SVM的由来和概念



间隔最大化是找最近的那个点的距离’
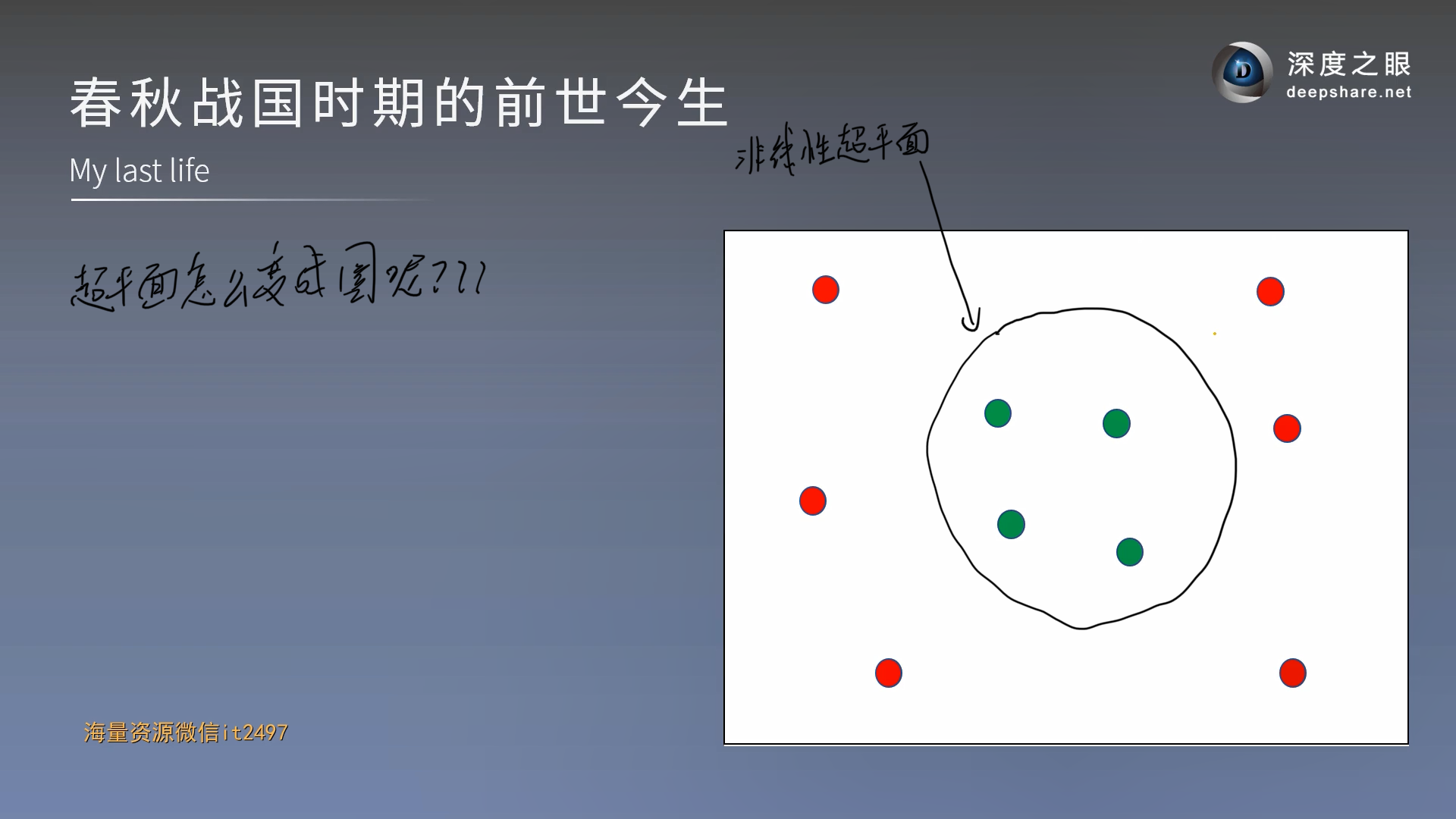
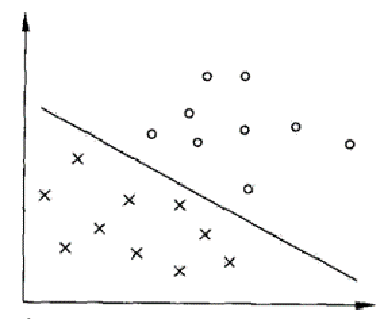
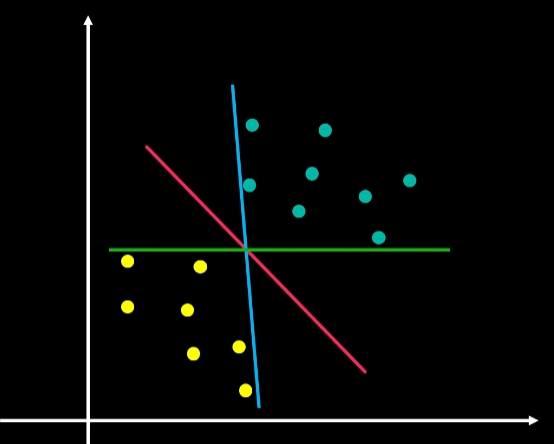
之前我们学习的都是线性超平面,现在我们要将超平面变成圈

