现代人工智能的快速发展中,分类任务的高效解决方案一直备受关注。今天,我们向大家介绍一种名为Self-Classifier的全新自监督端到端分类学习方法。由Elad Amrani、Leonid Karlinsky和Alex Bronstein团队开发,Self-Classifier通过优化同一样本的两个增强视图的同类预测,能够在单阶段的端到端过程中同时学习标签和表示。
为了避免出现所有标签都被错误地分配到同一类的退化解决方案,研究团队提出了一种在预测标签上具有均匀先验的交叉熵损失的数学变体。经过理论验证,该方法能够有效地排除退化解,确保最优解的合理性和多样性。
Self-Classifier的设计简单且具有高度的可扩展性。与其他流行的无监督分类和对比表示学习方法不同,Self-Classifier无需预训练、期望最大化、伪标签、外部聚类、第二网络、停止梯度操作或负样本对等复杂步骤。尽管其实现过程简洁明了,该方法在ImageNet的无监督分类中设立了新的标杆,并且在无监督表示学习中也取得了与当前最先进方法相当的成果。有关更多细节和代码实现,您可以访问此处。
github:https://github.com/elad-amrani/self-classifier
.
接下来,我们将深入探讨Self-Classifier的工作原理及其在实际应用中的优势。
论文标题:Self-Supervised Classification Network
论文地址:https://arxiv.org/pdf/2103.10994v3
引言
近年来,自监督视觉表示学习逐渐成为研究热点。其核心思想是定义并解决一个前置任务,使得模型在没有任何人工标注标签的情况下能够学习到有意义的语义表示。这些学到的表示随后可以在较小的数据集上进行微调,并应用于各种下游任务。当前最先进的自监督模型大多基于对比学习,这些模型通过最大化同一图像的两个不同增强视图之间的相似性,同时最小化不同图像之间的相似性来实现目标。然而,尽管这些模型整体性能优异,对于某些下游任务(如无监督分类),它们所定义的前置任务目标可能并不完全契合。例如,用于预训练的实例区分方法在当前最先进的无监督分类方法中,虽然减少了所有实例之间的相似性,但这可能与分类任务的目标相悖。
为了解决这一问题,本文提出了一种基于分类的前置任务,其目标直接与最终的分类任务对齐。在这种方法中,我们只需要知道类别的数量C,便可学习到一个无监督分类器(Self-Classifier),使得同一图像的两个不同增强视图被分类为相同的类。然而,这样的任务容易产生退化解决方案,即所有样本都被分配到同一个类。为避免这种情况,我们在标准交叉熵损失函数上引入了均匀先验,使数据的均分成为最优解决方案。事实上,我们证明了这种方法的最优解集合不包括退化的解。
我们的方法也可以看作是一种结合了对比学习的深度无监督聚类方法。与传统的深度聚类方法类似,我们同时学习神经网络的参数和聚类分配。最近的一些研究成功地将聚类与对比学习结合,但通常将聚类作为一个独立的步骤用于伪标签。相反,本文的方法在单阶段端到端的方式下,仅使用小批量随机梯度下降(SGD)同时学习表示和聚类标签。
本文的主要贡献包括:
- 提出了一种简单而有效的自监督单阶段端到端分类和表示学习方法。与之前的方法不同,我们的方法不需要任何形式的预训练、期望最大化算法、伪标签或外部聚类,不需要记忆库、第二网络、外部聚类、停止梯度操作或负样本对。
- 尽管方法简单,但在ImageNet的无监督分类中设立了新的标杆,达到了41.1%的top-1准确率,取得了与最先进的无监督表示学习相当的结果,并在转移到COCO检测/分割任务时,比其他自监督方法显著提高(约2%的平均精度)。
- 首次提供了自监督分类预测与一组不同类层次对齐的定量分析,并在这一新指标上比之前的最先进方法显著提高(最多3.4%的调整互信息)。
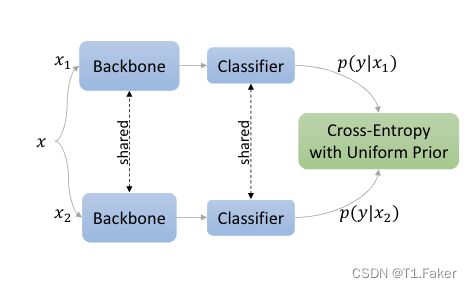
上图为自分类器架构:同一图像的两个增强视图由主干网(例如CNN)和分类器(例如投影MLP+线性分类头)。交叉熵
最小化两个视图中的一个以促进同类预测,
自监督学习在图像分类中的发展和方法
