.
.
.
.
.
.纯干货
.
.
.
.
.
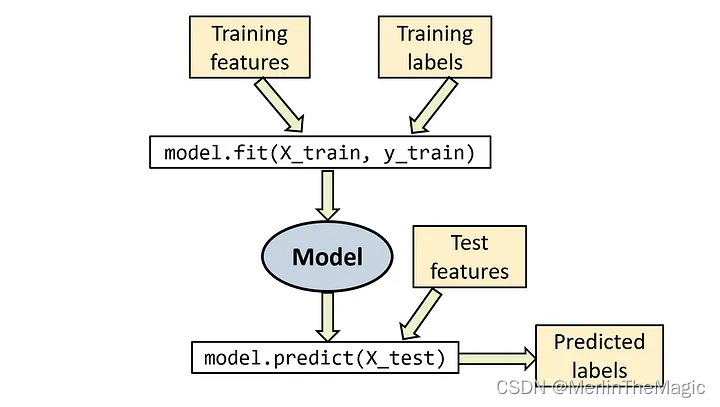
无监督学习是在没有标签的数据上训练的。其主要目的可能包括聚类、降维、生成模型等。
以下是 6 个重要的无监督学习算法,这些算法都可以通过使用sklearn(Scikit-learn)库在Python中很好地处理:
目录
K-Means 聚类
数据准备
首先,我们导入必要的库和数据,并进行基本的数据探查。
这里,准备了名称为「customer_data.csv」的数据集,维度分别为``Age, Annual_Income 和Spending_Score`作为 3 个特征。
获取数据集:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import StandardScaler
from time import time
# 假定你已将上文的数据存储为'customer_data.csv'
data = pd.read_csv("customer_data.csv")
数据标准化
因为K-Means聚类是距离基础的算法,我们通常在进行聚类分析之前会标准化我们的数据。
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
确定K值
这里我们使用轮廓系数(Silhouette Score)来帮助我们确定适当的K值。
轮廓系数是在-1到1之间的,一个高的轮廓系数表明样本点离其他类的距离较远。
k_values = range(2, 11)
silhouette_scores = []
for k in k_values:
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(scaled_data)
silhouette_scores.append(silhouette_score(scaled_data, kmeans.labels_))
plt.plot(k_values, silhouette_scores, marker='o')
plt.title('Silhouette Score for Different k')
plt.xlabel('k')
plt.ylabel('Silhouette Score')
plt.show()
模型训练
从轮廓系数图中选择一个合适的 K 值进行模型训练,并可视化结果。
# 假设我们选择k=3
k = 3
kmeans = KMeans(n_clusters=k, random_state=42)
clusters = kmeans.fit_predict(scaled_data)
# 可视化结果
plt.scatter(scaled_data[clusters == 0, 0], scaled_data[clusters == 0, 1], label='Cluster 1')
plt.scatter(scaled_data[clusters == 1, 0], scaled_data[clusters == 1, 1], label='Cluster 2')
plt.scatter(scaled_data[clusters == 2, 0], scaled_data[clusters == 2, 1], label='Cluster 3')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=300, c='red', label='Centroids')
plt.title('Clusters of Customers')
plt.xlabel('Age (scaled)')
plt.ylabel('Spending Score (scaled)')
plt.legend()
plt.show()
这三个群集可能分别代表以下客户类型:
Cluster 1: 年轻且花费适中的客户群体
Cluster 2: 年轻且花费较高的客户群体
Cluster 3: 年纪较大且花费较低的客户群体
商业决策将基于这些群体的特点来制定。例如,针对花费较高的年轻客户群体,可以提供最新的产品推广或者特殊折扣,以便进一步激励他们的购买行为。
以上代码及分析基于假定的数据。在现实项目中,要充分理解业务背景、数据的含义并根据业务目标来决定聚类的数量及如何解读各个群体的特征。
层次聚类
为了便于展示,我们使用上文中的customer_data.csv数据。我们将使用层次聚类(Hierarchical Clustering)探索数据内在的群集结构。
咱们关注的特征依然是Age, Annual_Income, 和Spending_Score。
数据准备
如之前例子一样,首先进行数据导入和标准化。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import dendrogram, linkage
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import AgglomerativeClustering
# 读取数据
data = pd.read_csv("customer_data.csv")
# 数据标准化
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
层次聚类模型
构建并可视化树状图 (Dendrogram)
我们用scipy中的linkage和dendrogram函数来构建层次聚类的树状图。
linked = linkage(scaled_data, 'ward') # 使用Ward连接方法
plt.figure(figsize=(10, 7))
dendrogram(linked,
orientation='top',
labels=data.index,
distance_sort='descending',
show_leaf_counts=True)
plt.show()
训练模型并可视化结果
选择一个合适的距离阈值或群集数量进行模型训练,并可视化结果。
# 定义模型并指定我们想要的群集数量
cluster = AgglomerativeClustering(n_clusters=3, affinity='euclidean', linkage='ward')
# 训练模型并预测标签
cluster_labels = cluster.fit_predict(scaled_data)