对于非线性问题升维来解决
 对于下图很难处理,我们可以将棍子立起来,然后说不定red跑到左边了,green跑到右边了(可能增加了某种筛选条件导致两个豆子分离)(只是一种比喻)
对于下图很难处理,我们可以将棍子立起来,然后说不定red跑到左边了,green跑到右边了(可能增加了某种筛选条件导致两个豆子分离)(只是一种比喻)
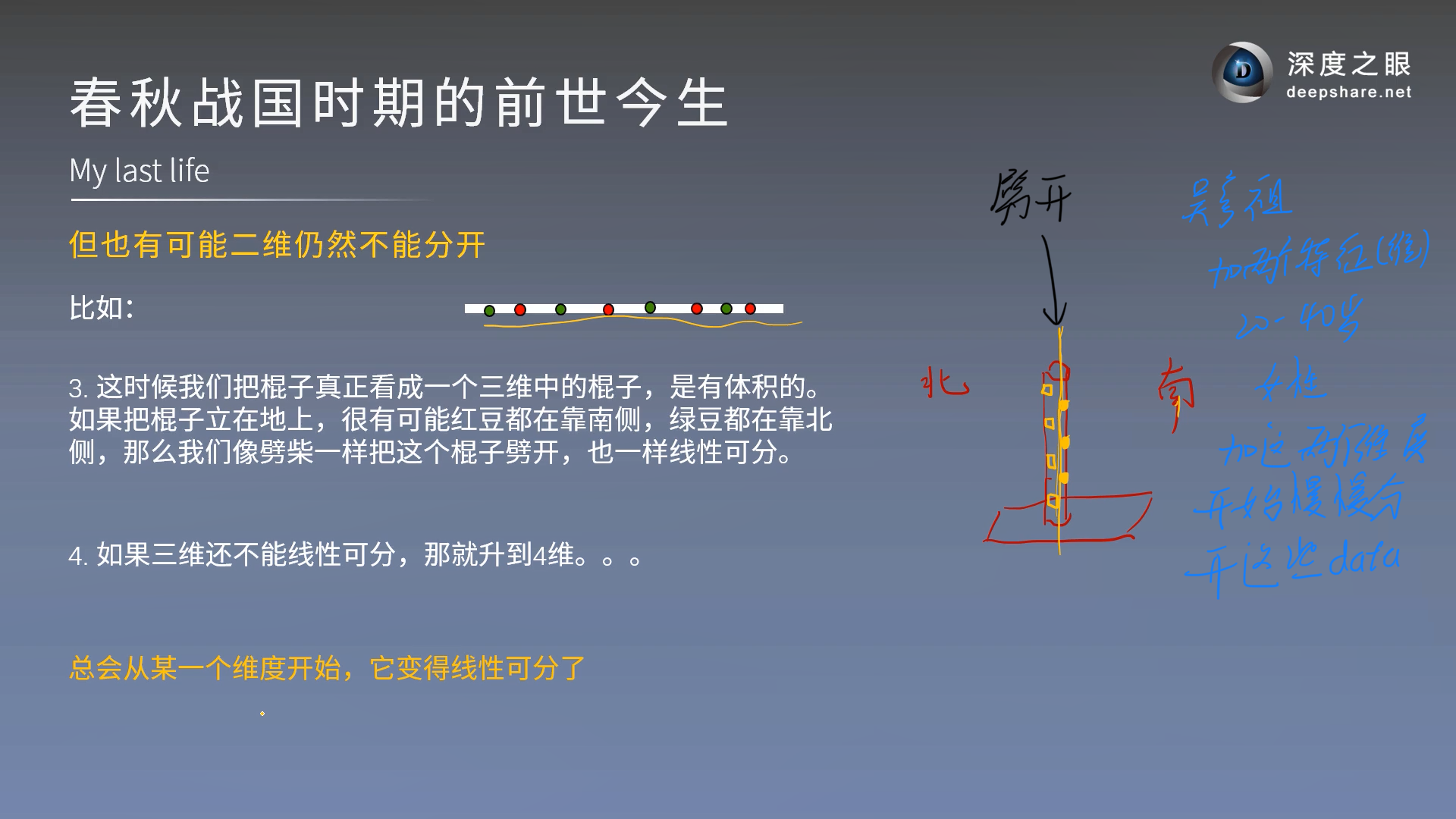
打个比方,要把刀哥和吴彦祖分开,豆子代表人们,加上几个特征(维度)1.20-40岁 2.女性 就可以大致将人们分的差不多了,可以继续加特征(维度)来使其更加分离
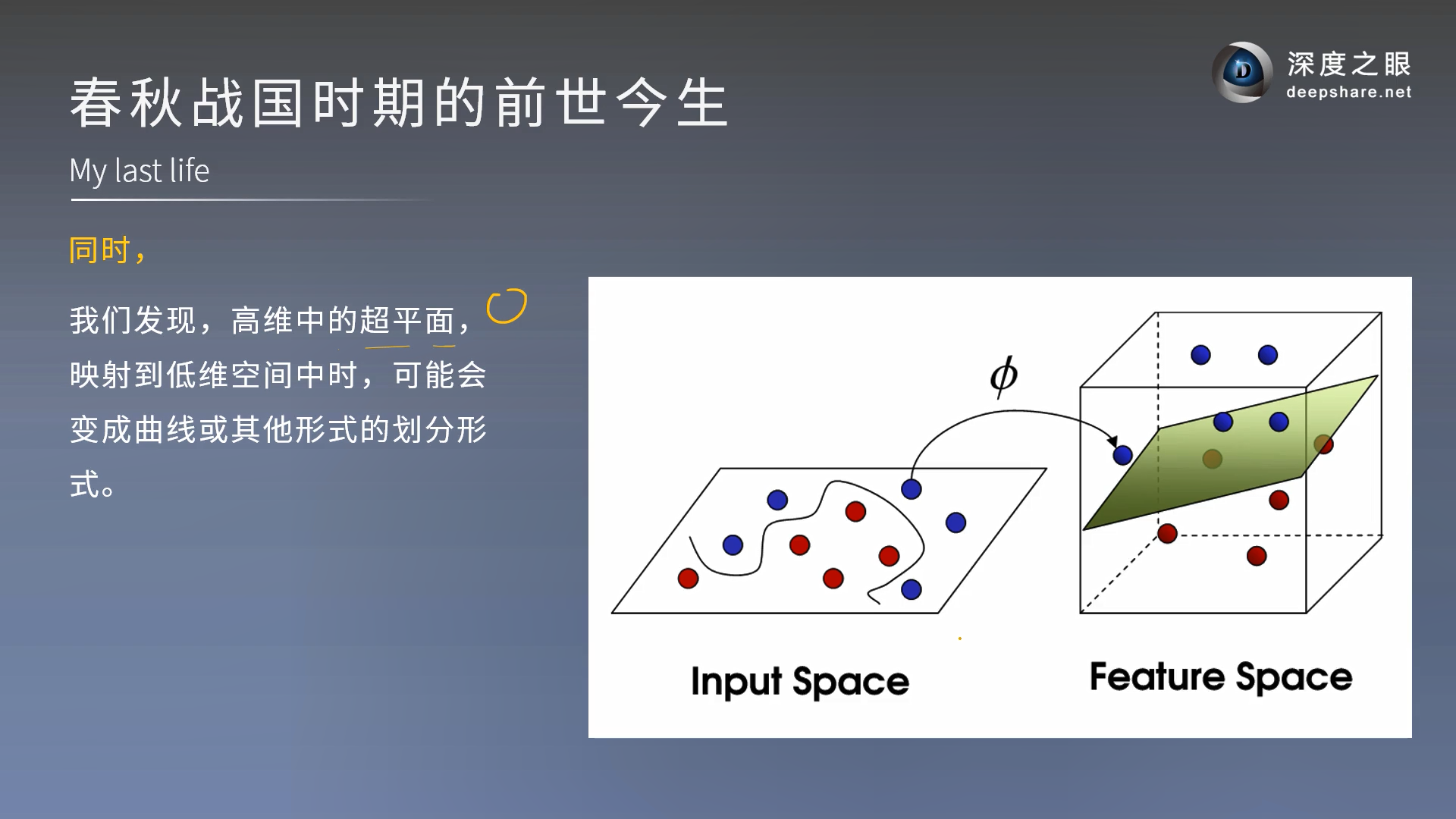

