一、官方源代码
#!/usr/bin/env python3
#
# train an SSD detection model on Pascal VOC or Open Images datasets
# https://github.com/dusty-nv/jetson-inference/blob/master/docs/pytorch-ssd.md
#
import os
import sys
import logging
import argparse
import datetime
import itertools
import torch
from torch.utils.data import DataLoader, ConcatDataset
from torch.utils.tensorboard import SummaryWriter
from torch.optim.lr_scheduler import CosineAnnealingLR, MultiStepLR
from vision.utils.misc import Timer, freeze_net_layers, store_labels
from vision.ssd.ssd import MatchPrior
from vision.ssd.vgg_ssd import create_vgg_ssd
from vision.ssd.mobilenetv1_ssd import create_mobilenetv1_ssd
from vision.ssd.mobilenetv1_ssd_lite import create_mobilenetv1_ssd_lite
from vision.ssd.mobilenet_v2_ssd_lite import create_mobilenetv2_ssd_lite
from vision.ssd.squeezenet_ssd_lite import create_squeezenet_ssd_lite
from vision.datasets.voc_dataset import VOCDataset
from vision.datasets.open_images import OpenImagesDataset
from vision.nn.multibox_loss import MultiboxLoss
from vision.ssd.config import vgg_ssd_config
from vision.ssd.config import mobilenetv1_ssd_config
from vision.ssd.config import squeezenet_ssd_config
from vision.ssd.data_preprocessing import TrainAugmentation, TestTransform
from eval_ssd import MeanAPEvaluator
DEFAULT_PRETRAINED_MODEL='models/mobilenet-v1-ssd-mp-0_675.pth'
parser = argparse.ArgumentParser(
description='Single Shot MultiBox Detector Training With PyTorch')
# Params for datasets
parser.add_argument("--dataset-type", default="open_images", type=str,
help='Specify dataset type. Currently supports voc and open_images.')
parser.add_argument('--datasets', '--data', nargs='+', default=["data"], help='Dataset directory path')
parser.add_argument('--balance-data', action='store_true',
help="Balance training data by down-sampling more frequent labels.")
# Params for network
parser.add_argument('--net', default="mb1-ssd",
help="The network architecture, it can be mb1-ssd, mb1-ssd-lite, mb2-ssd-lite or vgg16-ssd.")
parser.add_argument('--resolution', type=int, default=300,
help="the NxN pixel resolution of the model (can be changed for mb1-ssd only)")
parser.add_argument('--freeze-base-net', action='store_true',
help="Freeze base net layers.")
parser.add_argument('--freeze-net', action='store_true',
help="Freeze all the layers except the prediction head.")
parser.add_argument('--mb2-width-mult', default=1.0, type=float,
help='Width Multiplifier for MobilenetV2')
# Params for loading pretrained basenet or checkpoints.
parser.add_argument('--base-net', help='Pretrained base model')
parser.add_argument('--pretrained-ssd', default=DEFAULT_PRETRAINED_MODEL, type=str, help='Pre-trained base model')
parser.add_argument('--resume', default=None, type=str, help='Checkpoint state_dict file to resume training from')
# Params for SGD
parser.add_argument('--lr', '--learning-rate', default=0.01, type=float,
help='initial learning rate')
parser.add_argument('--momentum', default=0.9, type=float,
help='Momentum value for optim')
parser.add_argument('--weight-decay', default=5e-4, type=float,
help='Weight decay for SGD')
parser.add_argument('--gamma', default=0.1, type=float,
help='Gamma update for SGD')
parser.add_argument('--base-net-lr', default=0.001, type=float,
help='initial learning rate for base net, or None to use --lr')
parser.add_argument('--extra-layers-lr', default=None, type=float,
help='initial learning rate for the layers not in base net and prediction heads.')
# Scheduler
parser.add_argument('--scheduler', default="cosine", type=str,
help="Scheduler for SGD. It can one of multi-step and cosine")
# Params for Multi-step Scheduler
parser.add_argument('--milestones', default="80,100", type=str,
help="milestones for MultiStepLR")
# Params for Cosine Annealing
parser.add_argument('--t-max', default=100, type=float,
help='T_max value for Cosine Annealing Scheduler.')
# Train params
parser.add_argument('--batch-size', default=4, type=int,
help='Batch size for training')
parser.add_argument('--num-epochs', '--epochs', default=30, type=int,
help='the number epochs')
parser.add_argument('--num-workers', '--workers', default=2, type=int,
help='Number of workers used in dataloading')
parser.add_argument('--validation-epochs', default=1, type=int,
help='the number epochs between running validation')
parser.add_argument('--validation-mean-ap', action='store_true',
help='Perform computation of Mean Average Precision (mAP) during validation')
parser.add_argument('--debug-steps', default=10, type=int,
help='Set the debug log output frequency.')
parser.add_argument('--use-cuda', default=True, action='store_true',
help='Use CUDA to train model')
parser.add_argument('--checkpoint-folder', '--model-dir', default='models/',
help='Directory for saving checkpoint models')
parser.add_argument('--log-level', default='info', type=str,
help='Logging level, one of: debug, info, warning, error, critical (default: info)')
args = parser.parse_args()
logging.basicConfig(stream=sys.stdout, level=getattr(logging, args.log_level.upper(), logging.INFO),
format='%(asctime)s - %(message)s', datefmt="%Y-%m-%d %H:%M:%S")
tensorboard = SummaryWriter(log_dir=os.path.join(args.checkpoint_folder, "tensorboard", f"{datetime.datetime.now().strftime('%Y%m%d_%H%M%S')}"))
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() and args.use_cuda else "cpu")
if args.use_cuda and torch.cuda.is_available():
torch.backends.cudnn.benchmark = True
logging.info("Using CUDA...")
