一、介绍
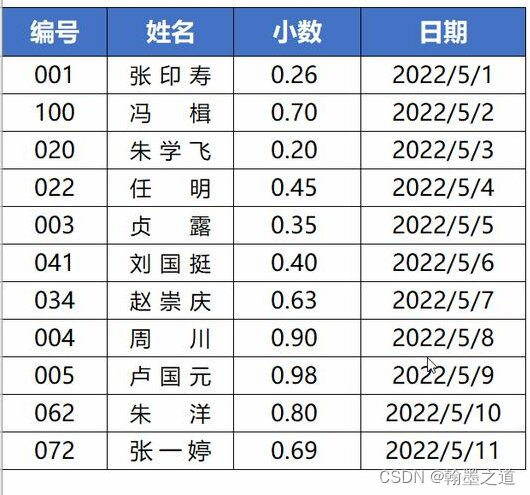
图片版的PDF文件,怎么才能借助AI工具来提取其中全部的文字内容呢?
第一步:将PDF文件转换成图片格式
具体方法参见文章:
Kimichat使用案例011:用kimichat将PDF自动批量分割成多个图片(零代码编程)
第二步:识别图片中的文字
将第一步pdf转换成的图片,上传到kimichat
二、具体操作
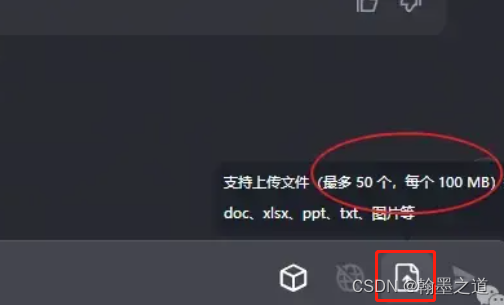
注意:kimichat目前上传图片一次最多50张图片,单个大小不超过100M
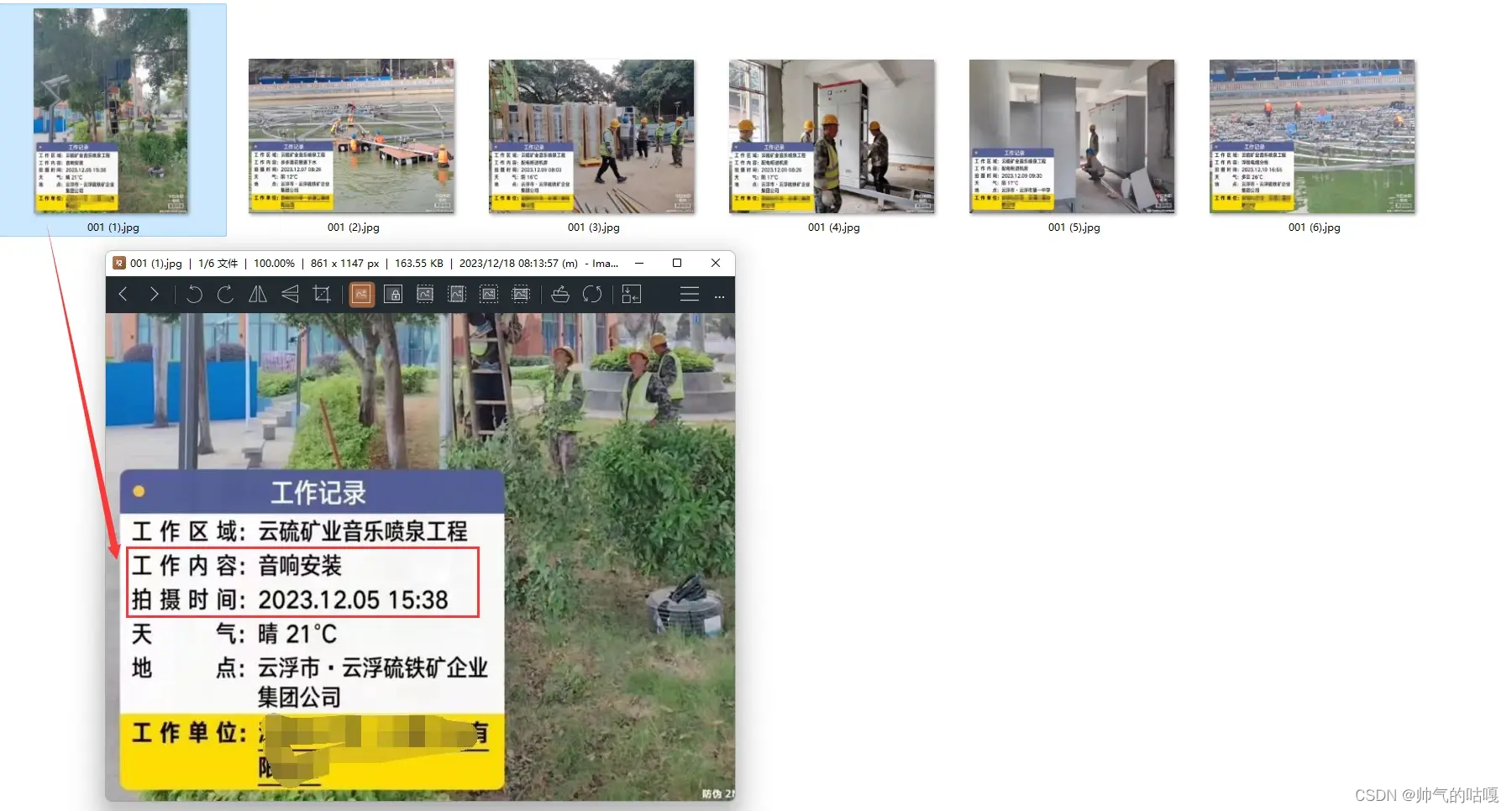
上传完成后,kimichat会进行解析。
部分图片会提示:未提取到文字或者解析失败

点击这些解析失败图片的右上角红色X,把这些无法解析的图片删除掉
三、信息识别
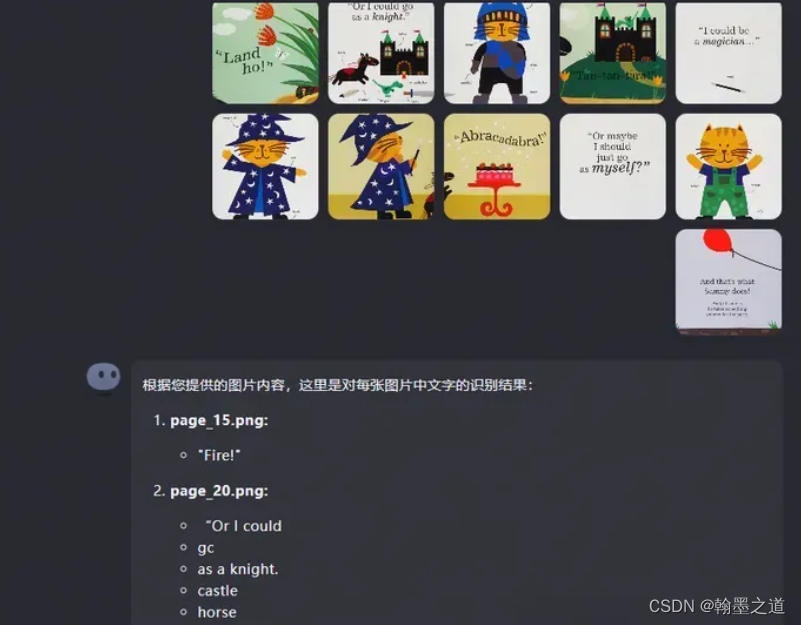
回车后,就全