⼈们通常通过视觉来感知物体表⾯的性质,但有时需要通过触觉信息来补充或替代视觉信息。在机器⼈感知物体属性⽅⾯,基于视觉的触觉传感器是⽬前的最新技术,因为它们可以产⽣与表⾯接触的⾼分辨率 RGB 触觉图像。然⽽,这些图像需要⼤量的数据进⾏训练,⽽在现实世界中收集这些数据可能很困难。虽然已经提出了模拟器来解决这个问题,但它们很难以⾼保真度重现机械特性和光分布效果。因此,本⽂旨在通过使⽤从DIGIT传感器收集的少量真实未标记图像训练扩散模型(Diffusion Model)来填补模拟和真实图像之间的差距。
论⽂地址: https://arxiv.org/abs/2311.01380
作者提出了⼀个可以区分平⾯、曲线、边缘和⻆落四种类别的表⾯分类器,并使⽤从 YCB 模型集中的对象表⾯均匀采样的模拟图像进⾏训练。为了标记这些图像,作者在对象⽹格上采样点云,并使⽤⾃动过程评估每个点的局部曲率来提取标签。作者在⼗个 3D 打印的 YCB 对象上测试了分类器,并与仅使⽤模拟图像训练的分类器进⾏了⽐较。实验结果表明,作者的⽅法在分类任务中取得了更好的准确性。
1.相关⼯作
作者对⽐了其他基于视觉触觉传感器的物体表⾯分类的相关⼯作。
在 Sim2Real ⽅⾯,⼀些⼯作通过模拟真实传感器的⾏为来减⼩ Sim2Real 差距。还有⼀些⽅法试图减⼩模拟和真实图像之间的领域差异。与之不同,作者的⼯作是利⽤来⾃ TACTO 的模拟图像,通过在真实图像上训练的 DM 进⾏转换,以模拟凝㬵的真实变形和传感器的光传输。
Learning to Read
Braille: Bridging the Tactile Reality
Gap with Diffusion Models
https://arxiv.org/abs/2304.01182
这份⼯作中也采取了类似的⽅法,但是其使⽤的 DM 是使⽤附加深度的图⽚中训练出来的,⽽这些图⽚来⾃于