def train(loader, net, criterion, optimizer, device, debug_steps=100, epoch=-1):
net.train(True)
train_loss = 0.0
train_regression_loss = 0.0
train_classification_loss = 0.0
running_loss = 0.0
running_regression_loss = 0.0
running_classification_loss = 0.0
num_batches = 0
for i, data in enumerate(loader):
images, boxes, labels = data
images = images.to(device)
boxes = boxes.to(device)
labels = labels.to(device)
optimizer.zero_grad()
confidence, locations = net(images)
regression_loss, classification_loss = criterion(confidence, locations, labels, boxes)
loss = regression_loss + classification_loss
loss.backward()
optimizer.step()
train_loss += loss.item()
train_regression_loss += regression_loss.item()
train_classification_loss += classification_loss.item()
running_loss += loss.item()
running_regression_loss += regression_loss.item()
running_classification_loss += classification_loss.item()
if i and i % debug_steps == 0:
avg_loss = running_loss / debug_steps
avg_reg_loss = running_regression_loss / debug_steps
avg_clf_loss = running_classification_loss / debug_steps
logging.info(
f"Epoch: {epoch}, Step: {i}/{len(loader)}, " +
f"Avg Loss: {avg_loss:.4f}, " +
f"Avg Regression Loss {avg_reg_loss:.4f}, " +
f"Avg Classification Loss: {avg_clf_loss:.4f}"
)
running_loss = 0.0
running_regression_loss = 0.0
running_classification_loss = 0.0
num_batches += 1
train_loss /= num_batches
train_regression_loss /= num_batches
train_classification_loss /= num_batches
logging.info(
f"Epoch: {epoch}, " +
f"Training Loss: {train_loss:.4f}, " +
f"Training Regression Loss {train_regression_loss:.4f}, " +
f"Training Classification Loss: {train_classification_loss:.4f}"
)
tensorboard.add_scalar('Loss/train', train_loss, epoch)
tensorboard.add_scalar('Regression Loss/train', train_regression_loss, epoch)
tensorboard.add_scalar('Classification Loss/train', train_classification_loss, epoch)
def test(loader, net, criterion, device):
net.eval()
running_loss = 0.0
running_regression_loss = 0.0
running_classification_loss = 0.0
num = 0
for _, data in enumerate(loader):
images, boxes, labels = data
images = images.to(device)
boxes = boxes.to(device)
labels = labels.to(device)
num += 1
with torch.no_grad():
confidence, locations = net(images)
regression_loss, classification_loss = criterion(confidence, locations, labels, boxes)
loss = regression_loss + classification_loss
running_loss += loss.item()
running_regression_loss += regression_loss.item()
running_classification_loss += classification_loss.item()
return running_loss / num, running_regression_loss / num, running_classification_loss / num
if __name__ == '__main__':
timer = Timer()
logging.info(args)
# make sure that the checkpoint output dir exists
if args.checkpoint_folder:
args.checkpoint_folder = os.path.expanduser(args.checkpoint_folder)
if not os.path.exists(args.checkpoint_folder):
os.mkdir(args.checkpoint_folder)
# select the network architecture and config
if args.net == 'vgg16-ssd':
create_net = create_vgg_ssd
config = vgg_ssd_config
elif args.net == 'mb1-ssd':
create_net = create_mobilenetv1_ssd
config = mobilenetv1_ssd_config
config.set_image_size(args.resolution)
elif args.net == 'mb1-ssd-lite':
create_net = create_mobilenetv1_ssd_lite
config = mobilenetv1_ssd_config
elif args.net == 'sq-ssd-lite':
create_net = create_squeezenet_ssd_lite
config = squeezenet_ssd_config
elif args.net == 'mb2-ssd-lite':
create_net = lambda num: create_mobilenetv2_ssd_lite(num, width_mult=args.mb2_width_mult)
config = mobilenetv1_ssd_config
else:
logging.fatal("The net type is wrong.")
parser.print_help(sys.stderr)
sys.exit(1)
# create data transforms for train/test/val
train_transform = TrainAugmentation(config.image_size, config.image_mean, config.image_std)
target_transform = MatchPrior(config.priors, config.center_variance,
config.size_variance, 0.5)
test_transform = TestTransform(config.image_size, config.image_mean, config.image_std)
# load datasets (could be multiple)
logging.info("Prepare training datasets.")
datasets = []
for dataset_path in args.datasets:
if args.dataset_type == 'voc':
dataset = VOCDataset(dataset_path, transform=train_transform,
target_transform=target_transform)
label_file = os.path.join(args.checkpoint_folder, "labels.txt")
store_labels(label_file, dataset.class_names)
num_classes = len(dataset.class_names)
elif args.dataset_type == 'open_images':
dataset = OpenImagesDataset(dataset_path,
transform=train_transform, target_transform=target_transform,
dataset_type="train", balance_data=args.balance_data)
label_file = os.path.join(args.checkpoint_folder, "labels.txt")
store_labels(label_file, dataset.class_names)
logging.info(dataset)
num_classes = len(dataset.class_names)
else:
raise ValueError(f"Dataset type {args.dataset_type} is not supported.")
datasets.append(dataset)
# create training dataset
logging.info(f"Stored labels into file {label_file}.")
train_dataset = ConcatDataset(datasets)
logging.info("Train dataset size: {}".format(len(train_dataset)))
train_loader = DataLoader(train_dataset, args.batch_size,
num_workers=args.num_workers,
shuffle=True)
# create validation dataset
logging.info("Prepare Validation datasets.")
if args.dataset_type == "voc":
val_dataset = VOCDataset(dataset_path, transform=test_transform,
target_transform=target_transform, is_test=True)
elif args.dataset_type == 'open_images':
val_dataset = OpenImagesDataset(dataset_path,
transform=test_transform, target_transform=target_transform,
dataset_type="test")
logging.info(val_dataset)
logging.info("Validation dataset size: {}".format(len(val_dataset)))
val_loader = DataLoader(val_dataset, args.batch_size,
num_workers=args.num_workers,
shuffle=False)
# create the network
logging.info("Build network.")
net = create_net(num_classes)
min_loss = -10000.0
last_epoch = -1
# prepare eval dataset (for mAP computation)
if args.validation_mean_ap:
if args.dataset_type == "voc":
eval_dataset = VOCDataset(dataset_path, is_test=True)
elif args.dataset_type == 'open_images':
eval_dataset = OpenImagesDataset(dataset_path, dataset_type="test")
eval = MeanAPEvaluator(eval_dataset, net, arch=args.net, eval_dir=os.path.join(args.checkpoint_folder, 'eval_results'))
# freeze certain layers (if requested)
base_net_lr = args.base_net_lr if args.base_net_lr is not None else args.lr
extra_layers_lr = args.extra_layers_lr if args.extra_layers_lr is not None else args.lr
if args.freeze_base_net:
logging.info("Freeze base net.")
freeze_net_layers(net.base_net)
params = itertools.chain(net.source_layer_add_ons.parameters(), net.extras.parameters(),
net.regression_headers.parameters(), net.classification_headers.parameters())
params = [
{'params': itertools.chain(
net.source_layer_add_ons.parameters(),
net.extras.parameters()
), 'lr': extra_layers_lr},
{'params': itertools.chain(
net.regression_headers.parameters(),
net.classification_headers.parameters()
)}
]
elif args.freeze_net:
freeze_net_layers(net.base_net)
freeze_net_layers(net.source_layer_add_ons)
freeze_net_layers(net.extras)
params = itertools.chain(net.regression_headers.parameters(), net.classification_headers.parameters())
logging.info("Freeze all the layers except prediction heads.")
else:
params = [
{'params': net.base_net.parameters(), 'lr': base_net_lr},
{'params': itertools.chain(
net.source_layer_add_ons.parameters(),
net.extras.parameters()
), 'lr': extra_layers_lr},
{'params': itertools.chain(
net.regression_headers.parameters(),
net.classification_headers.parameters()
)}
]
# load a previous model checkpoint (if requested)
timer.start("Load Model")
if args.resume:
logging.info(f"Resuming from the model {args.resume}")
net.load(args.resume)
elif args.base_net:
logging.info(f"Init from base net {args.base_net}")
net.init_from_base_net(args.base_net)
elif args.pretrained_ssd:
logging.info(f"Init from pretrained SSD {args.pretrained_ssd}")
if not os.path.exists(args.pretrained_ssd) and args.pretrained_ssd == DEFAULT_PRETRAINED_MODEL:
os.system(f"wget --quiet --show-progress --progress=bar:force:noscroll --no-check-certificate https://nvidia.box.com/shared/static/djf5w54rjvpqocsiztzaandq1m3avr7c.pth -O {DEFAULT_PRETRAINED_MODEL}")
net.init_from_pretrained_ssd(args.pretrained_ssd)
logging.info(f'Took {timer.end("Load Model"):.2f} seconds to load the model.')
# move the model to GPU
net.to(DEVICE)
# define loss function and optimizer
criterion = MultiboxLoss(config.priors, iou_threshold=0.5, neg_pos_ratio=3,
center_variance=0.1, size_variance=0.2, device=DEVICE)
optimizer = torch.optim.SGD(params, lr=args.lr, momentum=args.momentum,
weight_decay=args.weight_decay)
logging.info(f"Learning rate: {args.lr}, Base net learning rate: {base_net_lr}, "
+ f"Extra Layers learning rate: {extra_layers_lr}.")
