SUM(column)
用于计算指定列的总和。
示例:计算每个部门员工的总工资
SELECT department, SUM(salary) AS total_salary
FROM employees
GROUP BY department;
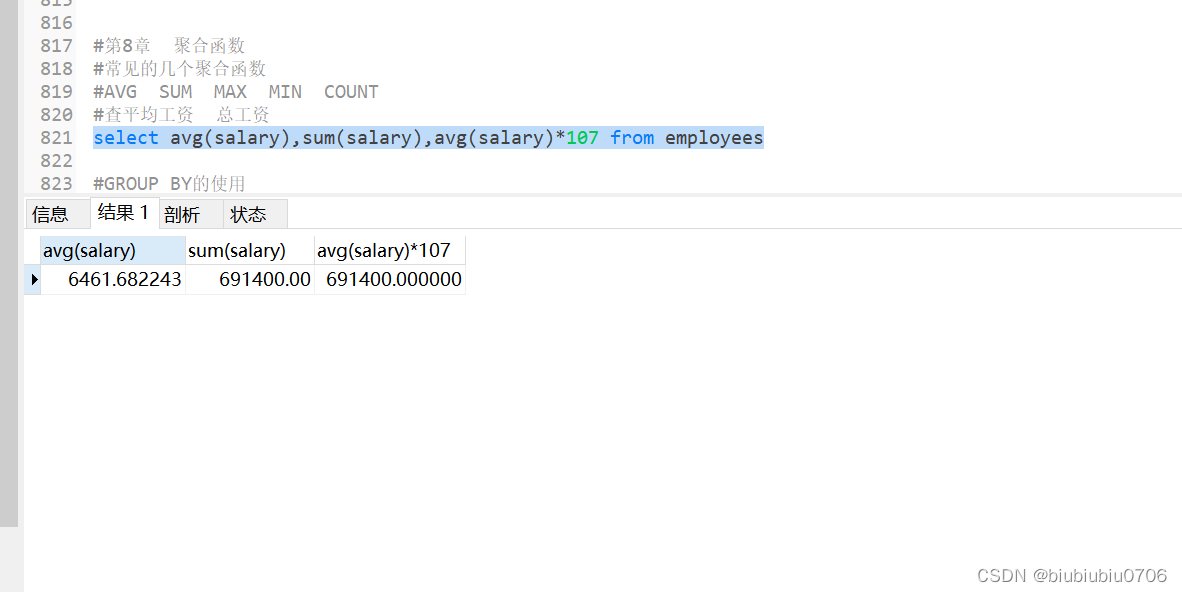
AVG(column)
用于计算指定列的平均值。
示例:计算每个部门员工的平均工资
SELECT department, AVG(salary) AS avg_salary
FROM employees
GROUP BY department;
COUNT(column)
用于统计指定列中非 NULL 值的个数。
示例:统计每个部门有多少员工
SELECT department, COUNT(employee_id) AS num_employees
FROM employees
GROUP BY department;
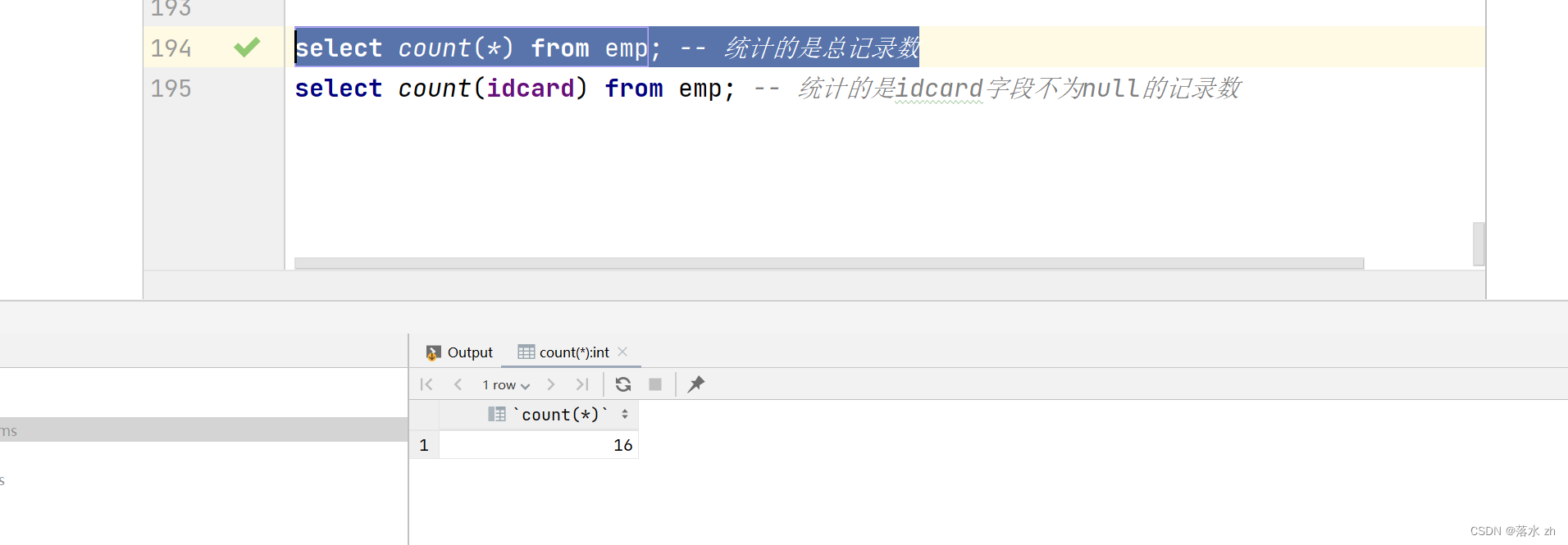
COUNT(*)
用于统计总行数。
示例:统计公司总共有多少员工
SELECT COUNT(*) AS total_employees
FROM employees;
MAX(column)
用于返回指定列中的最大值。
示例:找出每个部门工资最高的员工
SELECT e.department, e.name, e.salary
FROM employees e
INNER JOIN (
SELECT department, MAX(salary) AS max_salary
FROM employees
GROUP BY department
) t ON e.department = t.department AND e.salary = t.max_salary;
MIN(column)
用于返回指定列中的最小值。
示例:找出每个部门工资最低的员工
SELECT e.department, e.name, e.salary
FROM employees e
INNER JOIN (
SELECT department, MIN(salary) AS min_salary
FROM employees
GROUP BY department
) t ON e.department = t.department AND e.salary = t.min_salary;
GROUP_CONCAT(column):
用于将指定列中的值连接起来,形成一个字符串。
示例:列出每个部门所有员工的名字
SELECT department, GROUP_CONCAT(name) AS employees
FROM employees
GROUP BY department;
VAR_POP(column) 和 VAR_SAMP(column)
用于计算总体方差和样本方差。
示例:计算每个部门员工工资的总体方差和样本方差
SELECT
department,
VAR_POP(salary) AS population_variance,
VAR_SAMP(salary) AS sample_variance
FROM employees
GROUP BY department;
STDEV_POP(column) 和 STDEV_SAMP(column)
