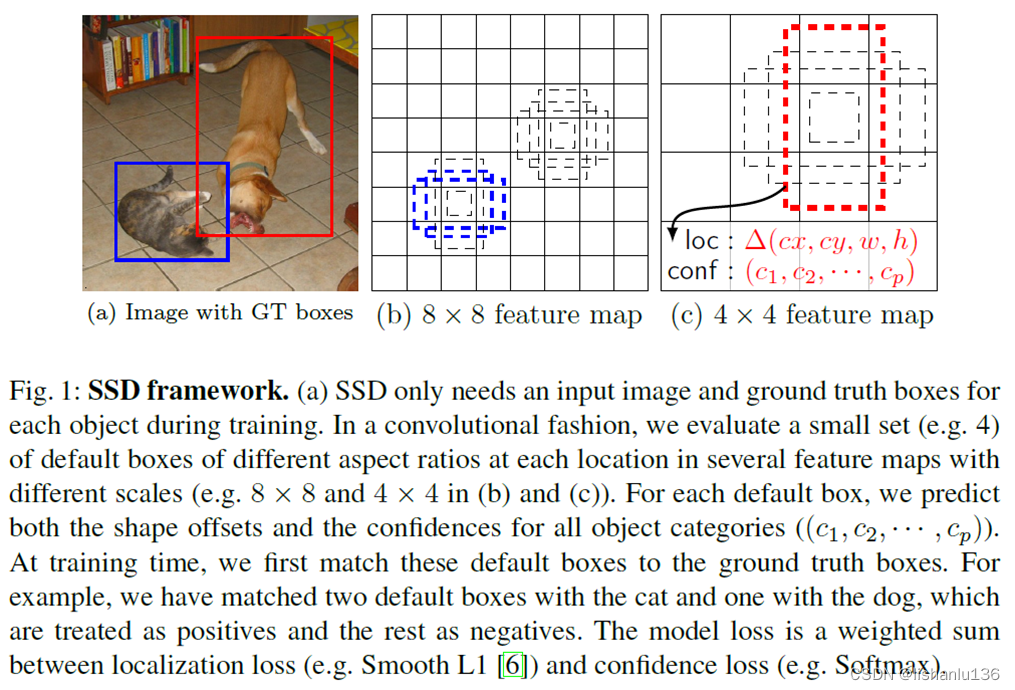
SSD:( Single Shot MultiBox Detector)特点是在不同特征尺度上预测不同尺度的目标。
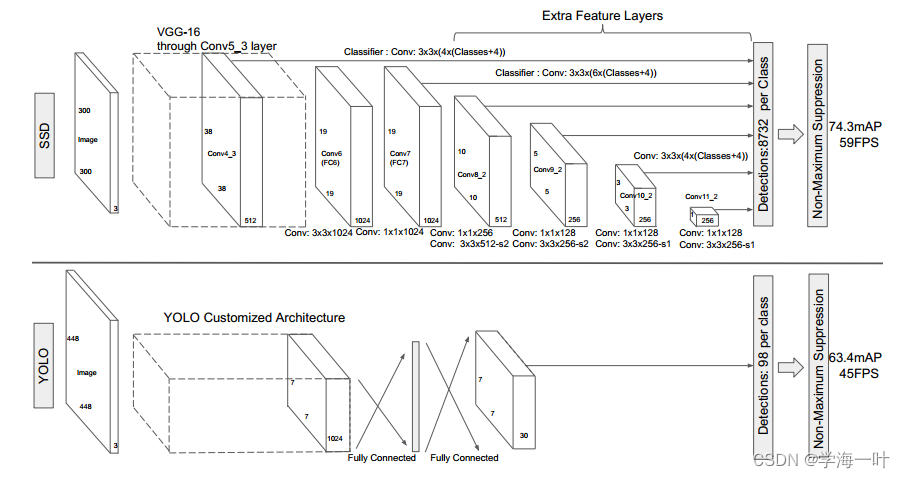
SSD网络结构

首先对网络的特征进行说明:输入的图像是300x300的三通道彩色图像。
网络的第一个部分贯穿到Vgg16模型 Conv5的第三层上
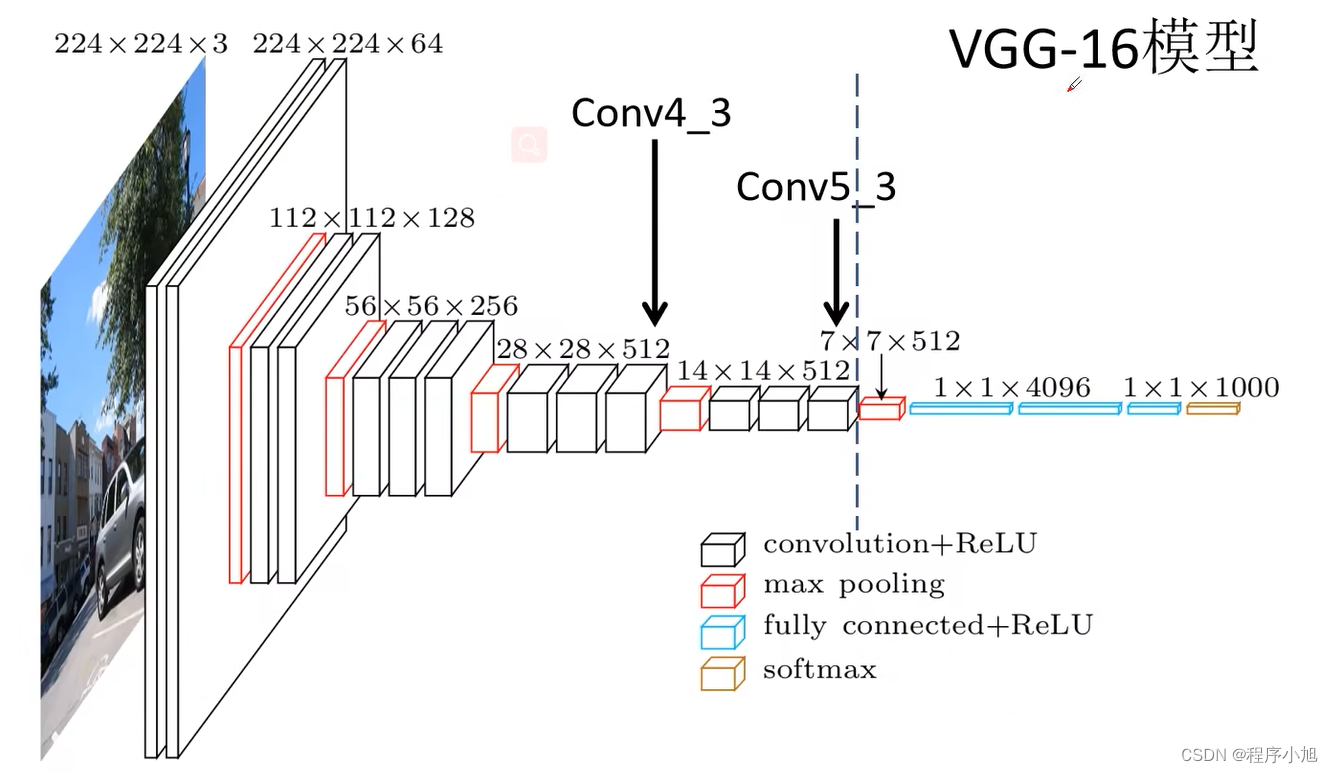
整个SSD网络的第一个预测特征层就是conv4的第三层,得到的是38x38的512通道的特征图。
采用vgg网络通常是将大小进行减半,通道数进行翻倍的操作。300 150 75 38即为ssd网络的第一个预测特征层。
之后我们对maxpooling进行一个更改操作。变为3x3步幅为1是特征层的大小保持不变。
之后FC6和FC7替代的是vgg网络中的两个全连接层:首先是通过3x3的卷积核步距为2对其进行一个缩放处理得到的是19x19的一个特征输出,之后连接一个1x1的卷积核进行通道的融合,从而得到了第二个预测的特征。
后面的分析过程基本相同:按照图示来进行分析即可,最后会得到6个预测特征层4
即为1x1的256通道的预测特征层。
不同特征尺度上预测不同尺度的目标:在较小的特征层上检测较大的目标,在较大的特征层上检测较小的目标。
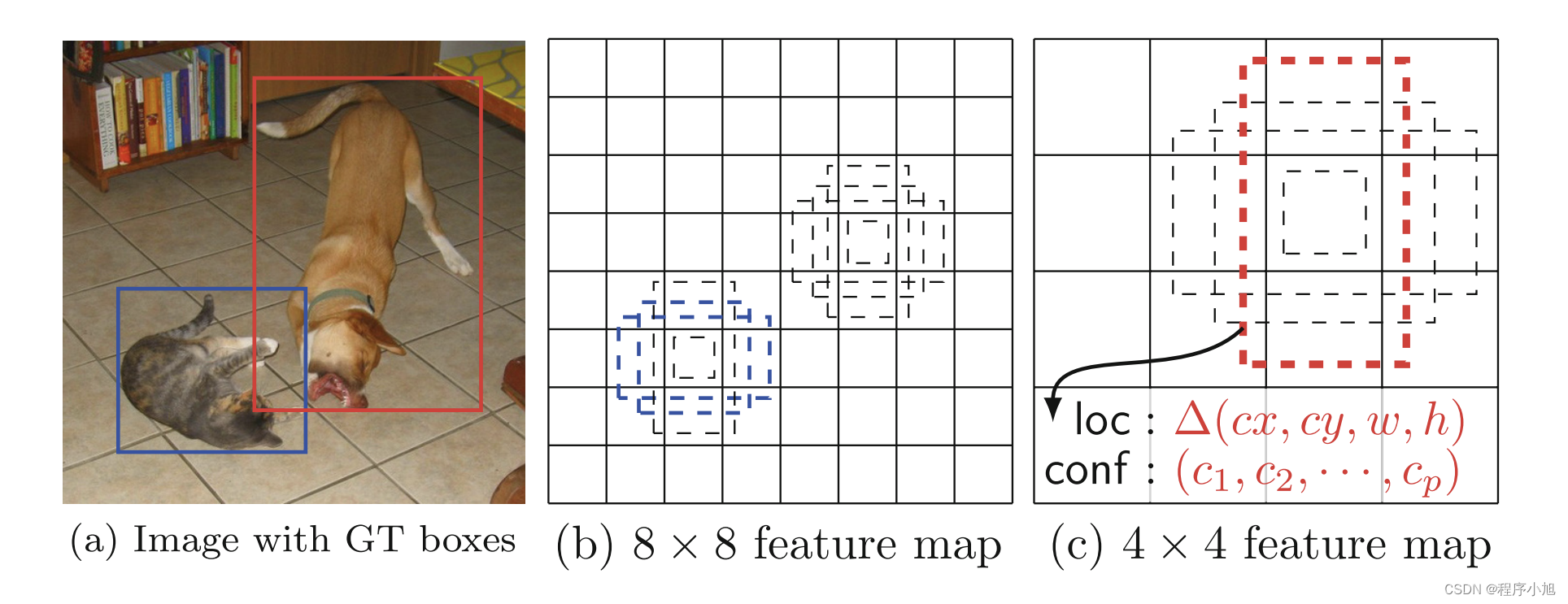
Default Box的scale以及aspect设定

论文中的原文提到了conv4_3 conv10_2和conv11_2我们只使用4个default box而其他的层使用的是默认的6个default box并且这4个default box会忽略掉1:3和3:1的两个比例。
不使用论文中的计算公式而采用:下面提供的比例和尺度信息。
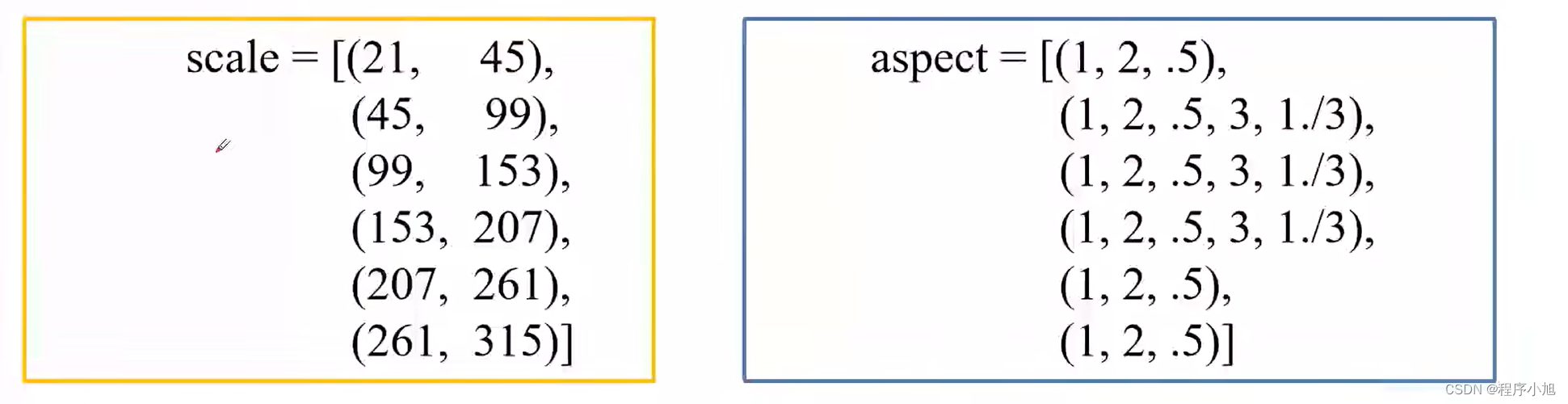