MidasTouch: Monte-Carlo
inference over distributions across sliding touch
https://arxiv.org/abs/2210.14210
训练的⽹络。在作者的例⼦中,并不需要这个⽹络,只依赖于 RGB 的图像。
在基于视觉触觉传感器的物体感知⽅⾯,没有直接使⽤基于视觉触觉传感器对物体表⾯进⾏分类的⼯作。作者参考了其它推断物体的类似属性的⼯作,如形状估计或识别表⾯上可能的接触点等。
2.⽅法
本⽂的⽅法主要包括两个层次的适应,以减⼩模拟和真实数据之间的差距,并提⾼分类性能。⾸先,本⽂采⽤概率 DM(Diffusion Model)来翻译模拟图像,以减⼩模拟和真实图像之间的领域差异。其次,本⽂使⽤领域对抗训练(Domain-Adversarial Training of Neural Networks,DANN)⽅法来进⼀步调整模型特征,以提⾼分类性能。
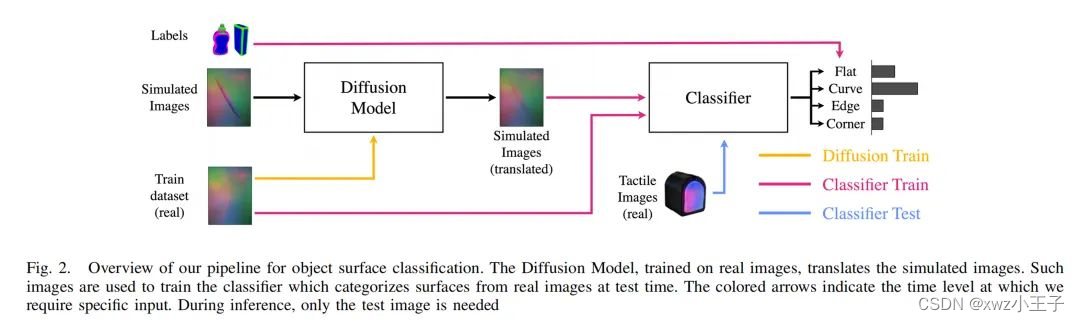
2.1模拟数据的获取和标记
⾸先,使⽤ Poisson disk sampling ⽅法从物体⽹格中提取均匀分布的点云,并考虑传感器在法线⽅向上的旋转和穿透深度,模拟 DIGIT 传感器产⽣的图像。然后,使⽤⼀个简单⽽有效的算法对点云中的每个点进⾏分类,将其标记为平⾯、曲线、边缘或⻆点。通过这种⽅式,⾃动化地获取和标记了模拟数据。整个过程确保了数据的多样性和标记的准确性。

2.2图像级适应

由于 DIGIT 传感器获得的模拟图像和真实图像表现出的显著差异,作者提出了⼀种⽆监督的转换⽅法来解决这两个域之间的域转移问题。具体来说,作者通过训练⼀个 DM 模型来根据模拟图像⽣成对应真实世界域的图像,在训练之后,可以在模拟图像中引⼊随机噪声,再通过 DM 反向降噪,最终⽣成对应真实⻛格的图像。