SVM本质还是非线性的,只是为了更好理解所以我们说在更高维是线性的


已经分开了,在再加特征(维度),相当于如虎添翼

复习函数间隔和几何间隔
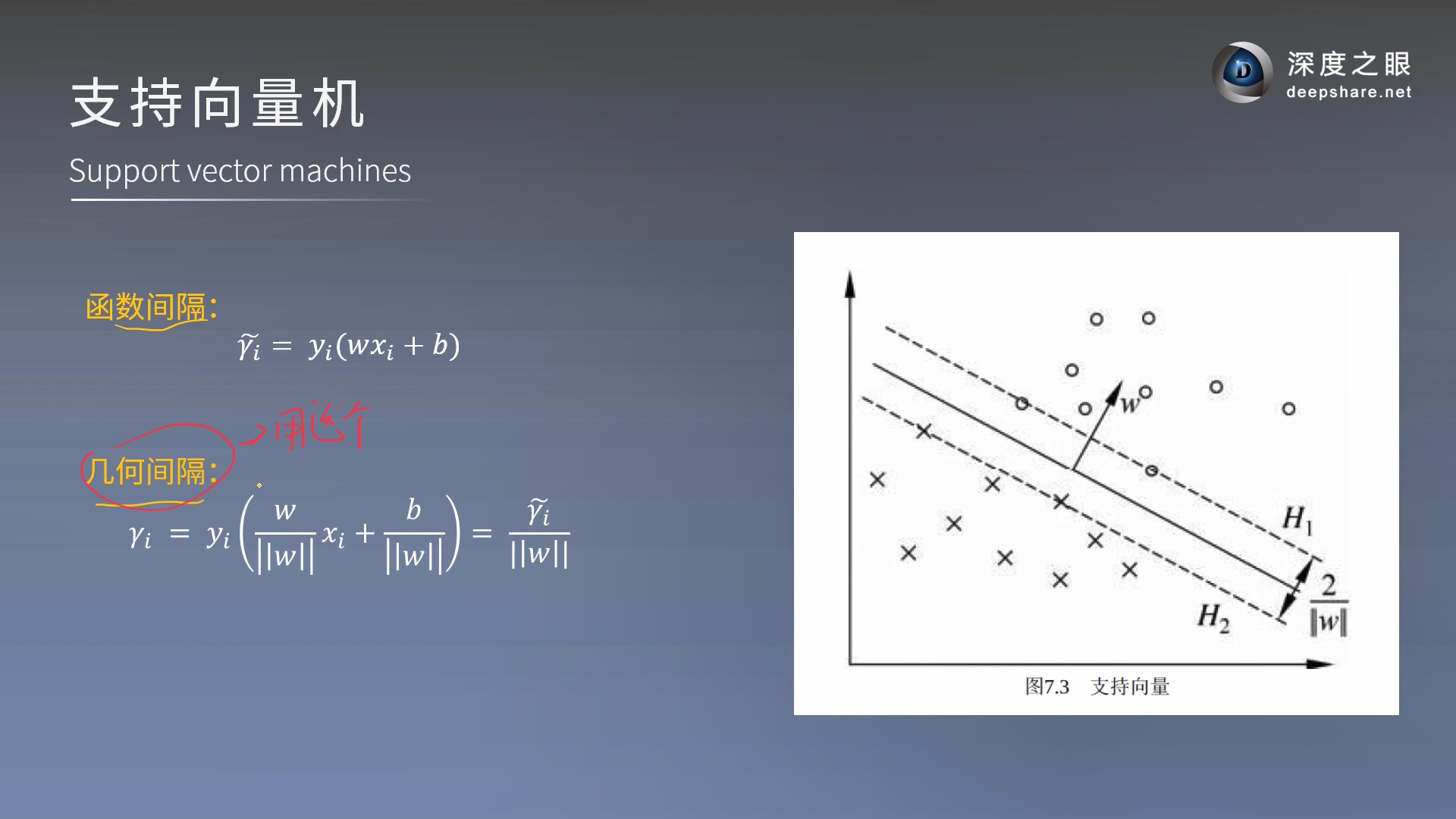
pure线性分类器

γ \gamma γ指的是几何间隔,是不会变的间隔, γ ′ \gamma^{'} γ′是函数间隔,是可变的间隔,所以我们通过变换将要求的几何间隔变为求函数间隔 γ ′ \gamma^{'} γ′,然后函数间隔可以等比例放大缩小,所以可以将其等比例放大缩小为1
对于 γ ′ \gamma^{'} γ′和 γ \gamma γ指的是间隔最大化的距离(也就是说某一个点)

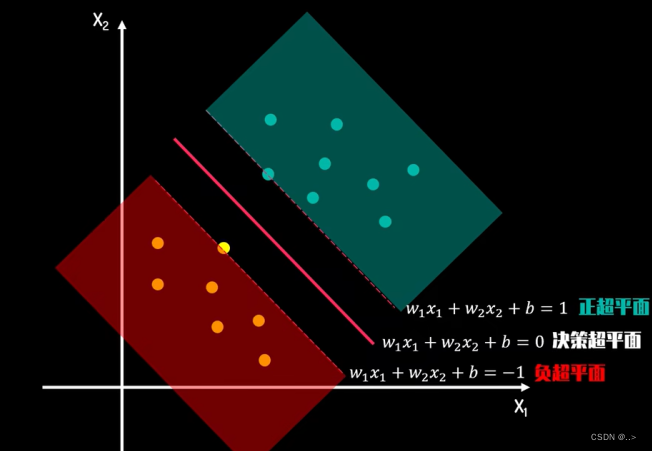