下面的图表从总体上说明了各个特征图的Default Box的scale以及aspect

总共会生成:38x38x4 + 19x19x6 + 10x10x6 + 5x5x6 + 3x3x4 + 1x1x4 = 8732个Default Box
与ssd论文网络结构图中的8732个特征层相同。
也体现了之前学习的动手学深度学习中的多尺度锚框的思想,在特征图的每一个像素位置生成锚框。
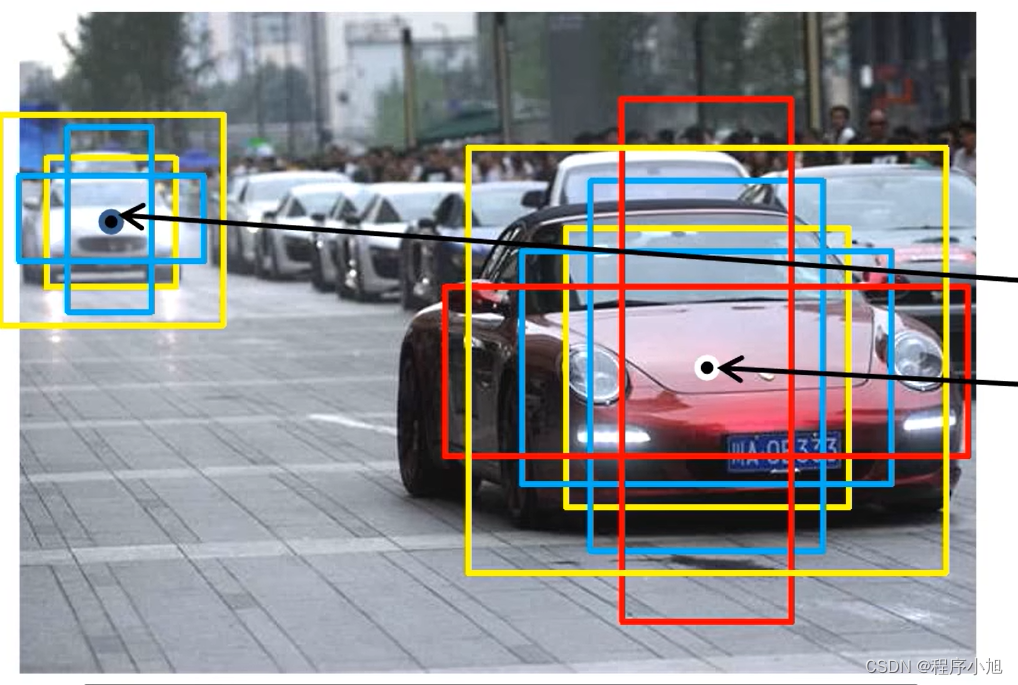
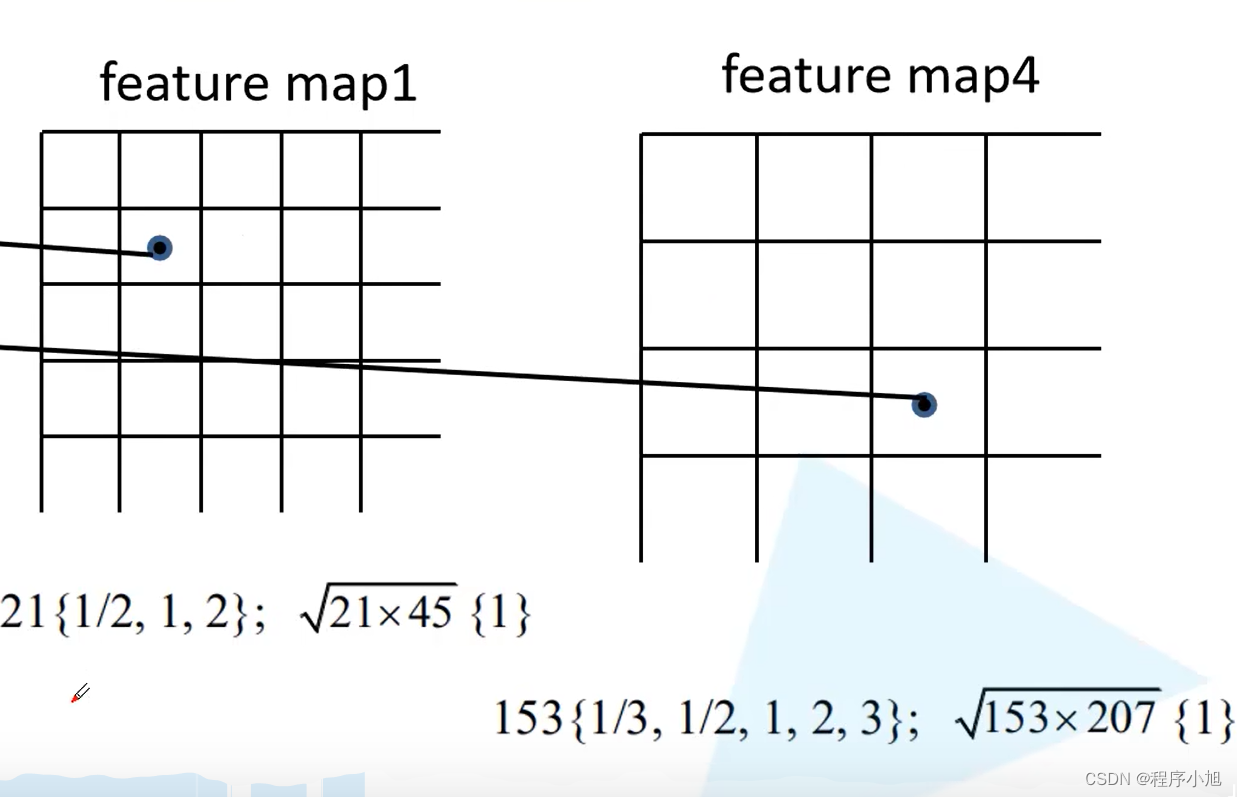
图示即为在feature map1 feature map4中生成的锚框。
Predictor的实现
预测器的实现步骤
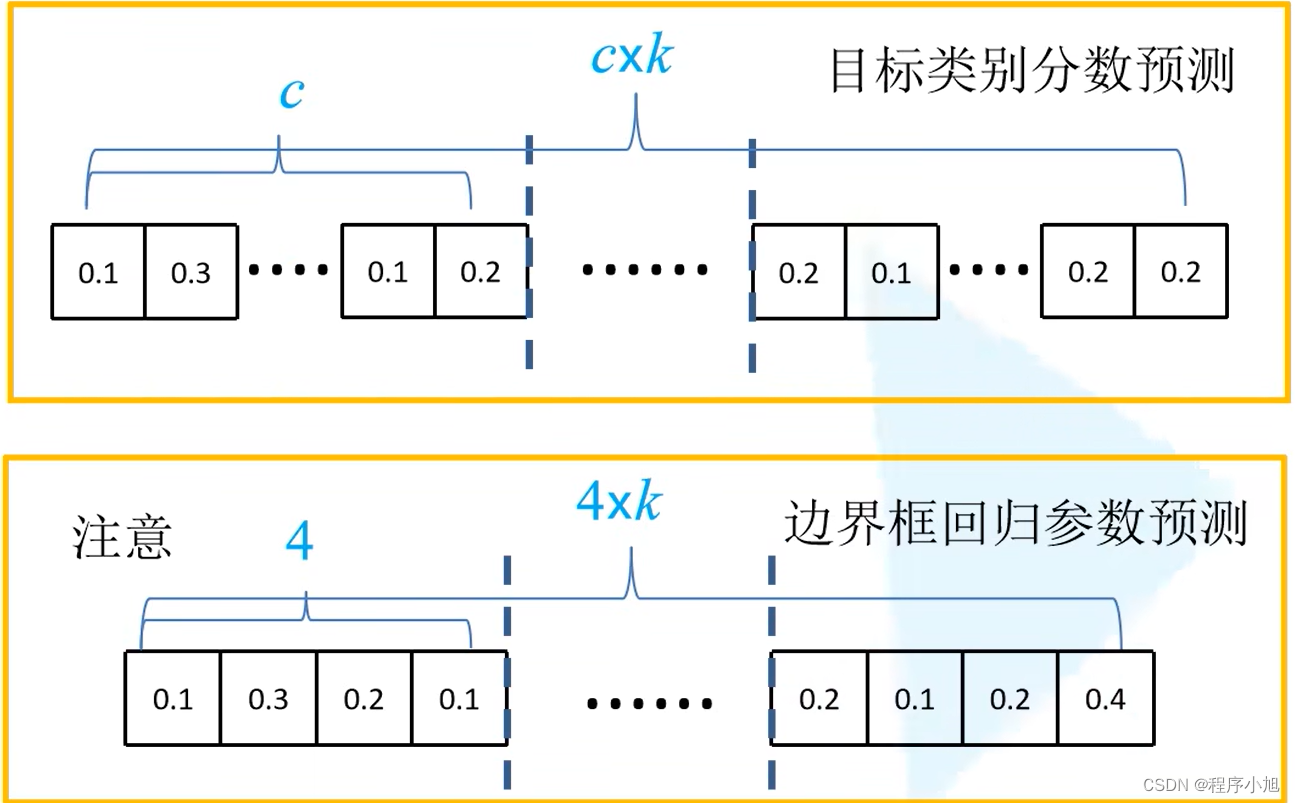
首先我们会采用(C+4)×k =cxk+4xk个卷积核来进行预测其中ck个是用来预测我们的类别分数。4k即为边界框回归参数。x y w h
注意是:c是包含背景类别的
损失函数计算
L ( x , c , l , g ) = 1 N ( L c o n f ( x , c ) + α L(x, c, l, g)=\frac{1}{N}\left(L_{c o n f}(x, c)+\alpha\right. L(x,c,l,g)=N1(Lconf(x,c)+α
损失的计算也主要包括两个部分组成,分别是类别损失和定位损失两个部分。
其中N为匹配到的正样本个数,α为1
类别损失的概率为:(相当于是一个softmax的损失)
L conf ( x , c ) = − ∑ i ∈ Pos N x i j p log ( c ^ i p ) − ∑ i ∈ N e g log ( c ^ i 0 ) where c ^ i p = exp ( c i p ) ∑ p exp ( c i p ) L_{\text {conf }}(x, c)=-\sum_{i \in \text { Pos }}^{N} x_{i j}^{p} \log \left(\hat{c}_{i}^{p}\right)-\sum_{i \in N e g} \log \left(\hat{c}_{i}^{0}\right) \quad \text { where } \quad \hat{c}_{i}^{p}=\frac{\exp \left(c_{i}^{p}\right)}{\sum_{p} \exp \left(c_{i}^{p}\right)} Lconf (x,c)=−i∈ Pos ∑Nxijplog(c^ip)−i∈Neg∑log(c^i0) where c^ip=∑pexp(cip)exp(cip)

定位损失与FastRcnn相同,具体参考fastRcnn的部分进行补充学习。
L l o c ( x , l , g ) = ∑ i ∈ P o s N ∑ m ∈ { c x , c y , w , h } x i j k smooth L 1 ( l i m − g ^ j m ) g ^ j c x = ( g j c x − d i c x ) / d i w g ^ j c y = ( g j c y − d i c y ) / d i h g ^ j w = log ( g j w d i w ) g ^ j h = log ( g j h d i h ) \begin{aligned} L_{l o c}(x, l, g) & =\sum_{i \in P o s}^{N} \sum_{m \in\{c x, c y, w, h\}} x_{i j}^{k} \operatorname{smooth}_{\mathrm{L} 1}\left(l_{i}^{m}-\hat{g}_{j}^{m}\right) \\ \hat{g}_{j}^{c x}=\left(g_{j}^{c x}-d_{i}^{c