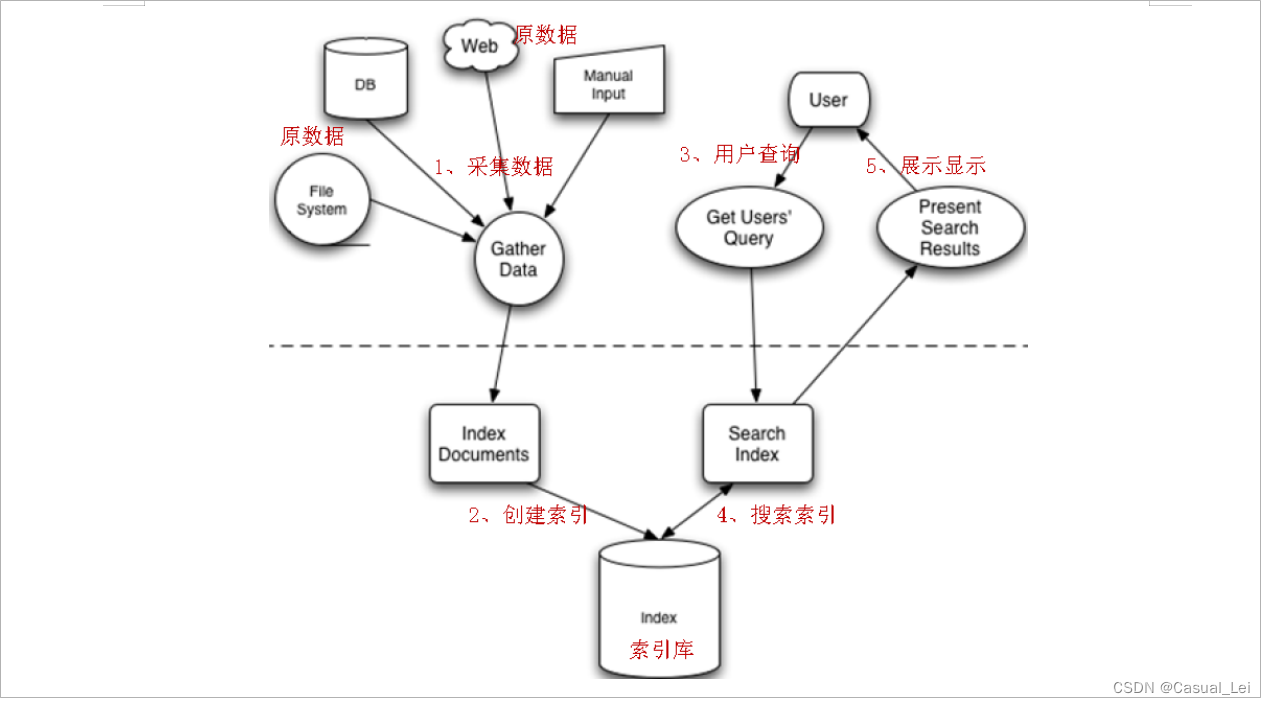
分类模型的评估
回归模型的评估方法,主要有均方误差MSE,R方得分等指标,在分类模型中,我们主要应用的是准确率这个评估指标,除此之外,常用的二分类模型的模型评估指标还有召回率(Recall)、F1指标(F1-Score)等等
准确率的局限性💥
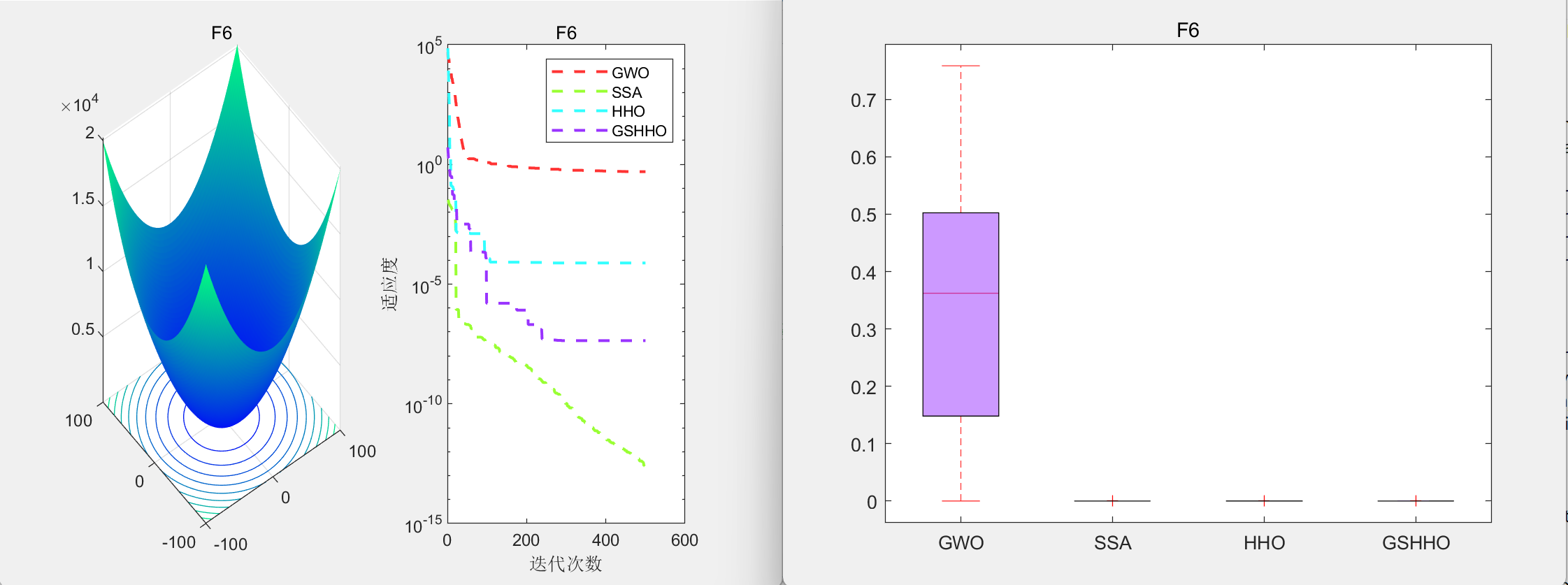
准确率的定义是:对于给定的测试集,分类模型正确分类的样本数与总样本数之比。举个例子来讲,有一个简单的二分类模型model,专门用于分类动物,在某个测试集中,有30个猫+70个狗,这个二分类模型在对这个测试集进行分类的时候,得出该数据集有40个猫(包括正确分类的25个猫和错误分类的15个狗)和60个狗(包括正确分类的55个狗和错误分类的5个猫猫)。画成矩阵图表示,结果就非常清晰:

从图中可以看出,行表示该测试集中实际的类别,比如猫类一共有25+5=30个,狗狗类有15+55=70个。其中被分类模型正确分类的是该表格的对角线所在的数字。在sklearn中,这样一个表格被命名为混淆矩阵(Confusion Matrix),所以,按照准确率的定义,可以计算出该分类模型在测试集上的准确率为: Accuracy = 80%
💢即,该分类模型在测试集上的准确率为80%
在分类模型中可以定义
- Actual condition positive(P):样本中阳性样本总数,一般也就是真实标签为1的样本总数;
- Actual condition negative(N):样本中阴性样本总数,一般也就是真实标签为0的样本总数;
- Predicted condition positive(PP):预测中阳性样本总数,一般也就是预测标签为1的样本总数;
- Predicted condition negative(PN):预测中阴性样本总数,一般也就是预测标签为0的样本总数;
- 当前案例中,可以将猫猫类别作为阳性样本,也就是二分类中的1类,狗狗作为阴性数据,也就是0类样本
- 对于刚才的案例而言,P = 30, N = 70, PP = 40, PN = 60
进行二分类模型预测过程中,样本类别被模型正确识别的情况其实有两种,一种是阳性样本被正确识别,另一种是阴性样本被正确识别,据此我们可以有如下定义:
- True positive(TP):样本属于阳性(类别1)、并且被正确识别为阳性(类别1)的样本总数;TP发生时也被称为正确命中(hit);
- True negative(TN):样本属于阴性(类别0)、并且被正确识别为阴性(类别0)的样本总数;TN发生时也被称为正确拒绝(correct rejection);
上述样本中,TP=25,TN = 55 ~
当然,对于误分类的样本,其实也有两种情况,其一是阳性样本被误识别为阴性,其二是阴性样本被误识别为阳性,据此我们也有如下定义:
- False positive(FP):样本属于阴性(类别0),但被错误判别为阳性(类别1)的样本总数;FP发生时也被称为发生I类了错误(Type I error),或者假警报(False alarm)、低估(underestimation)等;