自监督学习方法通过定义和解决前置任务来学习紧凑的语义数据表示。在这些任务中,自然存在的监督信号被用于训练。近年来,计算机视觉领域提出了许多前置任务,包括颜色化、拼图、图像修补、上下文预测、旋转预测和对比学习等。这些前置任务为自监督学习提供了丰富的研究方向,使得无监督的数据表示学习得到了广泛的发展和应用。
对比学习表现出极大的潜力,已成为自监督学习的标准方法。早期的两项对比学习研究是Exemplar CNN和非参数实例区分(NPID)。Exemplar CNN通过卷积神经网络分类器学习区分实例,每个类代表一个实例及其增强视图。尽管这种方法简单有效,但它不能扩展到任意大的无标签数据量,因为它需要一个与数据集大小相同的分类层(softmax)。NPID通过用噪声对比估计(NCE)来近似完整的softmax分布,并利用内存库存储每个实例的最新表示,避免在每个学习过程的时间步计算整个数据集的表示,从而解决了这个问题。这种近似方法是有效的,因为与Exemplar CNN不同,它允许在大量无标签数据上进行训练。然而,NPID提出的内存库引入了一个新问题——存储在内存库中的表示缺乏一致性,即内存库中不同样本的表示是在多个不同时间步计算的。尽管如此,Exemplar CNN和NPID激发了一系列关于对比学习的研究。
最近的一项研究SwAV与本研究最为相似。SwAV利用了对比方法,而无需计算成对比较。更具体地说,它在对数据进行聚类的同时,强制不同增强视图(或“视角”)的聚类分配保持一致,而不是直接比较特征。为避免所有样本收敛到单个聚类的简单解决方案,SwAV在使用反向传播进行表示学习和使用Sinkhorn-Knopp算法进行单独的聚类步骤之间交替进行。与SwAV不同,本研究提出了一种在单阶段端到端的方式中同时学习表示和聚类分配的模型。这种方法不仅简化了训练过程,还提高了分类和表示学习的效率。
无监督图像聚类方法
尽管多年来提出了许多深度聚类方法,但只有两种方法(SCAN和 SeLa)证明了在像ImageNet这样的大规模数据集上的可扩展性。这些方法在解决无监督图像分类任务方面取得了显著进展,但依然面临一些挑战。例如,传统的基于聚类的方法往往依赖于外部算法(如k-means)或者需要多个阶段的迭代,从而可能受限于局部最优解或者计算复杂度的增加。此外,这些方法通常需要手动调整超参数或者需要依赖额外的数据结构,如内存库或者聚类数目的先验知识。
近年来的研究趋势表明,单阶段端到端的深度聚类方法正在成为一个新的方向。这些方法旨在通过简化流程和减少人为干预来提高算法的鲁棒性和可扩展性。例如,本文提出的方法借鉴了对比学习和聚类的结合思想,通过在学习过程中引入均匀标签先验,有效地避免了退化的解决方案,并在ImageNet数据集上取得了显著的无监督分类性能提升。
总体而言,深度无监督聚类在自监督学习的框架下,不仅促进了图像特征表示的学习,还为大规模无标签数据的有效利用提供了新的可能性。然而,如何在保持算法简洁性的同时,进一步提升其性能和泛化能力,仍然是当前研究的关键挑战之一。未来的工作将集中于优化算法的效率,探索更具鲁棒性的损失函数设计,以及推动这些方法在更广泛的视觉任务和数据集上的应用。
自监督分类计算过程
在自监督学习中,通过定义一种预文本任务来学习图像数据的语义表示,而无需人工标注的标签。本文提出了一种名为 Self-Classifier 的方法,旨在通过学习同一图像样本的不同增强视图之间的相似性,来实现图像分类任务。让我们一起来看看这个方法是如何实现的。
目标
我们的目标是学习一个分类器 y = f ( x i ) ∈ [ C ] y=f(x_i) \in [C] y=f(xi)∈[C],其中
C C C是类别数,使得同一样本的不同增强视图被分类为相似的类别,同时避免退化的解决方案。
初始的交叉熵损失(Naive Cross-Entropy Loss)
最初的想法是通过最小化交叉熵损失来实现这一目标:
ℓ ~ ( x 1 , x 2 ) = − ∑ y ∈ [ C ] p ( y ∣ x 2 ) log p ( y ∣ x 1 ) (1) \tilde{\ell}(x_1, x_2) = -\sum_{y \in [C]} p(y|x_2) \log p(y|x_1) \tag{1} ℓ~(x1,x2)=−y∈[C]∑p(y∣x2)logp(y∣x1)(1)