x}\right) / d_{i}^{w} & \hat{g}_{j}^{c y}=\left(g_{j}^{c y}-d_{i}^{c y}\right) / d_{i}^{h} \\ \hat{g}_{j}^{w}=\log \left(\frac{g_{j}^{w}}{d_{i}^{w}}\right) & \hat{g}_{j}^{h}=\log \left(\frac{g_{j}^{h}}{d_{i}^{h}}\right) \end{aligned} Lloc(x,l,g)g^jcx=(gjcx−dicx)/diwg^jw=log(diwgjw)=i∈Pos∑Nm∈{cx,cy,w,h}∑xijksmoothL1(lim−g^jm)g^jcy=(gjcy−dicy)/dihg^jh=log(dihgjh)
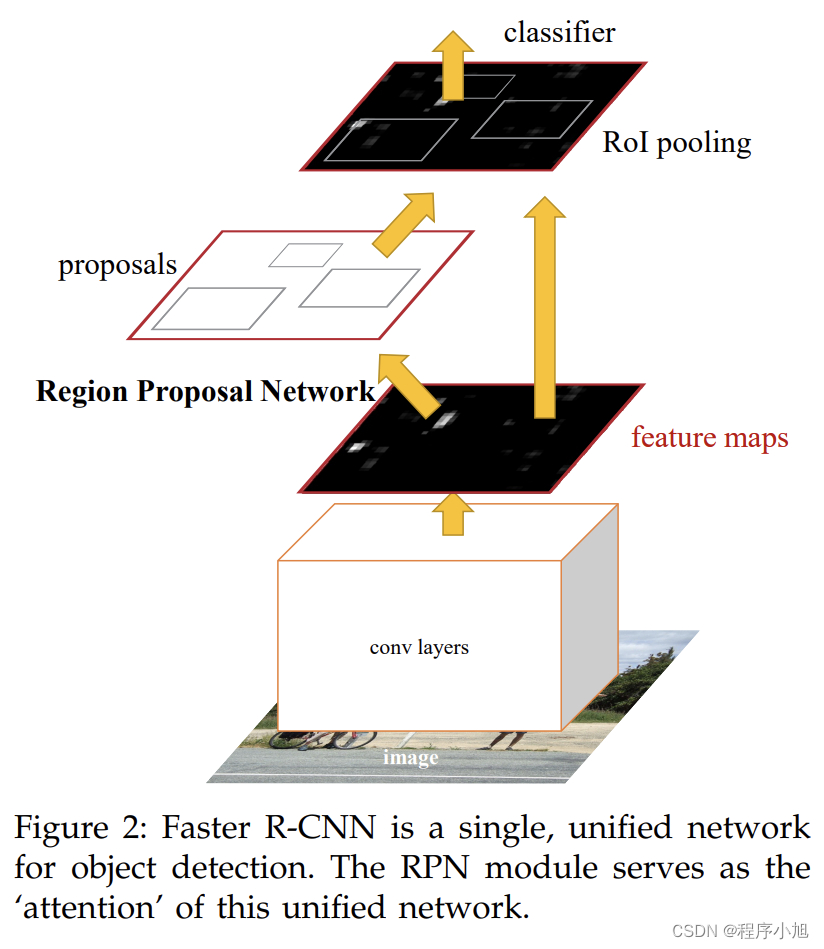
Faster R-CNN
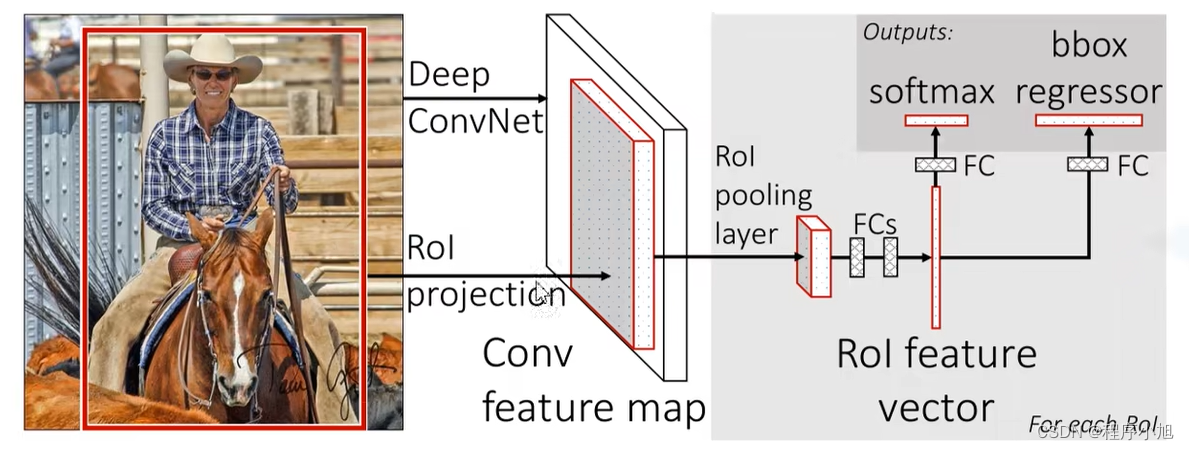
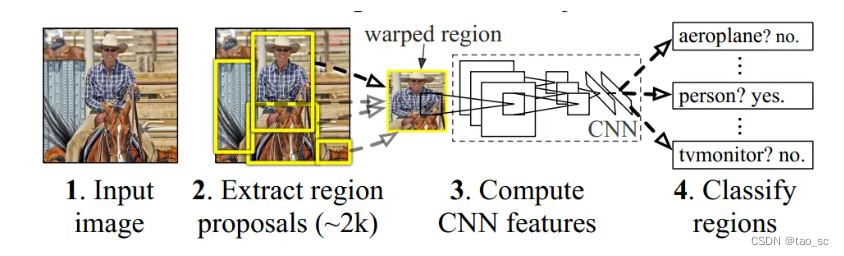
FastR-CNN算法流程可分为3个步骤
- 一张图像生成1K~2K个候选区域(使用SelectiveSearch方法)
- 将图像输入网络得到相应的特征图,将SS算法生成的候选框投影到
特征图上获得相应的特征矩阵 - 将每个特征矩阵通过R0Ipooling层缩放到7x7大小的特征图,接着将
特征图展平通过一系列全连接层得到预测结果。
FasterR-CNN算法流程可分为3个步骤
- 将图像输入网络得到相应的特征图
- 使用RPN结构生成候选框,将RPN生成的候选框投影到特征图上获得相应的特征矩阵
- 将每个特征矩阵通过R0I pooling层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果
RPN + Fast R-CNN
RPN替代SS算法分析