# set learning rate policy
if args.scheduler == 'multi-step':
logging.info("Uses MultiStepLR scheduler.")
milestones = [int(v.strip()) for v in args.milestones.split(",")]
scheduler = MultiStepLR(optimizer, milestones=milestones,
gamma=0.1, last_epoch=last_epoch)
elif args.scheduler == 'cosine':
logging.info("Uses CosineAnnealingLR scheduler.")
scheduler = CosineAnnealingLR(optimizer, args.t_max, last_epoch=last_epoch)
else:
logging.fatal(f"Unsupported Scheduler: {args.scheduler}.")
parser.print_help(sys.stderr)
sys.exit(1)
# train for the desired number of epochs
logging.info(f"Start training from epoch {last_epoch + 1}.")
for epoch in range(last_epoch + 1, args.num_epochs):
train(train_loader, net, criterion, optimizer, device=DEVICE, debug_steps=args.debug_steps, epoch=epoch)
scheduler.step()
if epoch % args.validation_epochs == 0 or epoch == args.num_epochs - 1:
val_loss, val_regression_loss, val_classification_loss = test(val_loader, net, criterion, DEVICE)
logging.info(
f"Epoch: {epoch}, " +
f"Validation Loss: {val_loss:.4f}, " +
f"Validation Regression Loss {val_regression_loss:.4f}, " +
f"Validation Classification Loss: {val_classification_loss:.4f}"
)
tensorboard.add_scalar('Loss/val', val_loss, epoch)
tensorboard.add_scalar('Regression Loss/val', val_regression_loss, epoch)
tensorboard.add_scalar('Classification Loss/val', val_classification_loss, epoch)
if args.validation_mean_ap:
mean_ap, class_ap = eval.compute()
eval.log_results(mean_ap, class_ap, f"Epoch: {epoch}, ")
tensorboard.add_scalar('Mean Average Precision/val', mean_ap, epoch)
for i in range(len(class_ap)):
tensorboard.add_scalar(f"Class Average Precision/{eval_dataset.class_names[i+1]}", class_ap[i], epoch)
model_path = os.path.join(args.checkpoint_folder, f"{args.net}-Epoch-{epoch}-Loss-{val_loss}.pth")
net.save(model_path)
logging.info(f"Saved model {model_path}")
logging.info("Task done, exiting program.")
tensorboard.close()
使用方法
所有参数使用默认值训练
python3 train_ssd.py --dataset-type=voc --data=data/drone/ --model-dir=models/drone/ --resolution=512
调整一些参数进行训练
python3 train_ssd.py --dataset-type=voc --data=data/drone/ --model-dir=models/drone_512px_lr001_bs4_epochs1000/ --resolution=512 --num-workers=2 --batch-size=4 --lr=0.01 --epochs=1000
在内存比较小的系统中训练,数据加载的工作线程"–num-workers"要减少,甚至等于0,否则会出错!!!
如在jetson nano中
python3 train_ssd.py --dataset-type=voc --data=data/drone/ --model-dir=models/drone/ --resolution=512 --num-workers=0 --batch-size=4 --epochs=100
注意:训练时传入的分辨率(--resolution)要和采样时图片的分辨率一样,也和转换时传入的分辨率一样,否则效果很差!!!
二、解析代码
加上中文注释
下面是加上中文注释的代码:
```python
#!/usr/bin/env python3
#
# 在Pascal VOC或Open Images数据集上训练SSD检测模型
# https://github.com/dusty-nv/jetson-inference/blob/master/docs/pytorch-ssd.md
#
import os
import sys
import logging
import argparse
import datetime
import itertools
import torch
from torch.utils.data import DataLoader, ConcatDataset
from torch.utils.tensorboard import SummaryWriter
from torch.optim.lr_scheduler import CosineAnnealingLR, MultiStepLR
from vision.utils.misc import Timer, freeze_net_layers, store_labels
from vision.ssd.ssd import MatchPrior
from vision.ssd.vgg_ssd import create_vgg_ssd
from vision.ssd.mobilenetv1_ssd import create_mobilenetv1_ssd
from vision.ssd.mobilenetv1_ssd_lite import create_mobilenetv1_ssd_lite
from vision.ssd.mobilenet_v2_ssd_lite import create_mobilenetv2_ssd_lite
from vision.ssd.squeezenet_ssd_lite import create_squeezenet_ssd_lite
from vision.datasets.voc_dataset import VOCDataset
from vision.datasets.open_images import OpenImagesDataset
from vision.nn.multibox_loss import MultiboxLoss
from vision.ssd.config import vgg_ssd_config
from vision.ssd.config import mobilenetv1_ssd_config
from vision.ssd.config import squeezenet_ssd_config
from vision.ssd.data_preprocessing import TrainAugmentation, TestTransform
from eval_ssd import MeanAPEvaluator
# 默认预训练模型路径
DEFAULT_PRETRAINED_MODEL='models/mobilenet-v1-ssd-mp-0_675.pth'
# 定义参数解析器
parser = argparse.ArgumentParser(
description='使用PyTorch训练单发多盒检测器(SSD)')
# 数据集参数
parser.add_argument("--dataset-type", default="open_images", type=str,
help='指定数据集类型。目前支持voc和open_images。')
parser.add_argument('--datasets', '--data', nargs='+', default=["data"], help='数据集目录路径')
parser.add_argument('--balance-data', action='store_true',
help="通过下采样频繁标签来平衡训练数据。")
# 网络参数
parser.add_argument('--net', default="mb1-ssd",
help="网络架构,可以是mb1-ssd, mb1-ssd-lite, mb2-ssd-lite或vgg16-ssd。")
parser.add_argument('--resolution', type=int, default=300,
help="模型的NxN像素分辨率(仅适用于mb1-ssd)。")
parser.add_argument('--freeze-base-net', action='store_true',
help="冻结基础网络层。")
parser.add_argument('--freeze-net', action='store_true',
help="冻结除预测头之外的所有层。")
parser.add_argument('--mb2-width-mult', default=1.0, type=float,
help='MobilenetV2的宽度乘数')
# 加载预训练基础网络或检查点的参数
parser.add_argument('--base-net', help='预训练的基础模型')
parser.add_argument('--pretrained-ssd', default=DEFAULT_PRETRAINED_MODEL, type=str, help='预训练的基础模型')
parser.add_argument('--resume', default=None, type=str, help='从检查点状态字典文件恢复训练')
# SGD参数
parser.add_argument('--lr', '--learning-rate', default=0.01, type=float,
help='初始学习率')
parser.add_argument('--momentum', default=0.9, type=float,
help='优化器的动量值')
parser.add_argument('--weight-decay', default=5e-4, type=float,
help='SGD的权重衰减')
parser.add_argument('--gamma', default=0.1, type=float,
help='SGD的Gamma更新')
parser.add_argument('--base-net-lr', default=0.001, type=float,
help='基础网络的初始学习率,或使用--lr')
parser.add_argument('--extra-layers-lr', default=None, type=float,
help='基础网络和预测头以外层的初始学习率。')
# 学习率调度器
parser.add_argument('--scheduler', default="cosine", type=str,
help="SGD的调度器。可以是multi-step或cosine")
# 多步调度器的参数
parser.add_argument('--milestones', default="80,100", type=str,
help="MultiStepLR的里程碑")
# 余弦退火调度器的参数
parser.add_argument('--t-max', default=100, type=float,
help='余弦退火调度器的T_max值。')
# 训练参数
parser.add_argument('--batch-size', default=4, type=int,
help='训练的批量大小')
parser.add_argument('--num-epochs', '--epochs', default=30, type=int,
help='训练的周期数')
parser.add_argument('--num-workers', '--workers', default=2, type=int,
help='数据加载时使用的工作线程数')
parser.add_argument('--validation-epochs', default=1, type=int,
help='运行验证的周期数')
parser.add_argument('--validation-mean-ap', action='store_true',
help='在验证期间计算平均精度均值(mAP)')
parser.add_argument('--debug-steps', default=10, type=int,
help='设置调试日志输出频率。')
parser.add_argument('--use-cuda', default=True, action='store_true',
help='使用CUDA进行模型训练')
parser.add_argument('--checkpoint-folder', '--model-dir', default='models/',
help='保存检查点模型的目录')
parser.add_argument('--log-level', default='info', type=str,
help='日志级别,可以是:debug, info, warning, error, critical (默认: info)')
# 解析命令行参数
args = parser.parse_args()
# 配置日志
logging.basicConfig(stream=sys.stdout, level=getattr(logging, args.log_level.upper(), logging.INFO),
format='%(asctime)s - %(message)s', datefmt="%Y-%m-%d %H:%M:%S")
# 设置TensorBoard日志记录器
tensorboard = SummaryWriter(log_dir=os.path.join(args.checkpoint_folder, "tensorboard", f"{datetime.datetime.now().strftime('%Y%m%d_%H%M%S')}"))
# 检查CUDA是否可用,并选择设备
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() and args.use_cuda else "cpu")
if args.use_cuda and torch.cuda.is_available():
torch.backends.cudnn.benchmark = True
logging.info("Using CUDA...")