此时此刻我们将函数间隔等比例放大缩小为了1,所以是求max 1 ∣ ∣ w ∣ ∣ \frac{1}{||w||} ∣∣w∣∣1,条件就是 s . t y i ( w T x i + b ) ≥ 1 ( i = 1 , 2 , . . . m ) \;\; s.t \;\; y_i(w^Tx_i + b) \geq 1 (i =1,2,...m) s.tyi(wTxi+b)≥1(i=1,2,...m),要求那个最大值,我们可以等价转换求 m i n 1 2 ∣ ∣ w ∣ ∣ 2 2 min \;\; \frac{1}{2}||w||_2^2 min21∣∣w∣∣22(高数拉格朗日的原理不能忘记)
下面列拉格朗日乘子法列的式子
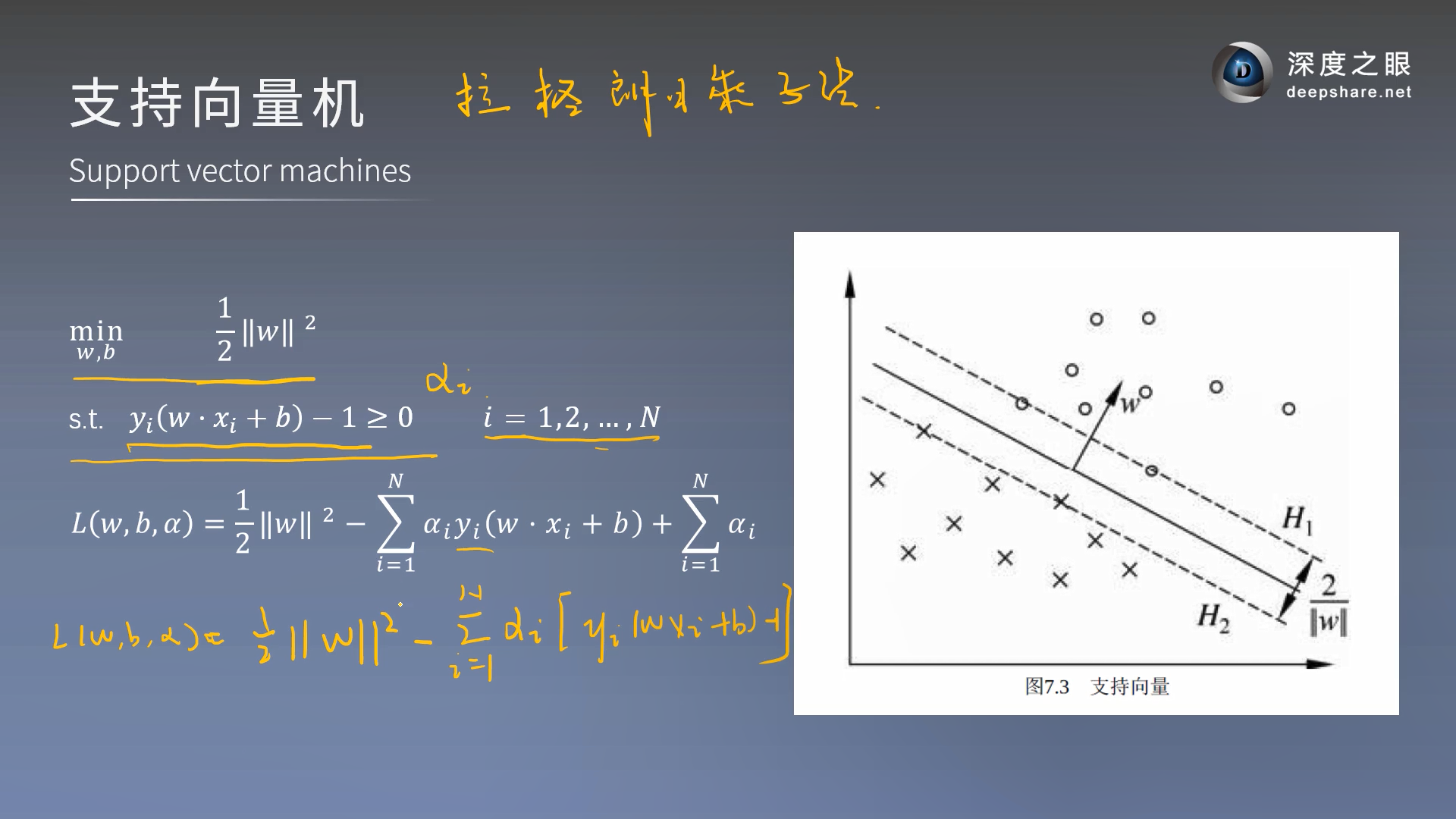
α i \alpha_i αi就是拉格朗日乘子法里面设的未知数
转换为求这个的对偶问题(后面的有些操作和最大熵式子的推导及其类似)]