# 可视化结果
plt.figure(figsize=(10, 7))
plt.scatter(scaled_data[:,0], scaled_data[:,1], c=cluster_labels, cmap='rainbow')
plt.title('Clusters of Customers')
plt.xlabel('Age (scaled)')
plt.ylabel('Spending Score (scaled)')
plt.show()
与K-Means聚类类似,我们可以根据生成的群集进行进一步分析。例如,每个群集的中心的特征可以被认为是该群集的“代表”特征。由于我们使用了相同的特征(Age和Spending_Score),群集的解释将与前文类似。
注意点
1、距离计算:affinity参数表示用于计算距离的方法。在本例中,我们使用了欧几里得距离。
2、链接方法:linkage参数表示用于链接群集的方法。在本例中,我们使用了Ward方法,该方法试图最小化群集内的方差。
3、选择群集数量:在生成的树状图中,通常选择一个“高度”来切割树形结构,并形成各个群集。在这个示例中,我们预先选择了群集的数量。在实际分析中,你也可以选择在树状图中一个合适的高度来切割群集。
DBSCAN
咱们继续使用customer_data.csv数据集来演示DBSCAN。
数据准备
DBSCAN模型构建与训练
首先选定DBSCAN的两个主要参数:邻域大小(eps)和最小点数(min_samples)。
# 实例化DBSCAN模型
dbscan = DBSCAN(eps=0.5, min_samples=5)
# 训练模型
clusters = dbscan.fit_predict(scaled_data)
# 计算轮廓系数
print(f'Silhouette Score: {silhouette_score(scaled_data, clusters):.2f}')
结果可视化
我们用散点图展示聚类的结果。
# 可视化
plt.scatter(scaled_data[:,0], scaled_data[:,1], c=clusters, cmap='plasma')
plt.title('DBSCAN Clustering')
plt.xlabel('Age (scaled)')
plt.ylabel('Spending Score (scaled)')
plt.show()
轮廓系数:展示了群集的密度和分离度。范围从-1到1,值越高表明聚类效果越好。由于DBSCAN能够识别噪声,轮廓系数可能会受到噪声点的影响。
图形分析:可视化结果允许我们直观地看到不同的群集及其形状。DBSCAN能够找到非球形的群集,这是其独有的优点。
注意点
参数选择:
eps和min_samples的选择对模型影响很大。一个常见的方法是使用k-距离图来估计eps。通常需要多次尝试来找到合适的参数。标准化的重要性:由于DBSCAN依赖于距离的计算,所以标准化通常是必需的。
处理不均衡数据:DBSCAN可能在不同密度的群集之间表现不佳。在数据的分布非常不均匀时,可能需要调整参数或选择其他算法。
噪声点:DBSCAN将不属于任何群集的点归类为噪声(即,将其标签为-1)。在结果解释和进一步分析时需要注意这一点。
DBSCAN提供了一种不需要预先指定群集数量的聚类方法,并且可以找到复杂形状的群集。然而,它对参数的选择非常敏感,需要仔细进行调整和验证。
主成分分析
主成分分析(PCA)是一种在降维和可视化高维数据方面非常流行的技术。通过找到数据的主轴并将数据投影到这些轴上来减少数据的维度,从而尽可能保留数据的方差。
数据准备
假设我们有一个包含3个特征的 150x3 的数据集。我们的目标是将这些数据从3D空间降维到2D空间以便进行可视化。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
# 使用iris数据集
iris = load_iris()
X = iris.data # 特征矩阵, shape: (150, 4)
y = iris.target # 目标变量, shape: (150,)
# 标准化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
模型训练
# 实施PCA
pca = PCA(n_components=2) # 我们将数据投影到前两个主成分
X_pca = pca.fit_transform(X_scaled)
数据可视化
# 创建一个新的figure
plt.figure(figsize=(8,6))
# 遍历标签,为不同的标签创建不同的散点图
for target, color in zip(iris.target_names, ['r', 'g', 'b']):
indicesToKeep = iris.target == np.where(iris.target_names == target)[0][0]
plt.scatter(X_pca[indicesToKeep, 0],
X_pca[indicesToKeep, 1],
c = color,
s = 50)
# 增加图例和坐标轴的标签
plt.legend(iris.target_names, loc='upper right', fontsize='x-large')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('2D PCA of Iris Dataset')
plt.grid(True)
# 显示图形
plt.show()
解释方差
explained_variance = pca.explained_variance_ratio_
print(f"Explained variance: {explained_variance}")
从上面的2D散点图中,你可以看到3种不同的鸢尾花在投影到前两个主成分上时是如何分开的。另外,解释的方差告诉我们前两个主成分保存了多少原始数据的方差。在许多情况下,希望这些主成分包含了足够多的信息,以便在丢失最小量的信息的情况下利用它们。
这个简单的示例展示了PCA的工作方式和它如何在实践中实施。
独立成分分析
独立成分分析是一种用于从混合信号中恢复原始信号的技术,通常用于盲源分离和信号处理。
数据准备
首先,我们需要准备一个包含混合信号的虚拟数据集。
以下示例中,创建两个独立的信号并将它们线性混合。
import numpy as np
# 创建两个独立的信号
signal_1 = np.random.rand(1000)