2.3特征级适应
虽然经过 DM 处理,图像的域移已经显著减少,但还存在⼀些残余的差异,为了解决这个问题,作者利⽤⼀种称为神经⽹络的对抗性域⾃适应训练(DANN)的经典对抗性⽅法来学习域不变表⽰。作者使⽤ Dinov2 的⽅法,使⽤预训练 ViT 作为特征提取器,并训练瓶颈层和分类器将特征映射到域不变空间和⽬标类别,并且使⽤判别器来区分真实和模拟图像,⽽瓶颈层则被优化为使两个域的特征⽆法区分。
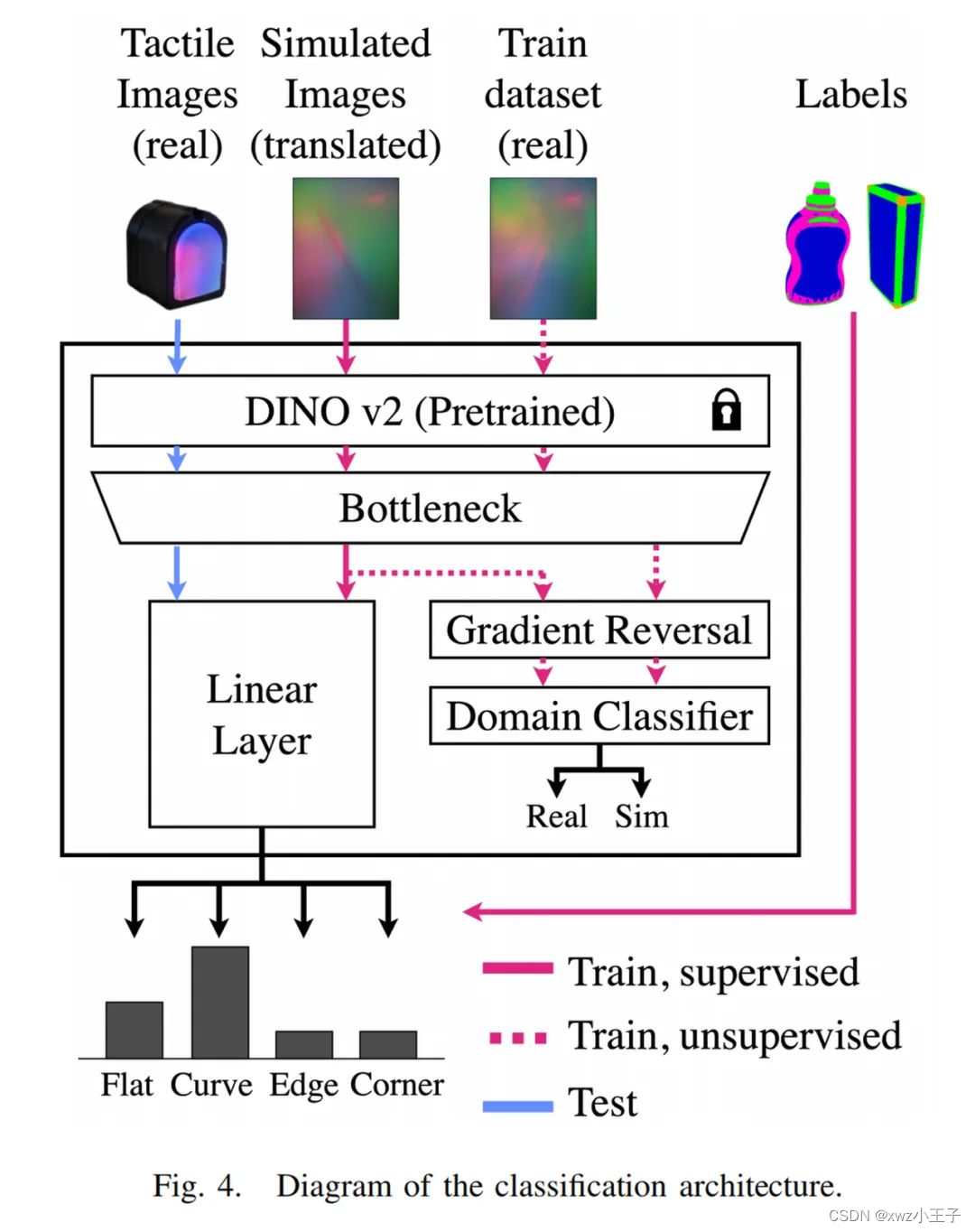
2.4训练和测试数据集
作者⼀共使⽤三个数据集,第⼀个数据集Trainreal包含 5000 个从⽇常物品获取的真实图像。第⼆个数据集Trainsim包括从 10 个YCB 物体⽣成的 50000 个模拟图像。第三个数据集Testreal包含 792 个从3D 打印的YCB物体获取的真实图像,⽤于评估⽬的。这些数据集⽤于训练扩散⽅法(DM)和使⽤领域对抗训练神经⽹络(DANN)的分类器,并在Testreal上进⾏测试。
3.实验结果
作者通过评估分类器在每个对象上的准确性和每个类别的 F1 分数,来评估分类器的性能。并进⾏了⼏项消融研究,以调查 DM 和 DANN 程序的作⽤。除了分类任务外,作者还将此⽅法应⽤于估计 6D 物体姿态的流⽔线(Pipeline)中,以展⽰其在实际任务中的有效性。
3.1表⾯分类实验
作者通过对⽐
None:未经过翻译的模拟图像
Tactile Diffusion: 上⽂提到的扩散模型图像翻译
Ours:论⽂中提出的⽅法并且对于每个对⽐项内,分别对⽐是否使⽤ DANN,结论如下

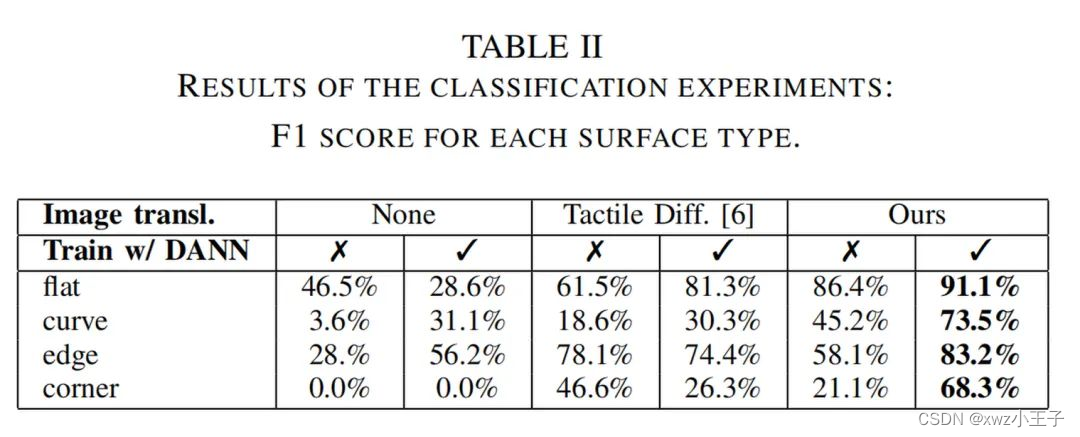
Accuracy