用于计算总体标准差和样本标准差。
示例:计算每个部门员工工资的总体标准差和样本标准差
SELECT
department,
SQRT(VAR_POP(salary)) AS population_std_dev,
SQRT(VAR_SAMP(salary)) AS sample_std_dev
FROM employees
GROUP BY department;
ROLLUP()
提供分级汇总,可以同时得到小计和总计。
示例:计算每个部门每个职位的总工资,以及每个部门的总工资和整个公司的总工资
SELECT
department,
job_title,
SUM(salary) AS total_salary
FROM employees
GROUP BY ROLLUP(department, job_title);
CUBE()
提供多维度的分组汇总。
示例:计算每个部门每个职位的总工资,以及每个部门的总工资、每个职位的总工资和整个公司的总工资
SELECT
department,
job_title,
SUM(salary) AS total_salary
FROM employees
GROUP BY CUBE(department, job_title);
窗口函数
窗口函数之所以被称为"窗口函数",是因为它们的工作方式类似于在数据集上滑动一个"窗口",并对该窗口内的行进行计算。
这里的"窗口"指的是一组行,这组行被用作计算的基础。窗口函数会为每行数据计算一个值,这个值是基于该行所在的窗口中的其他行计算得出的。
与聚合函数(如 SUM、AVG 等)不同,窗口函数不会改变返回行的数量。相反,它们会为每个输入行生成一个输出行,并在该行上添加一个计算值。
窗口函数之所以被称为"窗口"函数,是因为它们通过在数据集上滑动一个"窗口"来计算结果。这个"窗口"可以是基于某些条件(如 PARTITION BY 子句)定义的一组行,也可以是整个数据集。
在计算每个部门内员工的工资排名时,我们使用 RANK() 窗口函数。这个函数会为每个员工计算他们在所属部门内的工资排名。在计算每个员工排名时,函数会"窗口"到该员工所属的部门内的其他员工,并根据工资大小进行排序。
窗口函数主要有以下几种:
ROW_NUMBER()
为每个分组内的行记录一个顺序号,序号从 1 开始,且不会因为值的相等而重复。
RANK()
为每个分组内的行记录一个排名,如果有并列,则会留下空位。
DENSE_RANK()
为每个分组内的行记录一个排名,如果有并列,则不会留下空位。
NTILE(n)
将分组数据划分为 n 个等sized 窗格,记录每条数据所在的窗格编号。
LEAD(column, [offset], [default_value])
用于获取当前行往下偏移 offset 行的值,如果数据不存在则使用 default_value。
LAG(column, [offset], [default_value])
用于获取当前行往上偏移 offset 行的值,如果数据不存在则使用 default_value。
FIRST_VALUE(column)
返回分组内当前行之前的第一个值。
LAST_VALUE(column)
返回分组内当前行之后的最后一个值。
实例
这些窗口函数通常与 OVER 子句一起使用,用于对查询结果进行复杂的排序、分组和计算。下面是一个综合运用多个窗口函数的例子:
