Hadoop分布式文件系统(HDFS)是Apache Hadoop项目的核心组件,它为大数据存储提供了一个可靠、可扩展的存储解决方案。本文将详细介绍HDFS的读写数据流程,包括数据的存储原理、读写过程以及优化策略。
一、HDFS简介
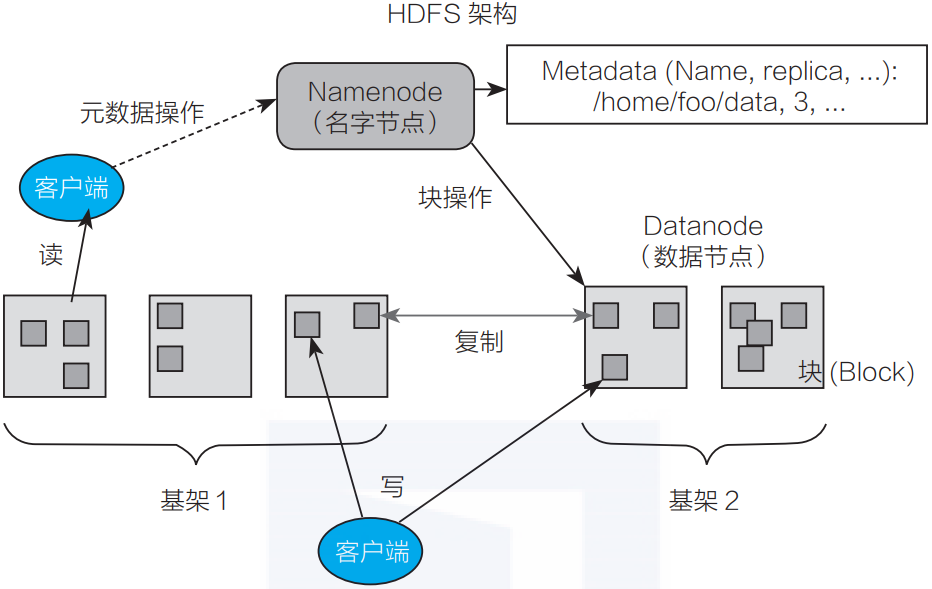
HDFS是一个高度容错的分布式文件系统,它设计用于运行在通用硬件上。HDFS将数据分割成固定大小的块,并将这些块存储在多个节点上,以实现数据的高可用性和可扩展性。