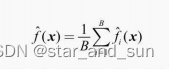🌈个人主页: 鑫宝Code
🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础
💫个人格言: "如无必要,勿增实体"

文章目录
LightGBM: 优化机器学习的高效梯度提升决策树
引言
在机器学习领域,梯度提升决策树(Gradient Boosting Decision Tree, GBDT)因其强大的预测能力和解释性而备受推崇。随着数据规模的日益增大,对模型训练速度和效率的需求也愈发迫切。在此背景下,Microsoft Research于2017年开源的LightGBM项目,凭借其高速度、高效率以及优秀的性能,在众多GBDT框架中脱颖而出,成为业界和学术界的新宠。本文将深入探讨LightGBM的核心优势、工作原理、关键特性和应用场景,旨在为读者提供一份全面而深入的理解指南。

一、LightGBM概览
诞生背景:面对传统GBDT在处理大规模数据集时遇到的内存消耗大、训练时间长等问题,LightGBM应运而生,它通过一系列创新算法设计显著提高了训练效率。
核心特点:
- 高效性:利用直方图近似和基于梯度的单边采样等技术,大幅减少计算量。
- 低内存消耗:通过叶子权重直方图存储方式,极大降低了内存使用。
- 高并行性:支持特征并行、数据并行和投票并行等多种并行策略,加速训练过程。
- 灵活性:支持自定义目标函数和评估指标,满足多样化需求。
二、核心技术解析
1. 直方图近似(Histogram Approximation)
传统的GBDT方法在每一轮迭代中需要遍历所有数据来计算梯度,这在大数据场景下极为耗时。LightGBM引入了直方图的概念,将连续的特征值离散化为几个区间,仅需统计每个区间内的样本数量和梯度统计量,从而大大减少了计算量,加速了训练过程。
2. 基于梯度的单边采样(Gradient-Based One-Side Sampling, GOSS)
GOSS是一种有效的样本抽样策略,它根据样本的梯度大小进行有偏抽样,保留梯度较大的样本和一部分梯度较小的样本,这样既保留了重要信息,又大幅度减少了计算量,进一步提升了效率。
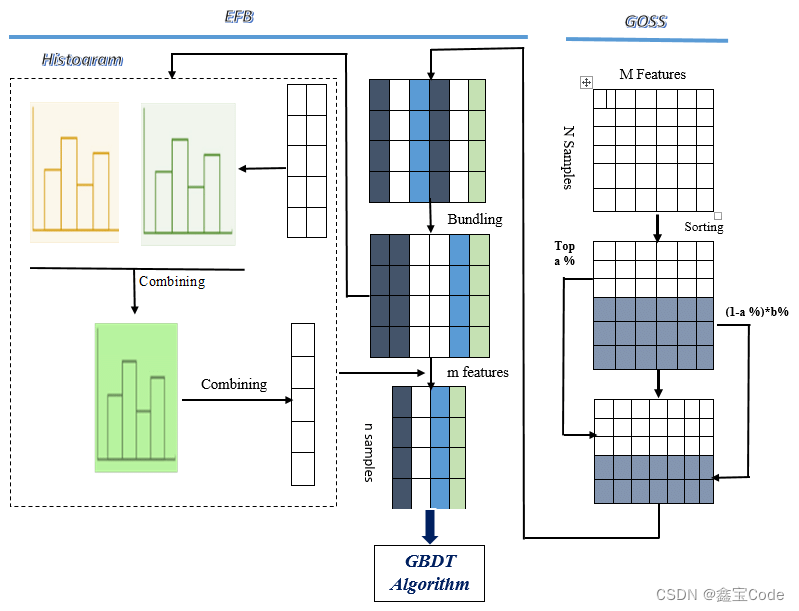
3. 特征并行与数据并行
- 特征并行:将特征分配到不同的机器上进行独立的直方图构建,然后合并这些直方图,适用于特征维度较高的情况。
- 数据并行:将数据集分割到不同机器,每台机器上分别建立自己的决策树,最后汇总决策树结果,适用于大数据集。
三、与其他GBDT实现的对比
与XGBoost相比,LightGBM在训练速度和内存使用上通常表现更优,特别是在数据量较大时。然而,XGBoost提供了更多的调参选项,对于高度定制化的任务可能更为灵活。两者各有千秋,选择应依据具体任务需求。
四、实践应用与调参技巧
应用领域:LightGBM广泛应用于推荐系统、搜索引擎排名、金融风控、医疗诊断等多个领域,以其高效、准确的特性解决了一系列实际问题。
调参建议:
- 学习率:初始值可设为0.1,过拟合时减小。
- 树的最大深度:默认31,可根据数据复杂度调整。
- 叶子节点最小样本数:控制模型复杂度,避免过拟合。
- 特征抽样比例:通过调整
feature_fraction参数平衡模型复杂度与性能。
以下是一个使用Python和LightGBM库进行分类任务的基本示例代码。这个例子中,我们将使用经典的鸢尾花(Iris)数据集来训练一个简单的LightGBM模型,并进行基本的模型评估。代码仅供参考🐶
# 导入所需库
import lightgbm as lgb
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
# 加载数据
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 转换数据格式为LightGBM所需的类型
lgb_train = lgb.Dataset(X_train, label=y_train)
lgb_eval = lgb.Dataset(X_test, label=y_test, reference=lgb_train)
# 设置参数
params = {
'boosting_type': 'gbdt',
'objective': 'multiclass',
'num_class': 3, # 因为鸢尾花数据集有3个类别
'metric': 'multi_logloss',
'num_leaves': 31,
'learning_rate': 0.1,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'verbose': 0
}
# 训练模型
gbm = lgb.train(params,
lgb_train,
num_boost_round=20, # 可以根据需要调整迭代轮数
valid_sets=lgb_eval,
early_stopping_rounds=5)
# 预测
y_pred = gbm.predict(X_test)
y_pred_class = y_pred.argmax(axis=1) # 将概率转换为类别
# 评估
accuracy = accuracy_score(y_test, y_pred_class)
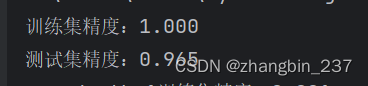
print("Accuracy:", accuracy)
print("\nClassification Report:\n", classification_report(y_test, y_pred_class))
这段代码首先导入必要的库和数据集,然后划分训练集和测试集。接着,它将数据转换为LightGBM可以处理的格式,并定义了模型的参数。之后,模型通过训练数据进行训练,并在测试集上进行预测。最后,我们计算并打印出模型的准确率和分类报告,以便评估模型的表现。
五、结论
LightGBM作为GBDT家族中的佼佼者,凭借其高效的算法设计和优异的性能表现,成为了现代机器学习领域不可或缺的工具之一。无论是处理大规模数据集,还是追求模型训练速度与资源效率的平衡,LightGBM都展现出了强大的竞争力。随着算法的持续优化和社区的不断贡献,我们有理由相信,LightGBM将在未来机器学习的探索之路上扮演更加重要的角色。