在这里, p ( y ∣ x ) p(y∣x) p(y∣x) 是由我们的模型(包括骨干网络和分类器)为所有类别(列)和批量样本(行)生成的 logits 矩阵的行 softmax,使用温度参数 τ r o w τ_{row} τrow。然而,简单地尝试最小化这种损失(式(1))往往会导致网络预测为常数类别 y y y,而不考虑输入 x x x。
引入贝叶斯和总概率法则(Bayes and Total Probability Law)
为了解决上述问题,我们引入了贝叶斯和总概率法则:
p ( y ∣ x 2 ) = p ( y ) p ( x 2 ∣ y ) p ( x 2 ) = p ( y ) p ( x 2 ∣ y ) ∑ y ~ ∈ [ C ] p ( x 2 ∣ y ~ ) p ( y ~ ) (2) p(y|x_2) = \frac{p(y)p(x_2|y)}{p(x_2)} = \frac{p(y)p(x_2|y)}{\sum_{\tilde{y} \in [C]} p(x_2|\tilde{y}) p(\tilde{y})} \tag{2} p(y∣x2)=p(x2)p(y)p(x2∣y)=∑y~∈[C]p(x2∣y~)p(y~)p(y)p(x2∣y)(2)
p ( y ∣ x 1 ) = p ( y ) p ( y ∣ x 1 ) p ( y ) = p ( y ) p ( y ∣ x 1 ) ∑ x ~ 1 ∈ B 1 p ( y ∣ x ~ 1 ) p ( x ~ 1 ) (3) p(y|x_1) = \frac{p(y)p(y|x_1)}{p(y)} = \frac{p(y)p(y|x_1)}{\sum_{\tilde{x}_1 \in B_1} p(y|\tilde{x}_1) p(\tilde{x}_1)} \tag{3} p(y∣x1)=p(y)p(y)p(y∣x1)=∑x~1∈B1p(y∣x~1)p(x~1)p(y)p(y∣x1)(3)
这里, p ( x ∣ y ) p(x∣y) p(x∣y)是我们的 logits 矩阵的列 softmax,使用温度参数 τ c o l τ_{col} τcol。假设 p ( x 1 ) p(x_1) p(x1) 是均匀分布(在训练样本等概率的合理假设下),并且我们希望所有类别都被使用,因此对 p ( y ) p(y) p(y)假设一个直观的均匀先验。
提出的损失函数(Proposed Loss Function)
基于上述假设,我们提出了下面的损失函数:
ℓ ( x 1 , x 2 ) = − ∑ y ∈ [ C ] p ( x 2 ∣ y ) ∑ y ~ p ( x 2 ∣ y ~ ) log ( N C p ( y ∣ x 1 ) ∑ x ~ 1 p ( y ∣ x ~ 1 ) ) (4) \ell(x_1, x_2) = -\sum_{y \in [C]} \frac{p(x_2|y)}{\sum_{\tilde{y}} p(x_2|\tilde{y})} \log \left( \frac{N}{C} \frac{p(y|x_1)}{\sum_{\tilde{x}_1} p(y|\tilde{x}_1)} \right) \tag{4} ℓ(x1,x2)=−y∈[C]∑∑y~p(x2∣y~)p(x2∣y)log(CN∑x~1p(y∣x~1)p(y∣x1))(4)
这个损失函数的设计目的是使得两个不同视角的样本在类别预测上尽可能一致,从而促使模型学习到有意义的表示。
对称损失函数(Symmetric Loss Function)
为了进一步提升训练的效果,我们使用对称损失函数:
L = 1 2 ( ℓ ( x 1 , x 2 ) + ℓ ( x 2 , x 1 ) ) (5) \mathcal{L} = \frac{1}{2} \left( \ell(x_1, x_2) + \ell(x_2, x_1) \right) \tag{5} L=21(ℓ(x1,x2)+ℓ(x2,x1))(5)
这个损失函数考虑了两个视角之间的对称性,确保了模型在处理不同视角时具有一致的表现。