- False negative(FN):样本属于阳性(类别1),但被错误判别为阴性(类别0)的样本总数;FN发生时也被称为发生了II类错误(Type II error),或者称为错过目标(miss)、高估(overestimation)等;
混淆矩阵也可以写成如下形式

但是,准确率指标并不总是能够评估一个模型的好坏,比如对于下面的情况,假如有一个数据集,含有98个狗狗,2个猫,而分类器model,是一个很差劲的分类器,它把数据集的所有样本都划分为狗狗,也就是不管输入什么样的样本,该模型都认为该样本是狗狗。
💯 则该模型的准确率为98%,因为它正确地识别出来了测试集中的98个狗狗,只是错误的把2个猫咪也当做狗狗,所以按照准确率的计算公式,该模型有高达98%的准确率。
💢可是,这样的模型有意义吗?我们主要想识别出猫猫的类别,特意把猫猫作为1类,但是当前模型为了尽量追求准确率,完全牺牲了对猫猫识别的精度,这是一个极端的情况,却又是普遍的情况,准确率在一些场景并不适用,特别是对于这种样品数量偏差比较大的问题,准确率的“准确度”会极大的下降。所以,这时就需要引入其他评估指标评价模型的好坏。
召回率(Recall)💯
召回率侧重于关注全部的1类样本中别准确识别出来的比例,其计算公式为

对于当前案例,我们的召回率是 25 / (25+5) = 0.833, 30条正例样本,其中25条被预测正确
根据召回率的计算公式我们可以试想,如果以召回率作为模型评估指标,则会使得模型非常重视是否把1全部识别了出来,甚至是牺牲掉一些0类样本判别的准确率来提升召回率,即哪怕是错判一些0样本为1类样本,也要将1类样本识别出来,这是一种“宁可错杀一千不可放过一个”的判别思路。因此,召回率其实是一种较为激进的识别1类样本的评估指标,在0类样本被误判代价较低、而1类样本被误判成本较高时可以考虑使用。“宁可错杀一千不可放过一个
当然,对于极度不均衡样本,这种激进的判别指标也能够很好的判断模型有没有把1类样本成功的识别出来。例如总共100条数据,其中有99条样本标签为0、剩下一条样本标签为1,假设模型总共有A、B、C三个模型,A模型判别所有样本都为0类,B模型判别50条样本为1类50条样本为0类,并且成功识别唯一的一个1类样本,C模型判别20条样本为1类、80条样本为0类,同样成功识别了唯一的一个1类样本,则各模型的准确率和召回率如下:

不难发现,在偏态数据中,相比准确率,召回率对于1类样本能否被正确识别的敏感度要远高于准确率,但对于是否牺牲了0类别的准确率却无法直接体现。
精确率(Precision)💯
精确率的定义是:对于给定测试集的某一个类别,分类模型预测正确的比例,或者说:分类模型预测的正样本中有多少是真正的正样本,其计算公式是:
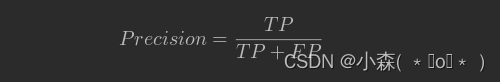
当前案例中,Precision = 25 / 25 + 15 = 0.625