分别对w和b求导得到上面两个式子,将这两个式子带入 L ( w , b , α ) L(w,b,\alpha) L(w,b,α)
化简过程如下

dodo老师的化简过程

m a x ⏟ α i ≥ 0 m i n ⏟ w , b L ( w , b , α ) \underbrace{max}_{\alpha_i \geq 0} \;\underbrace{min}_{w,b}\; L(w,b,\alpha) αi≥0 maxw,b minL(w,b,α)
求完了第一层的min接下来求第二层的max,求这个最大值


第二层的max的求法暂且不表,后面有方法来求
软间隔线性分类器

给入松弛变量,允许小部分进入边界(小部分误差)

当然,松弛变量不能白加,这是有成本的,每一个松弛变量 ξ i \xi_i ξi, 对应了一个代价 ξ i \xi_i ξi,这个就得到了我们的软间隔最大化的SVM学习条件如下:
m i n 1 2 ∣ ∣ w ∣ ∣ 2 2 + C ∑ i = 1 m ξ i min\;\; \frac{1}{2}||w||_2^2 +C\sum\limits_{i=1}^{m}\xi_i min21∣∣w∣∣22+Ci=1∑mξi
s . t . y i ( w T x i + b ) ≥ 1 − ξ i ( i = 1 , 2 , . . . m ) s.t. \;\; y_i(w^Tx_i + b) \geq 1 - \xi_i \;\;(i =1,2,...m) s.t.yi(wTxi+b)≥1−ξi(i=1,2,...m)
ξ i ≥ 0 ( i = 1 , 2 , . . . m ) \xi_i \geq 0 \;\;(i =1,2,...m) ξi≥0(i=1,2,...m)
这里,C>0为惩罚参数,可以理解为我们一般回归和分类问题正则化时候的参数。C越大,对误分类的惩罚越大,C越小,对误分类的惩罚越小。
也就是说,我们希望 1 2 ∣ ∣ w ∣ ∣ 2 2 \frac{1}{2}||w||_2^2 21∣∣w∣∣22尽量小,误分类的点尽可能的少。C是协调两者关系的正则化惩罚系数。在实际应用中,需要调参来选择。
我们要求这个几何间隔的最大值和前面pure线性分类器类似
L ( w , b , ξ , α , μ ) = 1 2 ∣ ∣ w ∣ ∣ 2 2 + C ∑ i = 1 m ξ i − ∑ i = 1 m α i [ y i ( w T x i + b ) − 1 + ξ i ] − ∑ i = 1 m μ i ξ i L(w,b,\xi,\alpha,\mu) = \frac{1}{2}||w||_2^2 +C\sum\limits_{i=1}^{m}\xi_i - \sum\limits_{i=1}^{m}\alpha_i[y_i(w^Tx_i + b) - 1 + \xi_i] - \sum\limits_{i=1}^{m}\mu_i\xi_i L(w,b,ξ,α,μ)=21∣∣w∣∣22+Ci=1∑mξi−i=1∑mαi[yi(wTxi+b)−1+ξi]−i=1∑mμiξi
其中 μ i ≥ 0 , α i ≥ 0 \mu_i \geq 0, \alpha_i \geq 0 μi≥0,αi≥0,均为拉格朗日系数。
也就是说,我们现在要优化的目标函数是:
m i n ⏟ w , b , ξ m a x ⏟ α i ≥ 0 , μ i ≥ 0 , L ( w , b , α , ξ , μ ) \underbrace{min}_{w,b,\xi}\; \underbrace{max}_{\alpha_i \geq 0, \mu_i \geq 0,} L(w,b,\alpha, \xi,\mu) w,b,ξ minαi≥0,μi≥0, maxL(w,b,α,ξ,μ)
这个优化目标也满足KKT条件,也就是说,我们可以通过拉格朗日对偶将我们的优化问题转化为等价的对偶问题来求解如下:
m a x ⏟ α i ≥ 0 , μ i ≥ 0 , m i n ⏟ w , b , ξ L ( w , b , α , ξ , μ ) \underbrace{max}_{\alpha_i \geq 0, \mu_i \geq 0,} \; \underbrace{min}_{w,b,\xi}\; L(w,b,\alpha, \xi,\mu) αi≥0,μi≥0, maxw,b,ξ minL(w,b,α,ξ,μ)
我们可以先求优化函数对于w,b的极小值, 接着再求拉格朗日乘子α和 μ的极大值。
首先我们来求优化函数对于w,b,ξ的极小值,这个可以通过求偏导数求得:
∂ L ∂ w = 0 ⇒ w = ∑ i = 1 m α i y i x i \frac{\partial L}{\partial w} = 0 \;\Rightarrow w = \sum\limits_{i=1}^{m}\alpha_iy_ix_i ∂w∂L=0⇒w=i=1∑mαiyixi
∂ L ∂ b = 0 ⇒ ∑ i = 1 m α i y i = 0 \frac{\partial L}{\partial b} = 0 \;\Rightarrow \sum\limits_{i=1}^{m}\alpha_iy_i = 0 ∂b∂L=0⇒i=1∑mαiyi=0
∂ L ∂ ξ = 0 ⇒ C − α i − μ i = 0 \frac{\partial L}{\partial \xi} = 0 \;\Rightarrow C- \alpha_i - \mu_i = 0 ∂ξ∂L=0⇒C−αi−μi=0