# 训练函数
def train(loader, net, criterion, optimizer, device, debug_steps=100, epoch=-1):
net.train(True)
train_loss = 0.0
train_regression_loss = 0.0
train_classification_loss = 0.0
running_loss = 0.0
running_regression_loss = 0.0
running_classification_loss = 0.0
num_batches = 0
for i, data in enumerate(loader):
images, boxes, labels = data
images = images.to(device)
boxes = boxes.to(device)
labels = labels.to(device)
optimizer.zero_grad()
confidence, locations = net(images)
regression_loss, classification_loss = criterion(confidence, locations, labels, boxes)
loss = regression_loss + classification_loss
loss.backward()
optimizer.step()
train_loss += loss.item()
train_regression_loss += regression_loss.item()
train_classification_loss += classification_loss.item()
running_loss += loss.item()
running_regression_loss += regression_loss.item()
running_classification_loss += classification_loss.item()
if i and i % debug_steps == 0:
avg_loss = running_loss / debug_steps
avg_reg_loss = running_regression_loss / debug_steps
avg_clf_loss = running_classification_loss / debug_steps
logging.info(
f"Epoch: {epoch}, Step: {i}/{len(loader)}, " +
f"Avg Loss: {avg_loss:.4f}, " +
f"Avg Regression Loss {avg_reg_loss:.4f}, " +
f"Avg Classification Loss: {avg_clf_loss:.4f}"
)
running_loss = 0.0
running_regression_loss = 0.0
running_classification_loss = 0.0
num_batches += 1
train_loss /= num_batches
train_regression_loss /= num_batches
train_classification_loss /= num_batches
logging.info(
f"Epoch: {epoch}, " +
f"Training Loss: {train_loss:.4f}, " +
f"Training Regression Loss {train_regression_loss:.4f}, " +
f"Training Classification Loss: {train_classification_loss:.4f}"
)
tensorboard.add_scalar('Loss/train', train_loss, epoch)
tensorboard.add_scalar('Regression Loss/train', train_regression_loss, epoch)
tensorboard.add_scalar('Classification Loss/train', train_classification_loss, epoch)
# 测试函数
def test(loader, net, criterion, device):
net.eval()
running_loss = 0.0
running_regression_loss = 0.0
running_classification
详细解析
下面是对代码每一部分的详细解析,包括中文注释:
导入必要的模块
import os
import sys
import logging
import argparse
import datetime
import itertools
import torch
from torch.utils.data import DataLoader, ConcatDataset
from torch.utils.tensorboard import SummaryWriter
from torch.optim.lr_scheduler import CosineAnnealingLR, MultiStepLR
from vision.utils.misc import Timer, freeze_net_layers, store_labels
from vision.ssd.ssd import MatchPrior
from vision.ssd.vgg_ssd import create_vgg_ssd
from vision.ssd.mobilenetv1_ssd import create_mobilenetv1_ssd
from vision.ssd.mobilenetv1_ssd_lite import create_mobilenetv1_ssd_lite
from vision.ssd.mobilenet_v2_ssd_lite import create_mobilenetv2_ssd_lite
from vision.ssd.squeezenet_ssd_lite import create_squeezenet_ssd_lite
from vision.datasets.voc_dataset import VOCDataset
from vision.datasets.open_images import OpenImagesDataset
from vision.nn.multibox_loss import MultiboxLoss
from vision.ssd.config import vgg_ssd_config
from vision.ssd.config import mobilenetv1_ssd_config
from vision.ssd.config import squeezenet_ssd_config
from vision.ssd.data_preprocessing import TrainAugmentation, TestTransform
from eval_ssd import MeanAPEvaluator
- 导入操作系统接口(
os、sys) - 导入日志处理模块(
logging) - 导入命令行参数解析模块(
argparse) - 导入日期时间处理模块(
datetime) - 导入用于高效组合迭代工具(
itertools) - 导入PyTorch库(
torch) - 导入数据加载和处理工具(
DataLoader、ConcatDataset) - 导入TensorBoard日志记录工具(
SummaryWriter) - 导入学习率调度器(
CosineAnnealingLR、MultiStepLR) - 导入其他工具和SSD模型相关模块
设置默认预训练模型路径
DEFAULT_PRETRAINED_MODEL='models/mobilenet-v1-ssd-mp-0_675.pth'
- 定义预训练模型的默认路径。
参数解析
parser = argparse.ArgumentParser(description='使用PyTorch训练单发多盒检测器(SSD)')
- 使用
argparse定义命令行参数解析器。
数据集参数
parser.add_argument("--dataset-type", default="open_images", type=str, help='指定数据集类型。目前支持voc和open_images。')
parser.add_argument('--datasets', '--data', nargs='+', default=["data"], help='数据集目录路径')
parser.add_argument('--balance-data', action='store_true', help="通过下采样频繁标签来平衡训练数据。")
- 定义数据集类型、路径和数据平衡参数。
--balance-data参数详细解析
参数 parser.add_argument('--balance-data', action='store_true', help="通过下采样频繁标签来平衡训练数据。") 的详细说明如下:
参数的作用 这个参数用于在训练数据集存在类别不平衡的情况下,通过下采样频繁标签来平衡训练数据。类别不平衡是指某些类别的样本数量远多于其他类别,这可能导致模型在训练过程中偏向预测这些频繁出现的类别,影响模型的泛化能力和准确率。
参数详细解释
--balance-data:这是参数的名称。当在命令行中使用这个参数时,argparse会将其值设置为True。如果不使用这个参数,则其值为False。action='store_true':这意味着当指定--balance-data参数时,args.balance_data的值将被设置为True。如果没有指定,args.balance_data的值将是False。help:这是对参数的简要描述。当使用--help或-h命令行选项时,会显示这段帮助文本。
为什么需要数据平衡 在实际应用中,数据集通常是不平衡的。例如,在目标检测任务中,有些类别的对象可能出现频率很高,而有些类别的对象则很少出现。这种不平衡会导致模型在训练过程中更偏向于预测频繁出现的类别,从而忽视稀有类别,导致模型在稀有类别上的性能较差。
数据平衡的具体方法 通过下采样(down-sampling)频繁标签,可以使每个类别在训练数据中出现的次数更加均衡。具体方法如下:
- 下采样:减少频繁出现的类别样本的数量,使其与稀有类别样本的数量相当。这样可以避免模型对某一类样本过度拟合。
- 上采样(如果需要,可以结合上采样):增加稀有类别样本的数量,使其与频繁类别样本的数量相当。可以通过数据增强(如旋转、翻转、裁剪等)来增加稀有类别的样本数量。
代码示例 在实际代码中,使用 --balance-data 参数可以在加载数据集时进行数据平衡处理。以下是一个简单的示例:
# 假设 args.balance_data 是由命令行参数解析得到的布尔值
if args.balance_data:
logging.info("Balancing training data by down-sampling more frequent labels.")