精确度,衡量对1类样本的识别,能否成功(准确识别出1)的概率,也正是由于这种力求每次出手都尽可能成功的策略,使得当我们在以精确度作为模型判别指标时,模型整体对1的判别会趋于保守,只对那些大概率确定为1的样本进行1类的判别,从而会一定程度牺牲1类样本的准确率,在每次判别成本较高、而识别1样本获益有限的情况可以考虑使用精确度
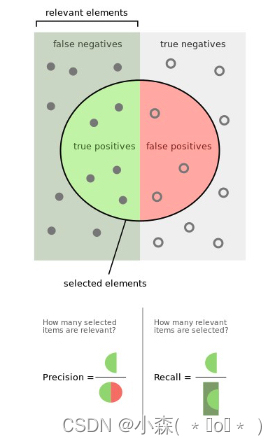
💤关于召回率和精确度,也可以通过如下形式进行更加形象的可视化展示
- F1值(F1-Measure)
在理想情况下,我们希望模型的精确率越高越好,同时召回率也越高越高,但是,现实情况往往事与愿违,在现实情况下,精确率和召回率像是坐在跷跷板上一样,往往出现一个值升高,另一个值降低,那么,有没有一个指标来综合考虑精确率和召回率了,再大多数情况下,其实我们是希望获得一个更加“均衡”的模型判别指标,即我们既不希望模型太过于激进、也不希望模型太过于保守,并且对于偏态样本,既可以较好的衡量1类样本是否被识别,同时也能够兼顾考虑到0类样本的准确率牺牲程度,此时,我们可以考虑使用二者的调和平均数(harmonic mean)作为模型评估指标,这个指标就是F值。F值的计算公式为
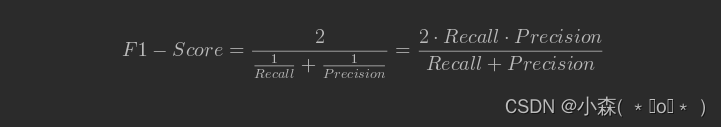
F1-Score指标能够一定程度上综合Recall和Precision的结果,综合判断模型整体分类性能。当然,除了F1-Score以外我们还可以取Recall和Precision的均值(balanced accuracy,简称BA)来作为模型评估指标
sklearn 中的指标计算
from sklearn.metrics import recall_score, precision_score, f1_score
y_true = [0, 1, 1, 0, 1, 1]
y_pred = [0, 0, 1, 1, 1, 0]
print(f"召回率:{recall_score(y_true, y_pred)}")
print(f"精确率:{precision_score(y_true, y_pred)}")
print(f"f1-score:{f1_score(y_true, y_pred)}")
召回率:0.5
精确率:0.6666666666666666
f1-score:0.5714285714285715- 在类别划分上,仍然需要强调的是,我们需要根据实际业务情况,将重点识别的样本类划为类别1,其他样本划为类别0
- 如果0、1两类在业务判断上并没有任何重要性方面的差异,那么我们可以将样本更少的哪一类划为1类
- 在评估指标选取上,同样需要根据业务情况判断,如果只需要考虑1类别的识别率,则可考虑使用Recall作为模型评估指标,若只需考虑对1样本判别结果中的准确率,则可考虑使用Precision作为评估指标。但一般来说这两种情况其实都不多,更普遍的情况是,需要重点识别1类但也要兼顾0类的准确率,此时我们可以使用F1-Score指标。F1-Score其实也是分类模型中最为通用和常见的分类指标