然后利用这个式子消除w和b
L ( w , b , ξ , α , μ ) = 1 2 ∣ ∣ w ∣ ∣ 2 2 + C ∑ i = 1 m ξ i − ∑ i = 1 m α i [ y i ( w T x i + b ) − 1 + ξ i ] − ∑ i = 1 m μ i ξ i = 1 2 ∣ ∣ w ∣ ∣ 2 2 − ∑ i = 1 m α i [ y i ( w T x i + b ) − 1 + ξ i ] + ∑ i = 1 m α i ξ i = 1 2 ∣ ∣ w ∣ ∣ 2 2 − ∑ i = 1 m α i [ y i ( w T x i + b ) − 1 ] = 1 2 w T w − ∑ i = 1 m α i y i w T x i − ∑ i = 1 m α i y i b + ∑ i = 1 m α i = 1 2 w T ∑ i = 1 m α i y i x i − ∑ i = 1 m α i y i w T x i − ∑ i = 1 m α i y i b + ∑ i = 1 m α i = 1 2 w T ∑ i = 1 m α i y i x i − w T ∑ i = 1 m α i y i x i − ∑ i = 1 m α i y i b + ∑ i = 1 m α i = − 1 2 w T ∑ i = 1 m α i y i x i − ∑ i = 1 m α i y i b + ∑ i = 1 m α i = − 1 2 w T ∑ i = 1 m α i y i x i − b ∑ i = 1 m α i y i + ∑ i = 1 m α i = − 1 2 ( ∑ i = 1 m α i y i x i ) T ( ∑ i = 1 m α i y i x i ) − b ∑ i = 1 m α i y i + ∑ i = 1 m α i = − 1 2 ∑ i = 1 m α i y i x i T ∑ i = 1 m α i y i x i − b ∑ i = 1 m α i y i + ∑ i = 1 m α i = − 1 2 ∑ i = 1 m α i y i x i T ∑ i = 1 m α i y i x i + ∑ i = 1 m α i = − 1 2 ∑ i = 1 , j = 1 m α i y i x i T α j y j x j + ∑ i = 1 m α i = ∑ i = 1 m α i − 1 2 ∑ i = 1 , j = 1 m α i α j y i y j x i T x j \begin{align} L(w,b,\xi,\alpha,\mu) & = \frac{1}{2}||w||_2^2 +C\sum\limits_{i=1}^{m}\xi_i - \sum\limits_{i=1}^{m}\alpha_i[y_i(w^Tx_i + b) - 1 + \xi_i] - \sum\limits_{i=1}^{m}\mu_i\xi_i \\&= \frac{1}{2}||w||_2^2 - \sum\limits_{i=1}^{m}\alpha_i[y_i(w^Tx_i + b) - 1 + \xi_i] + \sum\limits_{i=1}^{m}\alpha_i\xi_i \\& = \frac{1}{2}||w||_2^2 - \sum\limits_{i=1}^{m}\alpha_i[y_i(w^Tx_i + b) - 1] \\& = \frac{1}{2}w^Tw-\sum\limits_{i=1}^{m}\alpha_iy_iw^Tx_i - \sum\limits_{i=1}^{m}\alpha_iy_ib + \sum\limits_{i=1}^{m}\alpha_i \\& = \frac{1}{2}w^T\sum\limits_{i=1}^{m}\alpha_iy_ix_i -\sum\limits_{i=1}^{m}\alpha_iy_iw^Tx_i - \sum\limits_{i=1}^{m}\alpha_iy_ib + \sum\limits_{i=1}^{m}\alpha_i \\& = \frac{1}{2}w^T\sum\limits_{i=1}^{m}\alpha_iy_ix_i - w^T\sum\limits_{i=1}^{m}\alpha_iy_ix_i - \sum\limits_{i=1}^{m}\alpha_iy_ib + \sum\limits_{i=1}^{m}\alpha_i \\& = - \frac{1}{2}w^T\sum\limits_{i=1}^{m}\alpha_iy_ix_i - \sum\limits_{i=1}^{m}\alpha_iy_ib + \sum\limits_{i=1}^{m}\alpha_i \\& = - \frac{1}{2}w^T\sum\limits_{i=1}^{m}\alpha_iy_ix_i - b\sum\limits_{i=1}^{m}\alpha_iy_i + \sum\limits_{i=1}^{m}\alpha_i \\& = -\frac{1}{2}(\sum\limits_{i=1}^{m}\alpha_iy_ix_i)^T(\sum\limits_{i=1}^{m}\alpha_iy_ix_i) - b\sum\limits_{i=1}^{m}\alpha_iy_i + \sum\limits_{i=1}^{m}\alpha_i \\& = -\frac{1}{2}\sum\limits_{i=1}^{m}\alpha_iy_ix_i^T\sum\limits_{i=1}^{m}\alpha_iy_ix_i - b\sum\limits_{i=1}^{m}\alpha_iy_i + \sum\limits_{i=1}^{m}\alpha_i \\& = -\frac{1}{2}\sum\limits_{i=1}^{m}\alpha_iy_ix_i^T\sum\limits_{i=1}^{m}\alpha_iy_ix_i + \sum\limits_{i=1}^{m}\alpha_i \\& = -\frac{1}{2}\sum\limits_{i=1,j=1}^{m}\alpha_iy_ix_i^T\alpha_jy_jx_j + \sum\limits_{i=1}^{m}\alpha_i \\& = \sum\limits_{i=1}^{m}\alpha_i - \frac{1}{2}\sum\limits_{i=1,j=1}^{m}\alpha_i\alpha_jy_iy_jx_i^Tx_j \end{align} L(w,b,ξ,α,μ)=21∣∣w∣∣22+Ci=1∑mξi−i=1∑mαi[yi(wTxi+b)−1+ξi]−i=1∑mμiξi =21∣∣w∣∣22−i=1∑mαi[yi(wTxi+b)−1+ξi]+i=1∑mαiξi=21∣∣w∣∣22−i=1∑mαi[yi(wTxi+b)−1]=21wTw−i=1∑mαiyiwTxi−i=1∑mαiyib+i=1∑mαi=21wTi=1∑mαiyixi−i=1∑mαiyiwTxi−i=1∑mαiyib+i=1∑mαi=21wTi=1∑mαiyixi−wTi=1∑mαiyixi−i=1∑mαiyib+i=1∑mαi=−21wTi=1∑mαiyixi−i=1∑mαiyib+i=1∑mαi=−21wTi=1∑mαiyixi−bi=1∑mαiyi+i=1∑mαi=−21(i=1∑mαiyixi)T(i=1∑mαiyixi)−bi=1∑mαiyi+i=1∑mαi=−21i=1∑mαiyixiTi=1∑mαiyixi−bi=1∑mαiyi+i=1∑mαi=−21i=1∑mαiyixiTi=1∑mαiyixi+i=1∑mαi=−21i=1,j=1∑mαiyixiTαjyjxj+i=1∑mαi=i=1∑mαi−21i=1,j=1∑mαiαjyiyjxiTxj
这个结果和pure线性分类器结果一样,唯一不一样的是约束条件
m a x ⏟ α ∑ i = 1 m α i − 1 2 ∑ i = 1 , j = 1 m α i α j y i y j x i T x j \underbrace{ max }_{\alpha} \sum\limits_{i=1}^{m}\alpha_i - \frac{1}{2}\sum\limits_{i=1,j=1}^{m}\alpha_i\alpha_jy_iy_jx_i^Tx_j α maxi=1∑mαi−21i=1,j=1∑mαiαjyiyjxiTxj
s . t . ∑ i = 1 m α i y i = 0 s.t. \; \sum\limits_{i=1}^{m}\alpha_iy_i = 0 s.t.i=1∑mαiyi=0
C − α i − μ i = 0 C- \alpha_i - \mu_i = 0 C−αi−μi=0
α i ≥ 0 ( i = 1 , 2 , . . . , m ) \alpha_i \geq 0 \;(i =1,2,...,m) αi≥0(i=1,2,...,m)
μ i ≥ 0 ( i = 1 , 2 , . . . , m ) \mu_i \geq 0 \;(i =1,2,...,m) μi≥0(i=1,2,...,m)
对于 C − α i − μ i = 0 , α i ≥ 0 , μ i ≥ 0 C- \alpha_i - \mu_i = 0 , \alpha_i \geq 0 ,\mu_i \geq 0 C−αi−μi=0,αi≥0,μi≥0这3个式子,我们可以得到 0 ≤ α i ≤ C 0 \leq \alpha_i \leq C 0≤αi≤C
m i n ⏟ α 1 2 ∑ i = 1 , j = 1 m α i α j y i y j x i T x j − ∑ i = 1 m α i \underbrace{ min }_{\alpha} \frac{1}{2}\sum\limits_{i=1,j=1}^{m}\alpha_i\alpha_jy_iy_jx_i^Tx_j - \sum\limits_{i=1}^{m}\alpha_i α min21i=1,j=1∑mαiαjyiyjxiTxj−i=1∑mαi
s . t . ∑ i = 1 m α i y i = 0 s.t. \; \sum\limits_{i=1}^{m}\alpha_iy_i = 0 s.t.i=1∑mαiyi=0\
0 ≤ α i ≤ C 0 \leq \alpha_i \leq C 0≤αi≤C和pure线性分类器比就多了这个约束条件,求 α \alpha α和pure那个一样通过SMO算法来求上式极小化时对应的α向量就可以求出w和b了。

