目录
1.初识DataFrame
(1)昨天,我们学习了Series。而Pandas的另一种数据类型:DataFrame,在许多特性上和Series有相似之处。
(2)顾名思义,这个就是一个数据框,用来存储这个二维数组的相关的信息,通过行和列可以找到对应的位置的元素,这个是pandas模块里面经常使用的一种数据结构,下面的就是一个基本的数据框;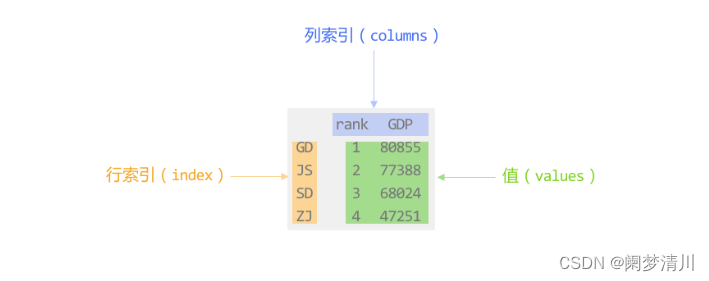
显然,这个框有三个部分组成,一个就是行索引,一个就是列索引,还有一个就是这个框里面的数值;
(3)那么这个数据框和我们之前介绍的这个序列Series有什么区别呢,这个区别肯定是有的:
通过下面的这个结构我们也是可以看出来,两个Seriss序列合并成为了一个数据框,这个就表明了这个数据框就是很多个序列对象的集合,这里只是展示出来了两个,其实可以有更多个序列的,可以看见这些序列的行索引都是一样的,但是列索引是不一样的,合并起来之后可以共用行索引,列索引单独表示;
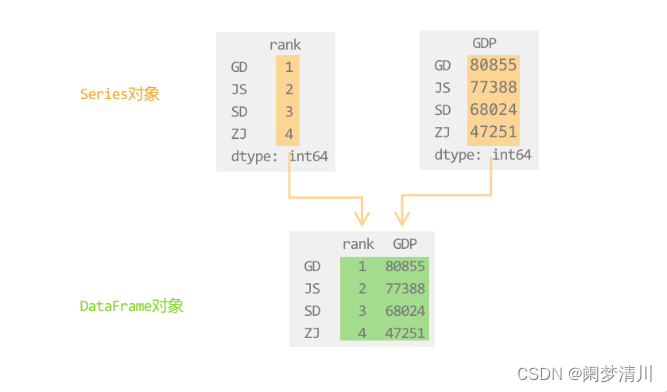
和这个序列相似,在没有这个特殊说明的情况下面,这个索引就是从0开始排列生成的;
2.DataFrame的构造函数
(1) 其实这个构造函数的形式,以及这个函数的参数都适合昨天的序列的构造函数没有太大的区别,只不过是这个传递进来的data是一个字典,形式不一样而已;
# 导入pandas模块,简称pd
import pandas as pd
# 定义一个字典data
data = {'name': ['May','Tony','Kevin'], 'score':[689,659,635]}
# 定义一个列表rank
rank = [1,2,3]
# TODO 使用pd.DataFrame()函数,传入参数:字典data作为value和columns,列表rank作为index
# 构造出的DataFrame赋值给result
result = pd.DataFrame(data,index = rank)
# 输出result这个DataFrame
print(result)(2)除了上面的方式之外,我们还可以自己带上索引:
通过比较我们就可以发现,这个就是data没有指定列索引,但是在构造函数的参数里面,我们指明了这个列索引,我们上面的那个传递进来的就是键值对的字典,现在传进来的就是一个嵌套的列表
# 导入pandas模块,简称pd
import pandas as pd
# 定义一个嵌套列表data
data = [['May',689],['Tony',659],['Kevin',635]]
# 定义一个列表rank
rank = [1,2,3]
# TODO 使用pd.DataFrame()函数,嵌套列表data和列表rank作为参数传入,并且使用参数columns自定义列索引columns:
# 构造出的DataFrame赋值给result
result=pd.DataFrame(data,index=rank,columns=['name','score'])
# 输出result这个DataFrame
print(result)3.数据框的轴
(1)这个轴就是针对于超过一维的数组而定义的属性;