SELECT
department,
name,
salary,
ROW_NUMBER() OVER (PARTITION BY department ORDER BY salary DESC) AS rn,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS ranking,
DENSE_RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS dense_ranking,
LEAD(salary, 1, 0) OVER (PARTITION BY department ORDER BY salary DESC) AS next_salary,
LAG(salary, 1, 0) OVER (PARTITION BY department ORDER BY salary DESC) AS prev_salary
FROM employees;
这个查询不仅返回了每个员工的基本信息,还计算了他们在所在部门内的排名,以及与前一个和下一个员工工资的差异。窗口函数的灵活性和复杂性为数据分析提供了强大的工具。
partition 和 over
在 MySQL 中,partition 和 over 是两个相关但不同的概念:
Partition
Partition 是一种将表格数据逻辑上划分为多个部分的方法。
通过在 CREATE TABLE 或 ALTER TABLE 语句中指定 PARTITION BY 子句,可以基于某些列将数据划分为多个分区。
分区可以提高查询效率,因为 MySQL 只需要访问相关的分区,而不是整个表格。常见的分区方式包括按月、按年、按范围等。
示例:
CREATE TABLE sales
(
id INT,
product VARCHAR(50),
sales_date DATE
)
PARTITION BY RANGE (YEAR(sales_date))
(
PARTITION p2023 VALUES LESS THAN (2024),
PARTITION p2024 VALUES LESS THAN (2025),
PARTITION p2025 VALUES LESS THAN (2026)
);
Window Functions (OVER)
Window functions 是一类特殊的函数,可以在查询结果中的每一行上执行计算,但不会改变该行的输出。
OVER 子句用于定义窗口函数的范围,指定在哪些行上执行计算。
常见的窗口函数包括 ROW_NUMBER()、RANK()、DENSE_RANK()、SUM()、AVG() 等。
示例:
SELECT
id,
product,
sales_date,
sales_amount,
SUM(sales_amount) OVER (PARTITION BY product ORDER BY sales_date) AS cumulative_sales
FROM
sales;
在这个例子中,SUM(sales_amount) OVER (PARTITION BY product ORDER BY sales_date) 会计算每个产品的累计销售额。PARTITION BY product 指定按产品进行分组,ORDER BY sales_date 指定按销售日期排序。