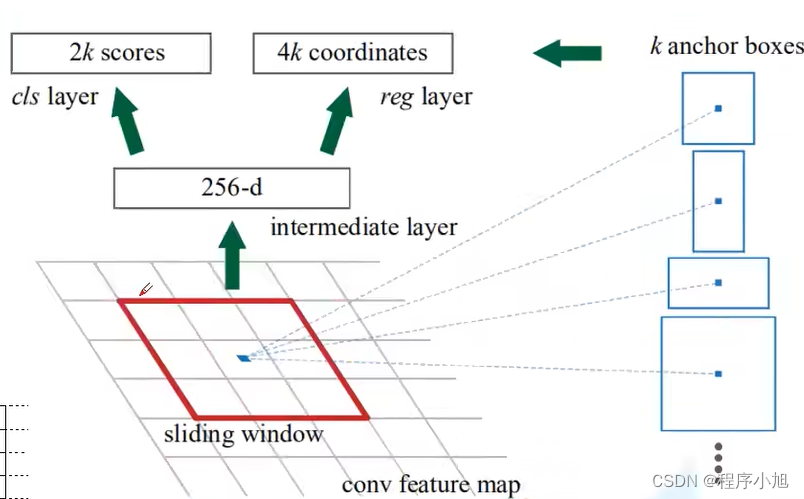
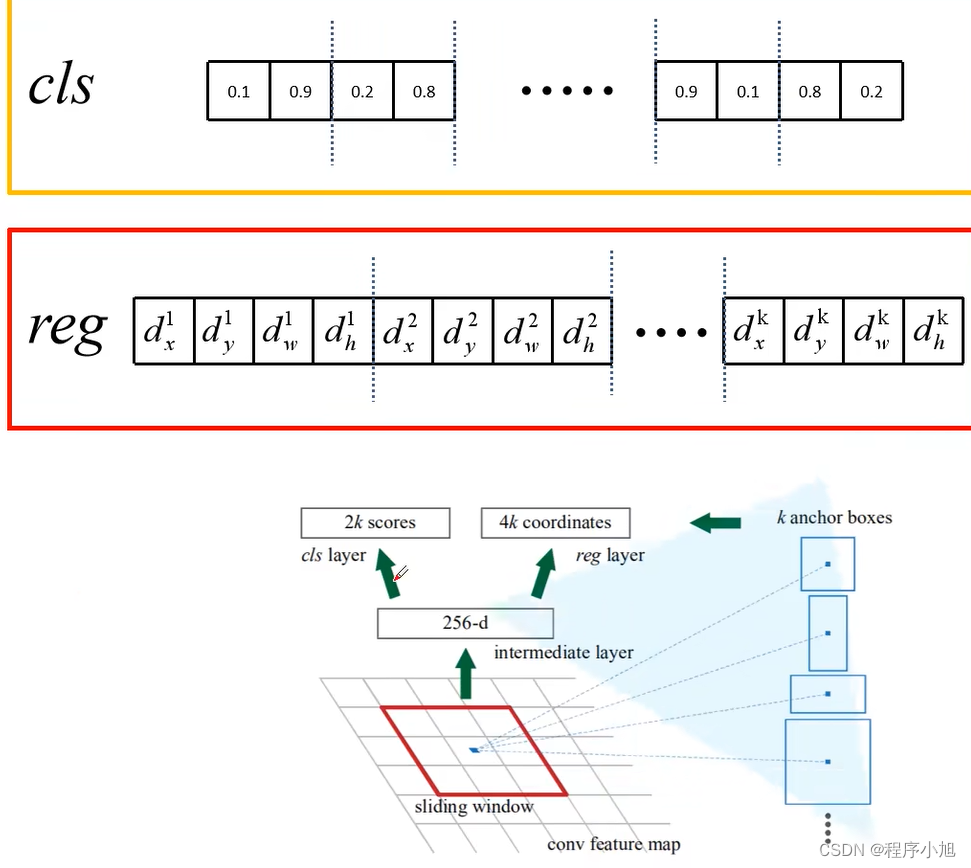
对于特征图上的每个3x3的滑动,窗口,计算出滑动窗口中心点对应
原始图像上的中心点,并计算出K个anchor boxes(注意和proposal的差异)。
4k:即为边界框的回归坐标参数。
2k: 即为k个锚框是背景和其他类别的概率信息。
根据原图和特征图的比例关系,确定特征图中的每个像素在原图中所对对应的位置信息。在以该点为中心计算出k个锚框。
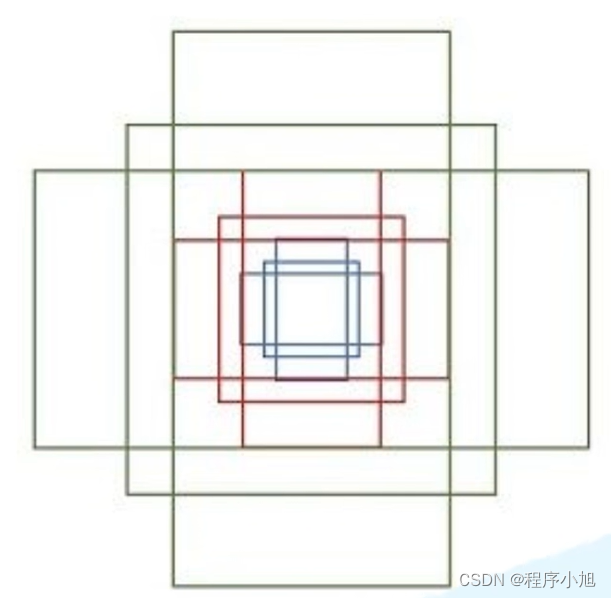
尺度与比例的计算
三种尺度(面积){128x128,256x256,512x512}
三种比例{1:1, 1:2。2:1}
将尺度与比例进行融合:每个位置(每个滑动窗口)在原图上都对应有3x3=9anchor
对于一张1000x600x3的图像,大约有60x40x9(20k)个anchor,忽略跨越边界的anchor以后,剩下约6k个anchor。对于RPN生成的候选框之间存在大量重叠,基于候选框的cls得分,采用非极大值抑制,IoU设为0.7,这样每张图片只剩2k个候选框。
损失函数计算
损失函数的计算同样包括了边界框回归损失与分类损失。
L ( { p i } , { t i } ) = 1 N c l s ∑ i L c l s ( p i , p i ∗ ) + λ 1 N reg ∑ i p i ∗ L reg ( t i , t j ∗ ) L\left(\left\{p_{i}\right\},\left\{t_{i}\right\}\right)=\frac{1}{N_{c l s}} \sum_{i} L_{c l s}\left(p_{i}, p_{i}^{*}\right)+\lambda \frac{1}{N_{\text {reg }}} \sum_{i} p_{i}^{*} L_{\text {reg }}\left(t_{i}, t_{j}^{*}\right) L({pi},{ti})=Ncls1i∑Lcls(pi,pi∗)+λNreg 1i∑pi∗Lreg (ti,tj∗)