引入核函数

这里x是向量,怎么方便求向量的点积,需要引入核函数


幂函数好使

SMO


我们假设我们通过SMO算法求得了我们得到了对应的α的值 α ∗ \alpha^{*} α∗。
那么我们根据 w = ∑ i = 1 m α i y i x i w = \sum\limits_{i=1}^{m}\alpha_iy_ix_i w=i=1∑mαiyixi,可以求出对应的w的值 w ∗ = ∑ i = 1 m α i ∗ y i x i w^{*} = \sum\limits_{i=1}^{m}\alpha_i^{*}y_ix_i w∗=i=1∑mαi∗yixi
求b则稍微麻烦一点。注意到,对于任意支持向量 ( x x , y s ) (x_x, y_s) (xx,ys),都有
y s ( w T x s + b ) = y s ( ∑ i = 1 m α i y i x i T x s + b ) = 1 y_s(w^Tx_s+b) = y_s(\sum\limits_{i=1}^{m}\alpha_iy_ix_i^Tx_s+b) = 1 ys(wTxs+b)=ys(i=1∑mαiyixiTxs+b)=1(到超平面的函数距离人为设置为1)
假设我们有S个支持向量,则对应我们求出S个 b ∗ b^{*} b∗,理论上这些 b ∗ b^{*} b∗都可以作为最终的结果, 但是我们一般采用一种更健壮的办法,即求出所有支持向量所对应的 b s ∗ b_s^{*} bs∗,然后将其平均值作为最后的结果。注意到对于严格线性可分的SVM,b的值是有唯一解的(那是肯定的,因为对于二维而言,支持向量到最优超平面之间的距离是一样的都是1),也就是这里求出的所有 b ∗ b^{*} b∗都是一样的,这里我们仍然这么写是为了和后面加入软间隔后的SVM的算法描述一致。
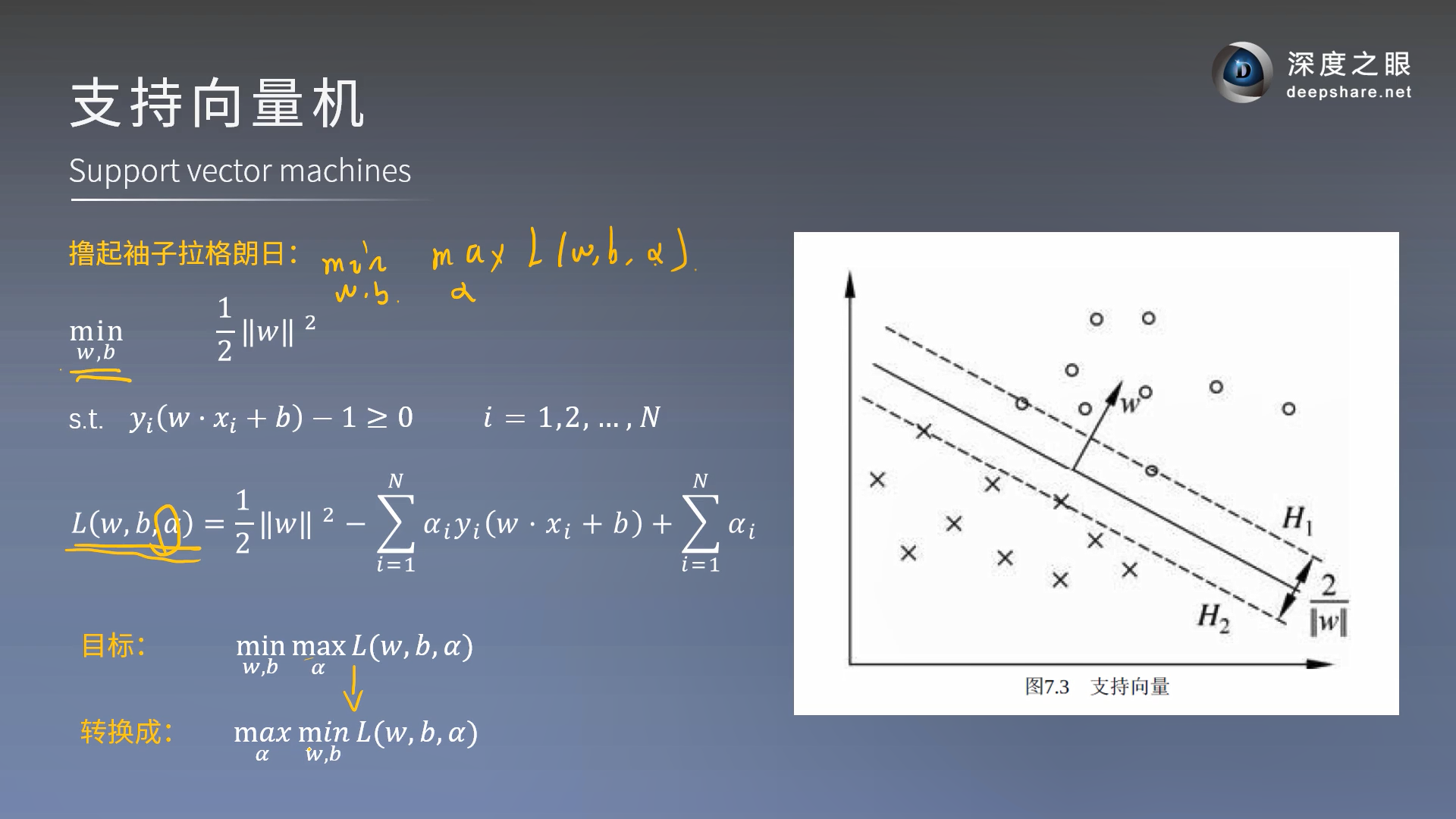
支持向量:和超平面平行的保持一定的函数距离的这两个超平面对应的向量(不是法向量),相当于A,B两点画平行线(支持向量),然后平行线之间的距离最大就是最优的超平面

(我们已经得到最优超平面的前提下,需要求支持向量)怎么得到支持向量呢?根据KKT条件中的对偶互补条件 α i ∗ ( y i ( w T x i + b ) − 1 ) = 0 \alpha_{i}^{*}(y_i(w^Tx_i + b) - 1) = 0 αi∗(yi(wTxi+b)−1)=0,如果 α i > 0 \alpha_i>0 αi>0则有 y i ( w T x i + b ) = 1 y_i(w^Tx_i + b) =1 yi(wTxi+b)=1即点在支持向量上,否则如果 α i = 0 \alpha_i=0 αi=0(无约束条件问题),则有 y i ( w T x i + b ) ≥ 1 y_i(w^Tx_i + b) \geq 1 yi(wTxi+b)≥1,即样本在支持向量上或者已经被正确分类。