for dataset_path in args.datasets:
if args.dataset_type == 'voc':
dataset = VOCDataset(dataset_path, transform=train_transform, target_transform=target_transform)
dataset.balance_data() # 假设 VOCDataset 类有一个 balance_data 方法
elif args.dataset_type == 'open_images':
dataset = OpenImagesDataset(dataset_path, transform=train_transform, target_transform=target_transform, dataset_type="train", balance_data=args.balance_data)
datasets.append(dataset) else:
logging.info("Using original training data without balancing.")
for dataset_path in args.datasets:
if args.dataset_type == 'voc':
dataset = VOCDataset(dataset_path, transform=train_transform, target_transform=target_transform)
elif args.dataset_type == 'open_images':
dataset = OpenImagesDataset(dataset_path, transform=train_transform, target_transform=target_transform, dataset_type="train", balance_data=args.balance_data)
datasets.append(dataset) ```
###### 总结 `--balance-data` 参数用于在训练数据中存在类别不平衡的情况下,通过下采样频繁出现的标签来平衡训练数据。这有助于提高模型的泛化能力,使
其在稀有类别上的表现更好。具体实现方式可能会根据数据集和任务的不同而有所差异。
#### 网络参数
```python
parser.add_argument('--net', default="mb1-ssd", help="网络架构,可以是mb1-ssd, mb1-ssd-lite, mb2-ssd-lite或vgg16-ssd。")
parser.add_argument('--resolution', type=int, default=300, help="模型的NxN像素分辨率(仅适用于mb1-ssd)。")
parser.add_argument('--freeze-base-net', action='store_true', help="冻结基础网络层。")
parser.add_argument('--freeze-net', action='store_true', help="冻结除预测头之外的所有层。")
parser.add_argument('--mb2-width-mult', default=1.0, type=float, help='MobilenetV2的宽度乘数')
- 定义网络架构、分辨率、冻结层设置和宽度乘数。
--net参数详细解析
参数 parser.add_argument('--net', default="mb1-ssd", help="网络架构,可以是mb1-ssd, mb1-ssd-lite, mb2-ssd-lite或vgg16-ssd。") 的详细说明如下:
参数的作用 这个参数用于指定训练过程中所使用的神经网络架构。不同的网络架构有不同的特点和适用场景,通过指定合适的网络架构,可以优化模型的性能、训练速度和资源占用。
参数详细解释
--net:这是参数的名称。在命令行中使用这个参数可以指定所需的网络架构。default="mb1-ssd":这是默认值,如果在命令行中没有指定--net参数,则默认使用mb1-ssd架构。help:这是对参数的简要描述。当使用--help或-h命令行选项时,会显示这段帮助文本,解释可以使用的网络架构选项。
可选的网络架构 该参数支持以下几种网络架构:
- mb1-ssd:MobileNetV1-SSD,是一种轻量级的目标检测网络,适合在资源受限的设备(如嵌入式设备和移动设备)上运行。
- mb1-ssd-lite:MobileNetV1-SSD Lite,是
mb1-ssd的轻量化版本,进一步减少了计算量和参数量,适合对资源占用有更高要求的场景。 - mb2-ssd-lite:MobileNetV2-SSD Lite,基于MobileNetV2的架构,同样适用于轻量级目标检测任务,具有更好的特征提取能力。
- vgg16-ssd:基于VGG16的SSD模型,具有较高的精度和较大的计算量,适合在计算资源充足的环境中使用。
如何选择网络架构 选择网络架构时,需要根据具体应用场景和需求考虑以下几点:
- 模型精度:在计算资源允许的情况下,选择精度较高的模型(如
vgg16-ssd)。 - 计算资源:在资源受限的设备上,选择轻量级的模型(如
mb1-ssd、mb1-ssd-lite或mb2-ssd-lite)。 - 推理速度:在实时性要求较高的应用中,选择计算量较小、推理速度较快的模型。
- 任务需求:根据具体的目标检测任务,选择适合的模型架构。例如,对于移动设备上的实时目标检测任务,可以选择
mb1-ssd或mb2-ssd-lite。
代码示例 在代码中,使用 --net 参数可以选择不同的网络架构:
# 根据命令行参数选择网络架构和配置 if args.net == 'vgg16-ssd':
create_net = create_vgg_ssd
config = vgg_ssd_config elif args.net == 'mb1-ssd':
create_net = create_mobilenetv1_ssd
config = mobilenetv1_ssd_config
config.set_image_size(args.resolution) elif args.net == 'mb1-ssd-lite':
create_net = create_mobilenetv1_ssd_lite
config = mobilenetv1_ssd_config elif args.net == 'mb2-ssd-lite':
create_net = lambda num: create_mobilenetv2_ssd_lite(num, width_mult=args.mb2_width_mult)
config = mobilenetv1_ssd_config else:
logging.fatal("The net type is wrong.")