- Ncls表示一个mini-batch中的所有样本数量256
- Nreg表示anchor位置的个数(不是anchor个数)约2400
其中的回归损失的计算如下:
L reg ( t i , t i ∗ ) = ∑ i smooth L 1 ( t i − t i ∗ ) t i = [ t x , t y , t w , t h ] t i ∗ = [ t x ∗ , t y ∗ , t w ∗ , t h ∗ ] \begin{array}{l} L_{\text {reg }}\left(t_{i}, t_{i}^{*}\right)=\sum_{i} \operatorname{smooth}_{L_{1}}\left(t_{i}-t_{i}^{*}\right) \\ t_{i}=\left[t_{x}, t_{y}, t_{w}, t_{h}\right] \quad t_{i}^{*}=\left[t_{x}^{*}, t_{y}^{*}, t_{w}^{*}, t_{h}^{*}\right] \end{array} Lreg (ti,ti∗)=∑ismoothL1(ti−ti∗)ti=[tx,ty,tw,th]ti∗=[tx∗,ty∗,tw∗,th∗]
- ti表示预测第i个anchor的边界框回归参数
- ti*表示第i个anchor对应的GTBox的回归参数
下面给出回归参数的计算公式:
t x = ( x − x a ) / w a , t y = ( y − y a ) / h a , t w = log ( w / w a ) , t w = log ( h / h a ) , t x ∗ = ( x ∗ − x a ) / w a , t y ∗ = ( y ∗ − y a ) / h a , t w ∗ = log ( w ∗ / w a ) , t h ∗ = log ( h ∗ / h a ) \begin{array}{l} t_{x}=\left(x-x_{a}\right) / w_{a}, t_{y}=\left(y-y_{a}\right) / h_{a}, \\ t_{w}=\log \left(w / w_{a}\right), t_{w}=\log \left(h / h_{a}\right), \\ t_{x}^{*}=\left(x^{*}-x_{a}\right) / w_{a}, t_{y}^{*}=\left(y^{*}-y_{a}\right) / h_{a}, \\ t_{w}^{*}=\log \left(w^{*} / w_{a}\right), t_{h}^{*}=\log \left(h^{*} / h_{a}\right) \end{array} tx=(x−xa)/wa,ty=(y−ya)/ha,tw=log(w/wa),tw=log(h/ha),tx∗=(x∗−xa)/wa,ty∗=(y∗−ya)/ha,tw∗=log(w∗/wa),th∗=log(h∗/ha)
带入smoothl1函数中得到最后的结果
smoothl1函数的表达形式为:
smooth L 1 ( x ) = { 0.5 x 2 if ∣ x ∣ < 1 ∣ x ∣ − 0.5 otherwise \text { smooth }_{L_{1}}(x)=\left\{\begin{array}{ll} 0.5 x^{2} & \text { if }|x|<1 \\ |x|-0.5 & \text { otherwise } \end{array}\right. smooth L1(x)={0.5x2∣x∣−0.5 if ∣x∣<1 otherwise
下面介绍分类损失的计算信息。
- p,表示第i个anchor预测为真实标签的概率
- p*当为正样本时为1,当为负样本时为0