signal_2 = np.sin(np.linspace(0, 100, 1000))
# 创建混合信号
mixing_matrix = np.array([[2, 1], [1, 2]]) # 混合矩阵
mixed_signals = np.dot(np.vstack((signal_1, signal_2)).T, mixing_matrix.T)
ICA模型训练
使用Scikit-Learn中的FastICA来拟合ICA模型,以恢复原始信号。
from sklearn.decomposition import FastICA
ica = FastICA(n_components=2)
recovered_signals = ica.fit_transform(mixed_signals)
绘制混合信号和恢复信号的图形
我绘制混合信号和恢复信号的图形,以可视化ICA的效果。
import matplotlib.pyplot as plt
# 绘制混合信号
plt.figure(figsize=(12, 6))
plt.subplot(2, 2, 1)
plt.plot(signal_1, label='Signal 1')
plt.title('Original Signal 1')
plt.subplot(2, 2, 2)
plt.plot(signal_2, label='Signal 2')
plt.title('Original Signal 2')
# 绘制混合信号
plt.subplot(2, 2, 3)
plt.plot(mixed_signals[:, 0], label='Mixed Signal 1')
plt.title('Mixed Signal 1')
plt.subplot(2, 2, 4)
plt.plot(mixed_signals[:, 1], label='Mixed Signal 2')
plt.title('Mixed Signal 2')
plt.tight_layout()
# 绘制恢复信号
plt.figure(figsize=(12, 6))
plt.subplot(2, 1, 1)
plt.plot(recovered_signals[:, 0], label='Recovered Signal 1')
plt.title('Recovered Signal 1')
plt.subplot(2, 1, 2)
plt.plot(recovered_signals[:, 1], label='Recovered Signal 2')
plt.title('Recovered Signal 2')
plt.tight_layout()
plt.show()
在图形中,可以看到原始信号、混合信号以及通过ICA恢复的信号。恢复信号应该与原始信号尽可能接近,这就是ICA的目标。通过独立成分分析,我们可以从混合信号中分离出原始信号,实现了信号的盲源分离。
示例演示了独立成分分析的用途,如何准备数据,训练模型以及通过图形可视化来理解分离效果。在实际应用中,你可以使用不同数量的混合信号和独立成分来执行ICA,以满足具体的应用需求。
高斯混合模型
高斯混合模型是一种用于建模多个高斯分布混合在一起的概率模型。
下面是一个关于高斯混合模型的完整示例,包括数据准备、模型训练、Python代码和图形展示等等。
数据准备
首先,我们需要准备一个包含多个高斯分布的虚拟数据集。
例子中,创建一个包含两个高斯分布的数据集。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.mixture import GaussianMixture
# 创建两个高斯分布的虚拟数据集
np.random.seed(0)
data1 = np.random.normal(0, 1, 200)
data2 = np.random.normal(5, 1, 200)
data = np.concatenate((data1, data2), axis=0)
# 绘制数据分布
plt.hist(data, bins=30, density=True, alpha=0.5)
plt.title('Data Distribution')
plt.xlabel('Value')
plt.ylabel('Density')
plt.show()
GMM模型训练
接下来,我们将使用Scikit-Learn中的GaussianMixture来拟合GMM模型,以对数据进行建模。
# 使用GMM拟合数据
gmm = GaussianMixture(n_components=2, random_state=0)
gmm.fit(data.reshape(-1, 1))
绘制GMM模型的图形
我们可以绘制GMM模型对数据的拟合情况,以及估计的高斯分布参数。
# 绘制数据分布
plt.hist(data, bins=30, density=True, alpha=0.5, label='Data')
# 绘制GMM模型的拟合曲线
x = np.linspace(-3, 8, 1000)
pdf = np.exp(gmm.score_samples(x.reshape(-1, 1)))
plt.plot(x, pdf, '-r', label='GMM')
# 绘制每个高斯分布的拟合曲线
for i in range(2):
mean = gmm.means_[i][0]
variance = np.sqrt(gmm.covariances_[i][0][0])
weight = gmm.weights_[i]
plt.plot(x, weight * np.exp(-(x - mean)**2 / (2 * variance**2)) / (np.sqrt(2 * np.pi) * variance),
label=f'Component {i+1}')
plt.title('Gaussian Mixture Model Fit')
plt.xlabel('Value')
plt.ylabel('Density')
plt.legend()
plt.show()
在图中,你可以看到原始数据的分布(直方图),以及GMM模型的拟合曲线。GMM模型通过多个高斯分布的线性组合来拟合数据分布,图中还显示了每个高斯分布的拟合曲线,包括均值、方差和权重。
这个示例演示了如何使用高斯混合模型来对数据进行建模和拟合,以及如何通过图形可视化来理解模型的效果。在实际应用中,你可以根据数据的特性和需求选择不同数量的高斯分布成分来建立更复杂的模型。