parser.print_help(sys.stderr)
sys.exit(1) ```
###### 总结 `--net` 参数用于指定训练过程中所使用的神经网络架构。选择合适的网络架构可以根据具体应用场景和需求来优化模型的性能、训练速度和资源占用。
不同的网络架构适用于不同的目标检测任务,用户可以根据自身的需求选择合适的架构进行训练。
##### --mb2-width-mul参数的详细解析
参数 `parser.add_argument('--mb2-width-mult', default=1.0, type=float, help='MobilenetV2的宽度乘数')` 的详细解析如下:
###### 参数的作用 这个参数用于调整MobileNetV2网络的宽度乘数(width multiplier)。宽度乘数是一个缩放因子,用于控制网络中每一层的卷积核数量。通过调整宽度乘数,可以在计算效率和模型精度之间进行权衡。参数
--mb2-width-mult 只有在 --net=mb2-ssd-lite 时才起作用。这个参数专门用于调整 MobileNetV2 的宽度乘数,而 mb2-ssd-lite 是基于 MobileNetV2 的网络架构。其他网络架构(如 mb1-ssd, mb1-ssd-lite, vgg16-ssd)不会使用这个参数。
###### 参数详细解释
- `--mb2-width-mult`:这是参数的名称。在命令行中使用这个参数可以指定MobileNetV2网络的宽度乘数。
- `default=1.0`:这是默认值,如果在命令行中没有指定 `--mb2-width-mult` 参数,则默认使用 `1.0` 作为宽度乘数。
- `type=float`:表示这个参数的值应为浮点数。
- `help='MobilenetV2的宽度乘数'`:这是对参数的简要描述。当使用 `--help` 或 `-h` 命令行选项时,会显示这段帮助文本,解释参数的用途。
###### 宽度乘数的作用 宽度乘数用于缩放网络的宽度,即卷积核的数量,从而影响模型的计算复杂度和参数数量。具体来说:
- 当宽度乘数为 `1.0` 时,网络的卷积核数量保持不变,即使用默认的卷积核数量。
- 当宽度乘数小于 `1.0` 时,网络的卷积核数量减少,从而降低计算复杂度和参数数量,但可能会导致模型精度下降。
- 当宽度乘数大于 `1.0` 时,网络的卷积核数量增加,从而提高模型精度,但会增加计算复杂度和参数数量。
###### 选择宽度乘数的考虑
- **计算资源**:在计算资源有限的设备上(如嵌入式设备或移动设备),可以选择较小的宽度乘数以减少计算量。
- **模型精度**:在需要较高精度的任务中,可以选择较大的宽度乘数以提高模型的特征提取能力。
- **实时性要求**:在实时性要求高的应用中,可以选择适中的宽度乘数,既保证一定的模型精度,又满足实时性要求。
###### 代码示例 在实际代码中,可以根据命令行参数设置MobileNetV2的宽度乘数:
```python
# 根据命令行参数选择网络架构和配置 if args.net == 'mb2-ssd-lite':
create_net = lambda num: create_mobilenetv2_ssd_lite(num, width_mult=args.mb2_width_mult)
config = mobilenetv1_ssd_config ```
这里的 `create_mobilenetv2_ssd_lite` 函数需要传入 `width_mult` 参数,用于设置网络的宽度乘数。
###### 使用示例 在命令行中使用不同的宽度乘数: ```bash
# 使用默认宽度乘数 1.0 python train_ssd.py --net mb2-ssd-lite --mb2-width-mult 1.0
# 使用宽度乘数 0.75,减少计算量 python train_ssd.py --net mb2-ssd-lite --mb2-width-mult 0.75
# 使用宽度乘数 1.5,增加模型精度 python train_ssd.py --net mb2-ssd-lite --mb2-width-mult 1.5 ```
###### 总结 `--mb2-width-mult` 参数用于调整MobileNetV2网络的宽度乘数,通过改变每一层的卷积核数量来控制模型的计算复杂度和参数数量。选择合适的宽度乘数可以在计算资源、模型精度和实时性要求之间找到最佳平衡。
#### 加载预训练模型或检查点的参数
```python
parser.add_argument('--base-net', help='预训练的基础模型')
parser.add_argument('--pretrained-ssd', default=DEFAULT_PRETRAINED_MODEL, type=str, help='预训练的基础模型')
parser.add_argument('--resume', default=None, type=str, help='从检查点状态字典文件恢复训练')
- 定义加载预训练基础网络或检查点的参数。
--base-net和--pretrained-ssd参数的详细解析
参数 --base-net 和 --pretrained-ssd 都与预训练模型的加载有关,但它们的作用和使用场景有所不同。下面是对这两个参数的详细解析:
--base-net 参数
parser.add_argument('--base-net', help='预训练的基础模型')
作用
- 定义:这个参数用于指定一个预训练的基础模型文件路径。基础模型通常指的是网络架构的主干部分(backbone),例如 VGG、ResNet 或 MobileNet,而不包括 SSD 的检测头部分。
- 用途:主要用于在训练新的 SSD 模型时,利用一个已经预训练好的基础网络来初始化模型的主干部分。这可以加快训练速度并提升模型性能,因为预训练的基础网络已经学到了有用的特征。
使用示例
在命令行中指定 --base-net 参数:
python train_ssd.py --base-net path/to/pretrained/base_net.pth
在代码中处理 --base-net 参数:
if args.base_net:
logging.info(f"Init from base net {args.base_net}")
net.init_from_base_net(args.base_net)
--pretrained-ssd 参数
parser.add_argument('--pretrained-ssd', default=DEFAULT_PRETRAINED_MODEL, type=str, help='预训练的基础模型')
作用
- 定义:这个参数用于指定一个完整的预训练 SSD 模型文件路径,包括基础网络和检测头。默认值为
DEFAULT_PRETRAINED_MODEL。 - 用途:用于加载一个完整的预训练 SSD 模型来进行微调或继续训练。与
--base-net不同,--pretrained-ssd加载的是一个完整的 SSD 模型,包含了基础网络和检测头的权重。
使用示例
在命令行中指定 --pretrained-ssd 参数:
python train_ssd.py --pretrained-ssd path/to/pretrained/ssd.pth
在代码中处理 --pretrained-ssd 参数:
if args.pretrained_ssd:
logging.info(f"Init from pretrained SSD {args.pretrained_ssd}")
if not os.path.exists(args.pretrained_ssd) and args.pretrained_ssd == DEFAULT_PRETRAINED_MODEL:
os.system(f"wget --quiet --show-progress --progress=bar:force:noscroll --no-check-certificate https://nvidia.box.com/shared/static/djf5w54rjvpqocsiztzaandq1m3avr7c.pth -O {DEFAULT_PRETRAINED_MODEL}")
net.init_from_pretrained_ssd(args.pretrained_ssd)
二者对比
| 参数 | 用途 | 适用场景 |
|---|---|---|
--base-net |
只加载预训练的基础网络,不包括检测头 | 在已有预训练的基础网络上构建新的 SSD 模型 |
--pretrained-ssd |
加载完整的预训练 SSD 模型,包括基础网络和检测头 | 进行微调或继续训练已有的完整 SSD 模型 |
代码示例
在实际代码中,这两个参数的使用方式如下:
# 解析命令行参数
args = parser.parse_args()
# 初始化模型
if args.resume:
logging.info(f"Resuming from the model {args.resume}")
net.load(args.resume)
elif args.base_net:
logging.info(f"Init from base net {args.base_net}")
net.init_from_base_net(args.base_net)
elif args.pretrained_ssd:
logging.info(f"Init from pretrained SSD {args.pretrained_ssd}")
if not os.path.exists(args.pretrained_ssd) and args.pretrained_ssd == DEFAULT_PRETRAINED_MODEL:
os.system(f"wget --quiet --show-progress --progress=bar:force:noscroll --no-check-certificate https://nvidia.box.com/shared/static/djf5w54rjvpqocsiztzaandq1m3avr7c.pth -O {DEFAULT_PRETRAINED_MODEL}")
net.init_from_pretrained_ssd(args.pretrained_ssd)
基础网络和检测头
在目标检测任务中,基础网络(backbone)和检测头(detection head)是两个关键组件。它们在不同的阶段执行不同的功能,结合起来完成目标检测任务。
基础网络(Backbone)
基础网络是一个预训练的卷积神经网络(CNN),用于提取输入图像的特征。基础网络通常在大型图像分类数据集(如ImageNet)上预训练,以学习到丰富的特征表示。常见的基础网络包括VGG、ResNet、MobileNet等。
功能
- 特征提取:基础网络的主要功能是从输入图像中提取特征图(feature maps),这些特征图包含了输入图像的低级和高级特征,如边缘、纹理和对象形状。
- 多层特征:基础网络通常包含多个卷积层和池化层,这些层级联起来形成多层特征表示。较浅的层捕捉低级特征,较深的层捕捉高级特征。
检测头(Detection Head)
检测头是附加在基础网络上的一组层,用于完成具体的目标检测任务。检测头使用基础网络提取的特征图来预测目标的边界框和类别。
功能
- 边界框回归:检测头包含回归层,用于预测目标在图像中的位置,即目标的边界框。
- 类别预测:检测头还包含分类层,用于预测目标的类别,即识别图像中的目标属于哪个类别。