举一个例子,如果我们想要进行这个求和,使用axis=0就是对于列进行求和,axis=1就是对于行进行求和; 理解即可;
4.CSV文件读取
(1)我们平常经常使用的文件就是CSV文件和Excel文件,但是鉴于这个dataframe里面有很多这个数据处理的相关的方法,pandas会把这个数据转化为这个dataframe对象,方便我们后续进行这个数据处理的相关的工作;
(2)读取CSV文件
CSV就是使用纯文本的方式去储存这个数字,文本等表格数据,他的每一列的内容数据的类型是一样的;
读取这个CSV文件使用的函数就是对应的pd.read_csv()函数,这个函数需要我们传递的参数就是我们想要处理的文件的路径,windows操作系统下面需要在这个路径前面添加r,表示不需要进行转义,最后这个文件里面的内容就会以dataframe的形式打印出来;
(3)pd.read_csv()函数的可选参数
就是我们平常处理的这个文件并不像上面介绍的那么理想,可能并不是我们传递进去这个路径之后就可以得到我们想要的数据,这个时候我们就需要了解这个函数的可选参数,这个可选参数对应不同的场景下面帮助我们去得到我们想要的数据;
&&防止文件乱码
在这个参数的里面添加上,encoding="utf-8"
//导入模块
import pandas as pd
//调用这个数据处理的函数,第一个参数就是文件的路径,第二个就是编码类型
data = pd.read_csv(r"/Users/***.csv",encoding="utf-8")&&指定索引
就是我们在默认情况下面就是使用的就是从0开始的这个索引,如果我们想要这个索引变的更有意义,这个时候我们就可以通过第二个参数index_col进行指定索引;
# 导入pandas模块,并以"pd"为该模块的简写
import pandas as pd
# TODO 使用pd.read_csv()函数读取路径为 "/Users/yequ/电商数据清洗.csv" 的CSV文件
# 并通过参数index_col来指定"order_id"列为index
# 将结果赋值给变量data
data=pd.read_csv("/Users/yequ/电商数据清洗.csv",index_col="order_id")
# 使用print()输出变量data
print(data)&&读取指定的列
虚设一个场景就是我们想要知道这个超市里面的这个商品单个平均利润,我们只需要用这个总的收入除以这个商品的数量即可,这个时候其他的数据没有必要进行读取,这个时候我们就可以使用第二个指定列的参数就可以解决这个问题,usecols是不可以改变的;
# 导入pandas模块,并以"pd"为该模块的简写
import pandas as pd
# TODO 使用pd.read_csv()函数和usecols参数
# 读取路径为 "/Users/yequ/电商数据清洗.csv" 的CSV文件里:
# "payment"和"items_count"这两列中的数据
# 并将结果赋值给变量data
data=pd.read_csv("/Users/yequ/电商数据清洗.csv",usecols=["payment","items_count"])
# 使用print()输出变量data
print(data)&&添加columns
这个就是我们对于这个表格里面的数据进行处理的时候,如果没有表头,就会不方便读者进行阅读,因为我们不知道这一列的实际意义是什么,这个时候我们就可以添加这个columns,例如我们下面的这个案例里面添加的就是订单号,用户id,支付金额等等,这些信息可以让用户们清楚的知道某一列的数据的实际意义;
# 导入pandas模块,并以"pd"为该模块的简写
import pandas as pd
# TODO 使用pd.read_csv()函数、header参数和names参数
# 读取路径为 "/Users/yequ/order_withoutColumns.csv" 的CSV文件
# 将数据的columns设置为:"订单号","用户id","支付金额","商品价格","购买数量","支付时间"
# 将结果赋值给变量data
data=pd.read_csv("/Users/yequ/order_withoutColumns.csv",header=None,names=["订单号","用户id","支付金额","商品价格","购买数量","支付时间"])
# 使用print()输出变量data
print(data)打印的结果显示如下:

5.保存CSV文件
(1)对应的吧dataframe类型的文件保存为CSV文件,这个也是需要相对应的函数的,就是pd.to_csv()函数,这个函数的参数就是我们想要把这个文件保存到的位置,需要注意的就是如果这个位置是有文件存在的,这个时候原来的文件就会被覆盖掉;
(2)和上面的文件的读取是一样的,这个也是有可以选择的参数的,因为如果我们值传递这个想要保存到的路径,这个时候就会把这个编号写到这个表格的第一列,把原来的内容给覆盖掉,这个时候我们就可以使用可选参数
&&index=False这个可选参数加上去之后,就不会把这个索引写在第一列了
&&encoding=utf-8-sig这个可选参数可以把我们的这个可能出现的编码问题给规避掉;
5.Excel文件读取
(1)读取这个excel文件和我们上面介绍的读取csv文件基本一致,只不过需要我们安装一个工具
xlrd模块,这个模块可以同时读取xls xlsx文件;
(2)这个需要注意的就是我们使用这个pd.read_excel()函数的时候,传递进去的就也是一个路径,这个路径下面如果有多个工作表,这个时候我们的系统就会默认的读取第一个工作表,这个时候我们也可以使用excel里面的可选参数来指定读取第几个工作表;
下面的这个里面的第二行代码,我们就会指定读取名字的工作表;
# 导入pandas模块,并以"pd"为该模块的简写
import pandas as pd
# TODO 使用pd.read_excel()函数和sheet_name参数
# 读取路径为 "/Users/yequ/2019年4月销售订单.xlsx" 的Excel文件里:"销售订单数据" 这个工作表
# 并将结果赋值给变量data
data=pd.read_excel("/Users/yequ/2019年4月销售订单.xlsx",sheet_name="销售订单数据")
# 使用print()输出变量data
print(data)






















![[羊城杯 2020]easyser](https://img-blog.csdnimg.cn/direct/3611bb6f8abe4ede95db9f7debf812e3.png)