综上所述,虽然 Self-Classifier 方法非常简单(只需几行类似于 PyTorch 的伪代码),但它在自监督分类任务中取得了新的技术突破,推动了这一领域的进展
算法步骤
| 步骤描述 | 伪代码 |
|---|---|
| 输入参数 | N N N: 批次中的样本数 C C C: 类别数 t r t_r tr, t c t_c tc: 行/列softmax温度 a u g ( ) aug() aug(): 随机数据增强 s o f t m a x X ( ) softmaxX() softmaxX(): 在维度 X X X上的 s o f t m a x softmax softmax, n o r m X ( ) normX() normX(): 维度 X X X上的 L 1 L1 L1标准化 |
| 遍历数据加载器 | for x in loader: |
| 前向传播 | s1, s2 = model(aug(x)), model(aug(x)) |
| 计算对数概率 | log_y_x1 = log(N / C * norm0(softmax1(s1 / t_r))) log_y_x2 = log(N / C * norm0(softmax1(s2 / t_r))) |
| 计算logits的softmax | y_x1 = norm1(softmax0(s1 / t_c)) y_x2 = norm1(softmax0(s2 / t_c)) |
| 计算各自的损失 | l1 = -sum(y_x2 * log_y_x1) / N l2 = -sum(y_x1 * log_y_x2) / N |
| 计算对称损失 | L = (l1 + l2) / 2 |
| 反向传播 | L.backward() |
| 优化器更新 | optimizer.step() |
示例的PyTorch代码
以下是将伪代码转换为类似PyTorch风格的实现:
import torch
import torch.nn.functional as F
# 定义参数
N = 32 # 批次大小
C = 10 # 类别数
t_r = 0.1 # 行softmax温度
t_c = 0.1 # 列softmax温度
# 模型定义(请根据实际情况定义自己的模型)
class YourModel(torch.nn.Module):
def __init__(self):
super(YourModel, self).__init__()
# 在这里定义你的模型架构
self.fc = torch.nn.Linear(input_size, output_size)
def forward(self, x):
# 示例前向传播
x = self.fc(x)
return x
model = YourModel()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 数据加载器设置(请根据实际情况设置自己的数据加载器)
data_loader = torch.utils.data.DataLoader(dataset, batch_size=N, shuffle=True)
# 训练循环
for batch_idx, (x, _) in enumerate(data_loader):
# 数据增强
x_aug1 = aug(x)
x_aug2 = aug(x)
# 前向传播
s1 = model(x_aug1)
s2 = model(x_aug2)
# 计算log概率
log_y_x1 = torch.log(N / C * F.normalize(F.softmax(s1 / t_r, dim=-1), p=1, dim=-1))
log_y_x2 = torch.log(N / C * F.normalize(F.softmax(s2 / t_r, dim=-1), p=1, dim=-1))
# 计算logits的softmax
y_x1 = F.normalize(F.softmax(s1 / t_c, dim=-1), p=1, dim=-1)