- 多尺度检测:检测头通常设计成多尺度的,以便检测不同大小的目标。SSD(Single Shot MultiBox Detector)就是一个典型的多尺度检测头。
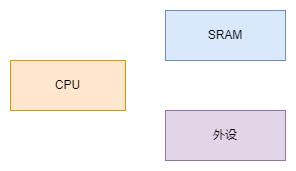
结构示意图
输入图像
|
v
基础网络 (Backbone)
|
v
特征图 (Feature Maps)
|
v
检测头 (Detection Head)
|
v
预测结果 (Predictions: 类别 + 边界框)
示例
以SSD模型为例,描述基础网络和检测头的结构:
基础网络(Backbone):
- 使用VGG16或MobileNet等预训练的卷积神经网络。
- 提取输入图像的多尺度特征图。
检测头(Detection Head):
- 在不同尺度的特征图上添加卷积层。
- 每个特征图上的卷积层输出边界框的坐标和类别得分。
- 通过多尺度的预测实现对不同大小目标的检测。
代码示例
以下是如何使用基础网络和检测头初始化SSD模型的示例代码:
# 定义SSD模型
class SSD(nn.Module):
def __init__(self, backbone, num_classes):
super(SSD, self).__init__()
self.backbone = backbone # 基础网络
self.detection_head = DetectionHead(num_classes) # 检测头
def forward(self, x):
features = self.backbone(x) # 提取特征
predictions = self.detection_head(features) # 生成检测结果
return predictions
# 初始化基础网络和检测头
backbone = create_vgg_backbone() # 创建VGG基础网络
ssd_model = SSD(backbone, num_classes=21) # 初始化SSD模型,检测头有21个类别
加载预训练的基础网络和检测头
使用预训练的基础网络和检测头,可以加快模型训练并提升性能:
if args.base_net:
logging.info(f"Init from base net {args.base_net}")
net.init_from_base_net(args.base_net) # 加载预训练的基础网络权重
if args.pretrained_ssd:
logging.info(f"Init from pretrained SSD {args.pretrained_ssd}")
net.init_from_pretrained_ssd(args.pretrained_ssd) # 加载预训练的完整SSD模型
总结
- 基础网络(Backbone):主要负责从输入图像中提取特征,常用预训练模型如VGG、ResNet、MobileNet等。
- 检测头(Detection Head):利用基础网络提取的特征,进行边界框回归和类别预测,完成具体的目标检测任务。
- 结合预训练的基础网络和检测头,可以有效提高模型的性能和训练效率。
总结
--base-net参数用于加载预训练的基础网络,在训练新的 SSD 模型时提供一个已经学到有用特征的起点。--pretrained-ssd参数用于加载完整的预训练 SSD 模型,包括基础网络和检测头,用于微调或继续训练。- 这两个参数都可以显著加速训练过程,提高模型性能,但适用的场景有所不同,需要根据具体需求选择使用哪个参数。
SGD参数
parser.add_argument('--lr', '--learning-rate', default=0.01, type=float, help='初始学习率')
parser.add_argument('--momentum', default=0.9, type=float, help='优化器的动量值')
parser.add_argument('--weight-decay', default=5e-4, type=float, help='SGD的权重衰减')
parser.add_argument('--gamma', default=0.1, type=float, help='SGD的Gamma更新')
parser.add_argument('--base-net-lr', default=0.001, type=float, help='基础网络的初始学习率,或使用--lr')
parser.add_argument('--extra-layers-lr', default=None, type=float, help='基础网络和预测头以外层的初始学习率。')
- 定义学习率、动量、权重衰减等参数。
学习率调度器参数
parser.add_argument('--scheduler', default="cosine", type=str, help="SGD的调度器。可以是multi-step或cosine")
parser.add_argument('--milestones', default="80,100", type=str, help="MultiStepLR的里程碑")
parser.add_argument('--t-max', default=100, type=float, help='余弦退火调度器的T_max值。')
- 定义学习率调度器及其相关参数。
训练参数
parser.add_argument('--batch-size', default=4, type=int, help='训练的批量大小')
parser.add_argument('--num-epochs', '--epochs', default=30, type=int, help='训练的周期数')
parser.add_argument('--num-workers', '--workers', default=2, type=int, help='数据加载时使用的工作线程数')
parser.add_argument('--validation-epochs', default=1, type=int, help='运行验证的周期数')
parser.add_argument('--validation-mean-ap', action='store_true', help='在验证期间计算平均精度均值(mAP)')
parser.add_argument('--debug-steps', default=10, type=int, help='设置调试日志输出频率。')
parser.add_argument('--use-cuda', default=True, action='store_true', help='使用CUDA进行模型训练')
parser.add_argument('--checkpoint-folder', '--model-dir', default='models/', help='保存检查点模型的目录')
parser.add_argument('--log-level', default='info', type=str, help='日志级别,可以是:debug, info, warning, error, critical (默认: info)')
- 定义批量大小、周期数、数据加载线程数、验证周期、调试日志输出频率等参数。
--batch-size参数的详细解析
参数 --batch-size 的详细解析如下:
参数的作用
--batch-size 参数用于指定训练过程中每个批次(batch)包含的样本数量。批量大小是深度学习训练过程中的一个关键超参数,直接影响模型训练的效率、内存占用和训练稳定性。
参数详细解释
--batch-size:这是参数的名称。在命令行中使用这个参数可以指定训练时的批量大小。default=4:这是默认值,如果在命令行中没有指定--batch-size参数,则默认使用4作为批量大小。type=int:表示这个参数的值应为整数。help='训练的批量大小':这是对参数的简要描述。当使用--help或-h命令行选项时,会显示这段帮助文本,解释参数的用途。
批量大小的影响
批量大小对深度学习模型的训练有多方面的影响:
训练效率:
- 大批量(Large Batch Size):较大的批量大小可以更高效地利用硬件资源(如GPU),减少参数更新的频率,从而加快训练过程。
- 小批量(Small Batch Size):较小的批量大小通常会增加参数更新的频率,使模型参数更快地进行调整,但每次更新计算量较小,可能导致训练时间较长。
内存占用:
- 大批量:较大的批量大小需要更多的显存(GPU内存)来存储每批次的样本数据和梯度信息。如果显存不足,可能会导致内存溢出。
- 小批量:较小的批量大小占用较少的显存,适合在显存较小的硬件设备上训练模型。
训练稳定性:
- 大批量:较大的批量大小会使每次参数更新更平稳,收敛过程更稳定,但可能会陷入局部最优解。
- 小批量:较小的批量大小会引入更多的噪声,使参数更新更频繁,可能帮助模型跳出局部最优解,但也可能导致训练过程不稳定。
模型性能:
- 批量大小的选择可以影响模型的最终性能。通常需要通过实验调整批量大小,以找到最佳的训练效果。
代码示例
在命令行中指定 --batch-size 参数:
# 使用批量大小为 4
python train_ssd.py --batch-size 4
# 使用批量大小为 16
python train_ssd.py --batch-size 16
在代码中处理 --batch-size 参数:
# 解析命令行参数
args = parser.parse_args()
# 配置数据加载器
train_loader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, num_workers=args.num_workers)
val_loader = DataLoader(val_dataset, batch_size=args.batch_size, shuffle=False, num_workers=args.num_workers)
总结
--batch-size参数用于指定训练过程中每个批次包含的样本数量。- 批量大小影响训练效率、内存占用、训练稳定性和模型性能。
- 根据硬件资源和具体任务需求选择合适的批量大小,通常需要通过实验调整以找到最佳值。
配置日志和TensorBoard
args = parser.parse_args()
logging.basicConfig(stream=sys.stdout, level=getattr(logging, args.log_level.upper(), logging.INFO),
format='%(asctime)s - %(message)s', datefmt="%Y-%m-%d %H:%M:%S")
tensorboard = SummaryWriter(log_dir=os.path.join(args.checkpoint_folder, "tensorboard", f"{datetime.datetime.now().strftime('%Y%m%d_%H%M%S')}"))
- 解析命令行参数,配置日志级别和格式,设置TensorBoard日志记录器。
设备选择
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() and args.use_cuda else "cpu")
if args.use_cuda and torch.cuda.is_available():
torch.backends.cudnn.benchmark = True
logging.info("Using CUDA...")