第一种计算的损失为:多分类损失的计算
L c l s = − ln ( p i ) L_{c l s}=-\ln \left(p_{i}\right) Lcls=−ln(pi)
正样本时为1,当为负样本时为0将负样本的情况进行省略。得到上面的计算公式。
另外一种的计算方式是使用二值交叉熵损失来进行计算。

L c l s = − [ p i ∗ log ( p i ) + ( 1 − p i ∗ ) log ( 1 − p i ) ] L_{c l s}=-\left[p_{i}^{*} \log \left(p_{i}\right)+\left(1-p_{i}^{*}\right) \log \left(1-p_{i}\right)\right] Lcls=−[pi∗log(pi)+(1−pi∗)log(1−pi)]
Faster R-CNN训练
现在Faster R-CNN的训练直接采用RPNLoss+FastR-CNNLoss的联合训练方法。
原论文中采用分别训练RPN以及FastR-CNN的方法。
(1)利用imageNet预训练分类模型初始化前置卷积网络层参数,并
开始单独训练RPN网络参数;
(2)固定RPN网络独有的卷积层以及全连接层参数,再利用ImageNet预训练分类模型初始化前置卷积网络参数,并利用RPN网络生成的目标建议框去训练FastRCNN网络参数。
(3)固定利用FastRCNN训练好的前置卷积网络层参数,去微调RPN网络独有的卷积层以及全连接层参数。
(4)同样保持固定前置卷积网络层参数,去微调FastRCNN网络的全连接层参数。最后RPN网络与FaStRCNN网络共享前置卷积网络层.





























![[力扣二叉树]本地调试环境指导手册](https://img-blog.csdnimg.cn/direct/e06d886806bd41deabe249f6c11964e9.png#pic_center)