F1-Score根据实验结果,作者的⽅法在表⾯类型分类任务中表现出⾊,特别是在⻆部类别(corner)上取得不错的性能表现。实验结果表明,作者提出的分类器和⾃动标注程序的结合对于提供传感器在物体表⾯接触位置的假设是有⽤的。
3.2 6D 物体姿态估计实验
作者通过使⽤
Collision-aware In-hand
6D Object Pose Estimation using Multiple Vision-based Tactile Sensors
https://arxiv.org/abs/2301.13667
提到的算法来估计与 N 个触觉传感器接触的物体的 6D 姿态。通过输⼊触觉图像和机器⼈本体感知的传感器姿态来估计物体的 6D 姿态,并且替换了⽂中的假设提取部分,⽤本⽂提出的表⾯分类器来⽣成假设,之后在每个对象上使⽤了 3 个传感器进⾏实验,并结合了从分类实验中收集的多种传感器姿态。
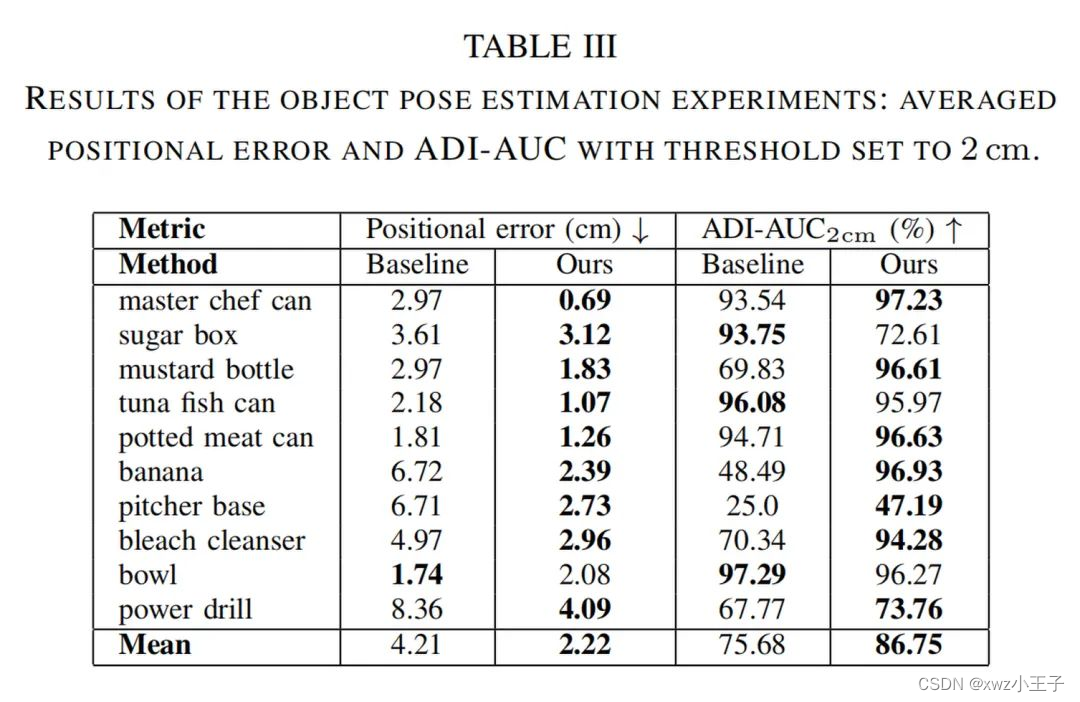
实验通过⽐较输出姿态和基准姿态,评估位置误差和 ADI-AUC 指标,具体结果如下
本⽂⽅法相对于⼏何基准⽅法,在位置误差上减少了⼀半,旋转指标提⾼了超过⼗个百分点。实验结果表明了使⽤触觉反馈(表⾯分类器)显著降低了位置误差,并提⾼了旋转精度。由此验证了本⽂⽅法在实际应⽤中的有效性。
4.局限性与结论
虽然本⽂的⽅法在减少 Sim2Real 的域差异和提⾼物体表⾯分类与 6D 物体姿态估计的准确性⽅⾯表现出了显著优势,作者认为仍然存在 2 个⽅⾯的不⾜DIGIT传感器的弹性体需要适度的⼒才能突出表⾯差异。如果接触⼒不⾜,可能会影响⽅法的效果。扩散模型的训练和图像翻译时间较⻓,尽管模型在不同设备上⽆需重新训练,但时间消耗仍不可忽视。未来将探索本⽂⽅法在其他机器⼈任务中的应⽤,并研究新的适应机制以进⼀步提⾼分类精度,同时处理多表⾯同时接触的情况。