- 检查CUDA是否可用,并选择相应的设备。
训练函数
def train(loader, net, criterion, optimizer, device, debug_steps=100, epoch=-1):
net.train(True)
train_loss = 0.0
train_regression_loss = 0.0
train_classification_loss = 0.0
running_loss = 0.0
running_regression_loss = 0.0
running_classification_loss = 0.0
num_batches = 0
for i, data in enumerate(loader):
images, boxes, labels = data
images = images.to(device)
boxes = boxes.to(device)
labels = labels.to(device)
optimizer.zero_grad()
confidence, locations = net(images)
regression_loss, classification_loss = criterion(confidence, locations, labels, boxes)
loss = regression_loss + classification_loss
loss.backward()
optimizer.step()
train_loss += loss.item()
train_regression_loss += regression_loss.item()
train_classification_loss += classification_loss.item()
running_loss += loss.item()
running_regression_loss += regression_loss.item()
running_classification_loss += classification_loss.item()
if i and i % debug_steps == 0:
avg_loss = running_loss / debug_steps
avg_reg_loss = running_regression_loss / debug_steps
avg_clf_loss = running_classification_loss / debug_steps
logging.info(
f"Epoch: {epoch}, Step: {i}/{len(loader)}, " +
f"Avg Loss: {avg_loss:.4
定义预训练模型对训练自己的模型有什么用
定义预训练模型对训练自己的模型有以下几个重要的作用:
1. 加速训练
预训练模型已经在大型数据集(如ImageNet)上训练过,因此它们的参数已经优化到某种程度。将预训练模型作为起点,可以显著减少训练时间,因为模型已经具备了一些通用的特征提取能力。
2. 提高模型性能
预训练模型在大型数据集上学到了有用的特征,这些特征可以迁移到新的任务中。这种迁移学习可以提高新任务的模型性能,特别是在目标数据集较小或标注数据较少的情况下。
3. 避免过拟合
当数据集较小时,从头开始训练模型可能导致过拟合,因为模型容易记住训练数据的细节而不能泛化到新数据。预训练模型由于在大量数据上训练过,具备更好的泛化能力,有助于减少过拟合的风险。
4. 适用于不同任务
预训练模型可以用于不同的任务,通过微调(fine-tuning)适应特定任务的需求。例如,可以将预训练的图像分类模型用于目标检测任务,通过在检测数据集上微调模型的参数,使其能够更好地执行目标检测任务。
使用预训练模型的典型流程
- 加载预训练模型:从预训练模型文件中加载权重。
- 微调模型:根据具体任务对模型进行微调。例如,在目标检测任务中,调整模型的最后几层或增加新的层,以适应目标检测的需求。
- 冻结部分层:在训练过程中,可以冻结模型的部分层,使其参数保持不变,只训练新增的层或最后几层。这可以防止对预训练特征的过度调整。
- 训练和评估:在目标数据集上训练微调后的模型,并评估其性能。
示例
在代码中,可以看到如何使用预训练模型进行微调:
# 加载预训练模型
if args.resume:
logging.info(f"Resuming from the model {args.resume}")
net.load(args.resume)
elif args.base_net:
logging.info(f"Init from base net {args.base_net}")
net.init_from_base_net(args.base_net)
elif args.pretrained_ssd:
logging.info(f"Init from pretrained SSD {args.pretrained_ssd}")
if not os.path.exists(args.pretrained_ssd) and args.pretrained_ssd == DEFAULT_PRETRAINED_MODEL:
os.system(f"wget --quiet --show-progress --progress=bar:force:noscroll --no-check-certificate https://nvidia.box.com/shared/static/djf5w54rjvpqocsiztzaandq1m3avr7c.pth -O {DEFAULT_PRETRAINED_MODEL}")
net.init_from_pretrained_ssd(args.pretrained_ssd)
args.resume:从之前的训练检查点恢复训练。args.base_net:使用预训练的基础网络初始化模型。args.pretrained_ssd:使用预训练的SSD模型初始化。
通过这些步骤,可以有效利用预训练模型的优势,加快训练过程,提高模型性能,并减少过拟合风险。
预训练模型还可以定义哪些
预训练模型的定义和选择取决于具体任务和使用场景。以下是一些关键点:
可以定义的预训练模型
- 通用图像分类模型:如在ImageNet数据集上训练的ResNet、VGG、Inception等,这些模型可以用于图像分类任务或作为特征提取器用于其他视觉任务。
- 目标检测模型:如在COCO数据集上训练的Faster R-CNN、SSD、YOLO等,这些模型可以用于目标检测任务。
- 语义分割模型:如在PASCAL VOC或Cityscapes数据集上训练的FCN、UNet、DeepLab等,这些模型可以用于语义分割任务。
- 自然语言处理模型:如在大规模语料库上训练的BERT、GPT、RoBERTa等,这些模型可以用于文本分类、生成、问答等任务。
- 其他领域特定模型:如人脸识别、视频处理、语音识别等领域的预训练模型。
如何选择预训练模型
- 任务匹配:选择在与当前任务相似的数据集上预训练的模型。例如,使用在ImageNet上预训练的模型进行图像分类或使用在COCO上预训练的模型进行目标检测。
- 模型架构:根据具体需求选择合适的模型架构。例如,轻量级任务可以选择MobileNet,精度要求高的任务可以选择ResNet或Inception。
- 社区支持:选择有良好社区支持和文档的预训练模型,可以获得更多帮助和资源。
- 可用性:选择容易获得和加载的预训练模型,有些模型可能在特定框架(如PyTorch、TensorFlow)中有官方实现和预训练权重。
不定义预训练模型行不行
可以不使用预训练模型,但需要考虑以下几点:
- 训练时间:从头开始训练模型通常需要更多的时间和计算资源,因为模型参数需要从随机初始化开始进行大量优化。
- 数据需求:从头训练模型通常需要大量的数据,以确保模型能够学到有效的特征。如果数据集较小,可能无法训练出高性能的模型。
- 性能:预训练模型由于在大规模数据上已经训练过,通常具有较好的初始性能和泛化能力。从头训练的模型可能需要更长时间才能达到类似的性能,甚至可能无法达到相同的水平。
示例代码
以下是使用预训练模型与不使用预训练模型的对比:
使用预训练模型:
# 使用预训练的SSD模型初始化
pretrained_model_path = 'models/mobilenet-v1-ssd-mp-0_675.pth'
net = create_mobilenetv1_ssd(num_classes)
net.init_from_pretrained_ssd(pretrained_model_path)
不使用预训练模型(从头训练):
# 从头初始化模型(没有预训练权重)
net = create_mobilenetv1_ssd(num_classes)
总结
预训练模型可以显著加速训练过程、提高模型性能并减少过拟合风险。选择预训练模型时,需要根据任务类型、模型架构、社区支持和可用性等因素进行综合考虑。在某些情况下,可以选择不使用预训练模型,但需要更多的训练时间和数据,且性能可能不如使用预训练模型。
























![【代码随想录】【算法训练营】【第37天】 [56]合并区间 [738]单调递增的数字 [968]监控二叉树](https://img-blog.csdnimg.cn/direct/6e0e96395e9e413b9b473caf2dd8ec58.png)