y_x2 = F.normalize(F.softmax(s2 / t_c, dim=-1), p=1, dim=-1)
# 计算各自的损失
l1 = -torch.sum(y_x2 * log_y_x1) / N
l2 = -torch.sum(y_x1 * log_y_x2) / N
# 计算对称损失
L = (l1 + l2) / 2
# 反向传播
optimizer.zero_grad()
L.backward()
optimizer.step()
结果分析
无监督图像分类
文章作者使用大规模ImageNet数据集评估了这些的方法,用于无监督图像分类(见表1至表3)。报告了标准的聚类评估指标:标准化互信息(NMI)、调整后的标准化互信息(AMI)、调整兰德指数(ARI)和聚类准确度(ACC)。
文章的方法在所有四个指标(NMI、AMI、ARI和ACC)上都达到了新的最先进性能,即使训练的epoch数量明显较少(见表1)。文章作者将这些的方法与最新的大规模深度聚类方法进行了比较,这些方法都在ImageNet上进行了显式评估。此外,还将这些的方法与最新的自监督表示学习方法(使用ImageNet预训练模型)进行了比较,这些模型经过拟合k均值分类器对训练集上的学习表示进行了推断。所有方法的推断都是在验证集上进行的(在训练期间未曾见过)。
当前最先进的方法SCAN是一个多阶段算法,包括:
1)预训练(800个epoch);
2)离线k最近邻挖掘;
3)聚类(100个epoch);
4)自标记和微调(25个epoch)。
相比之下,Self-Classifier是一个单阶段、易于实现的模型(参见算法1),只使用小批量SGD进行训练。仅仅在200个epoch后,Self-Classifier就超过了经过925个epoch训练的SCAN。
SCAN提供了有趣的定性分析,分析了其无监督类别预测与默认的(WordNet)ImageNet语义层次结构的某个级别的对齐情况。相比之下,提出了更多样化的定量指标,以评估自监督分类方法在默认的ImageNet层次结构不同级别上的性能,以及在经过精心策划的ImageNet子人口(BREEDS)的多个层次上的性能。
实施细节
在所有实验中,使用了ResNet-50作为骨干网络,并采用了通常用于所有比较的自监督学习工作的初始化方法。投影头部分采用了一个包含两层(大小分别为4096和128)的MLP,具有BN、泄漏ReLU激活函数,并在最后一层后进行了ℓ2归一化。在投影头部分的MLP之上,有4个分类头,分别面向1K、2K、4K和8K个类别。每个分类头都是一个简单的线性层,没有额外的偏置项。行softmax温度 τ r o w τ_{row} τrow设定为0.1,列softmax温度 τ c o l τ_{col} τcol设定为0.05。
图像增强
文章作者遵循了BYOL的数据增强方法,包括颜色抖动、高斯模糊和日晒化,以及多裁剪(两个全局224×224视图和六个局部96×96视图)和最近邻增强(最近邻增强的队列设置为256K)。
优化
无监督预训练/分类:文章作者的大多数训练超参数直接来的SwAV。使用了LARS优化器,学习率为4.8,权重衰减为 1 0 − 6 10^-6 10−6。学习率在前10个epoch内线性增加(从0.3开始),然后使用余弦调度器在接下来的790个epoch内线性减少,最终值为0.0048(共800个epoch)。使用了分布在64个NVIDIA V100 GPU上的批量大小为4096。
线性评估:类似于,使用了LARS优化器,学习率为0.8,没有使用权重衰减。学习率使用余弦调度器在100个epoch内线性减少,使用了分布在16个NVIDIA V100 GPU上的批量大小为4096。还尝试了中使用SGD优化器,批量大小为256,结果相似。
表1:ImageNet无监督图像分类结果(NMI、AMI、ARI和ACC)
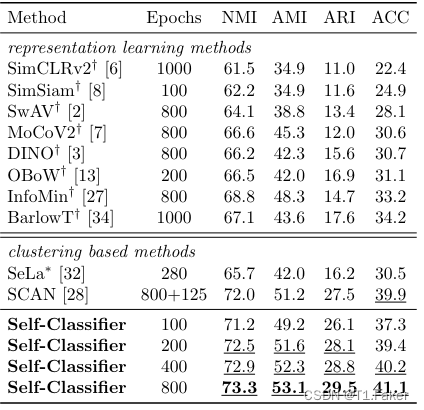
表2:ImageNet-superclasses无监督图像分类准确率
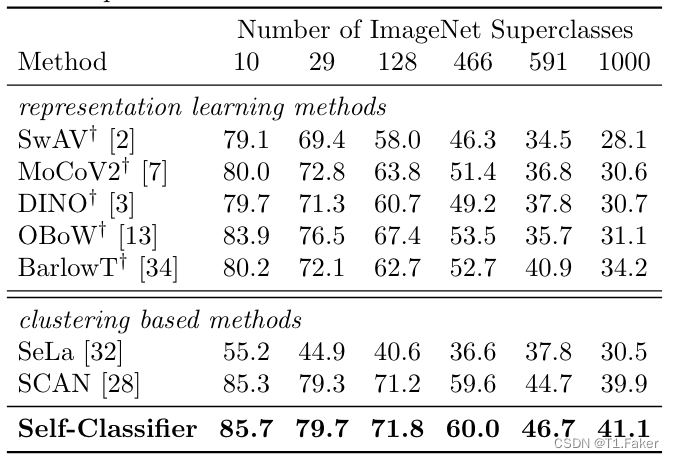
表3:ImageNet-subsets(BREEDS)无监督图像分类结果