每个数据块都会被复制到多个节点上,形成一个副本集,从而确保数据的可靠性。
二、HDFS存储原理
HDFS将文件存储在一个由多个节点组成的集群中。这些节点分为两类:NameNode和DataNode。NameNode是HDFS的主节点,负责管理文件系统的命名空间和客户端的请求。它维护了一个文件系统树,记录了文件和目录的元数据信息。DataNode是HDFS的工作节点,负责存储实际的数据块。
当一个文件被存储在HDFS中时,HDFS会按照一定的块大小(如128MB或256MB)将文件分割成多个数据块。每个数据块都会被复制到多个DataNode上,形成一个副本集。副本集的数量可以根据数据的重要性和集群的容量来配置。
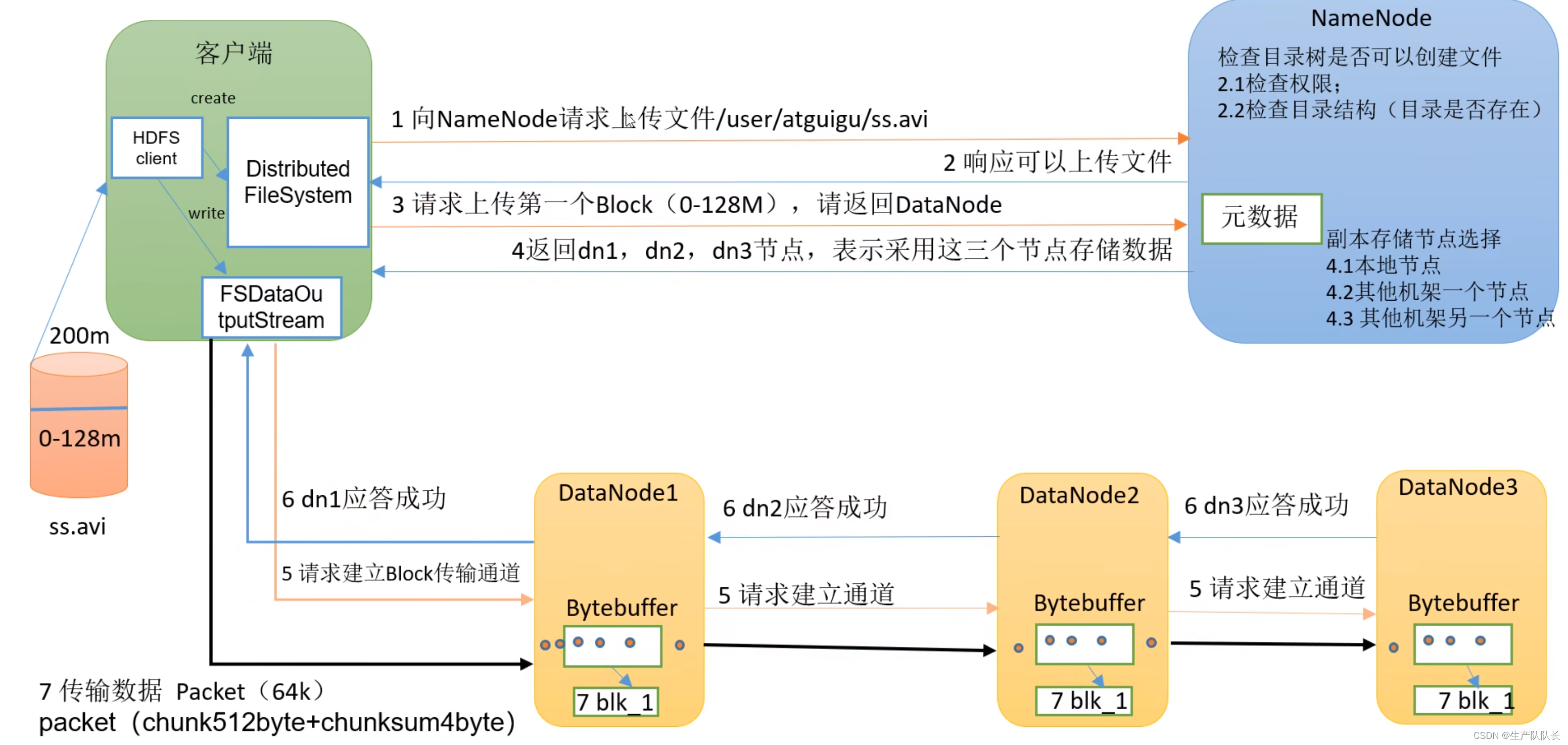
三、HDFS读写数据流程
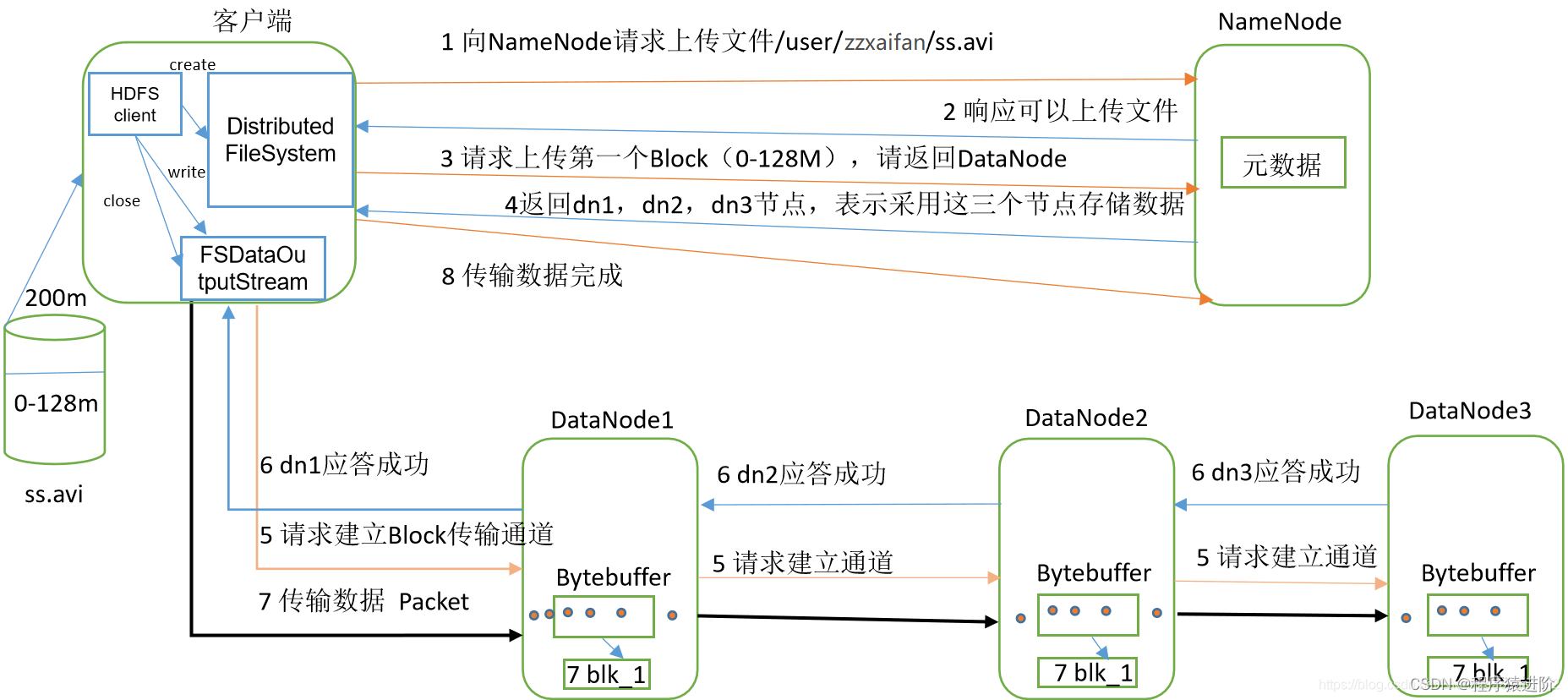
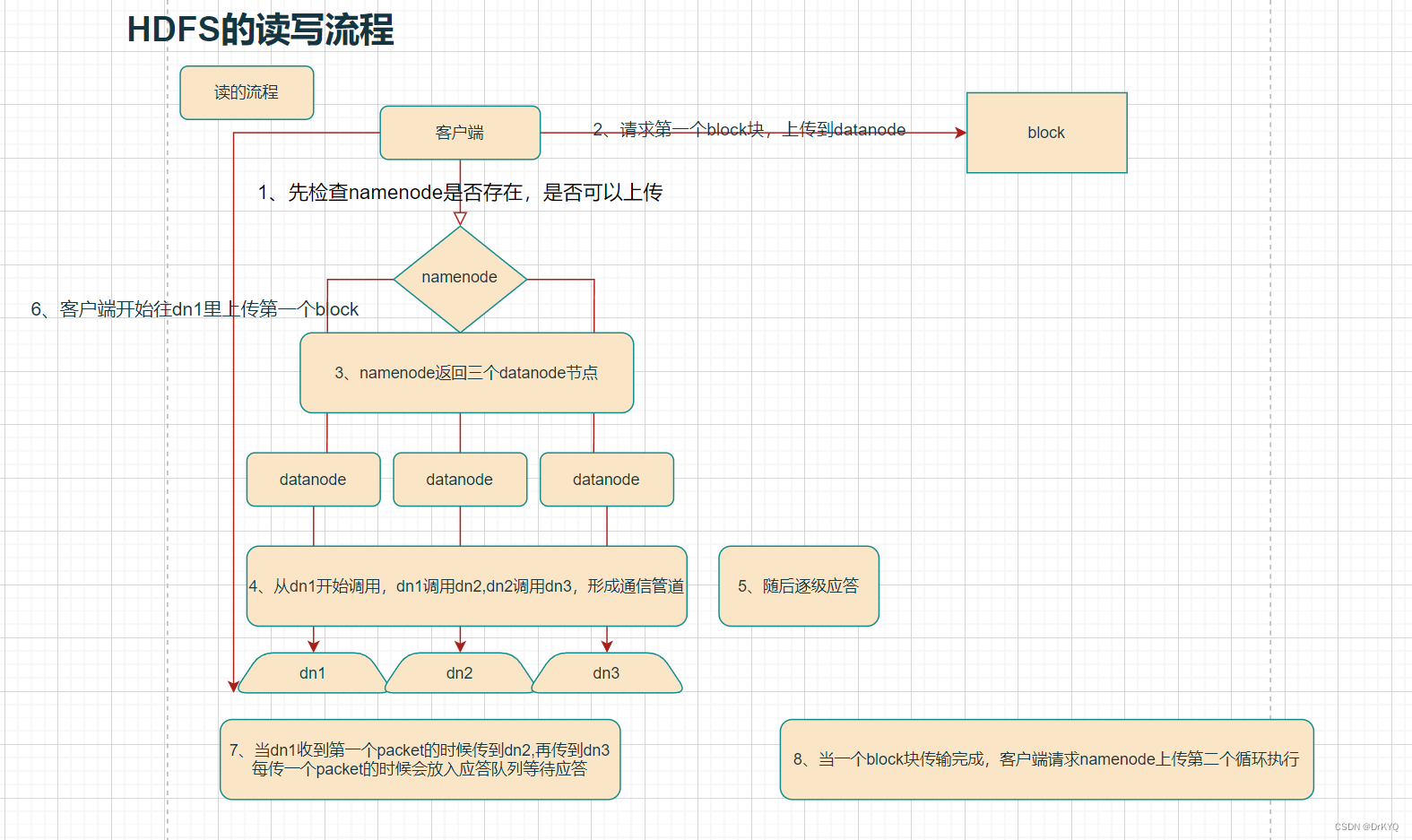
数据写入流程:
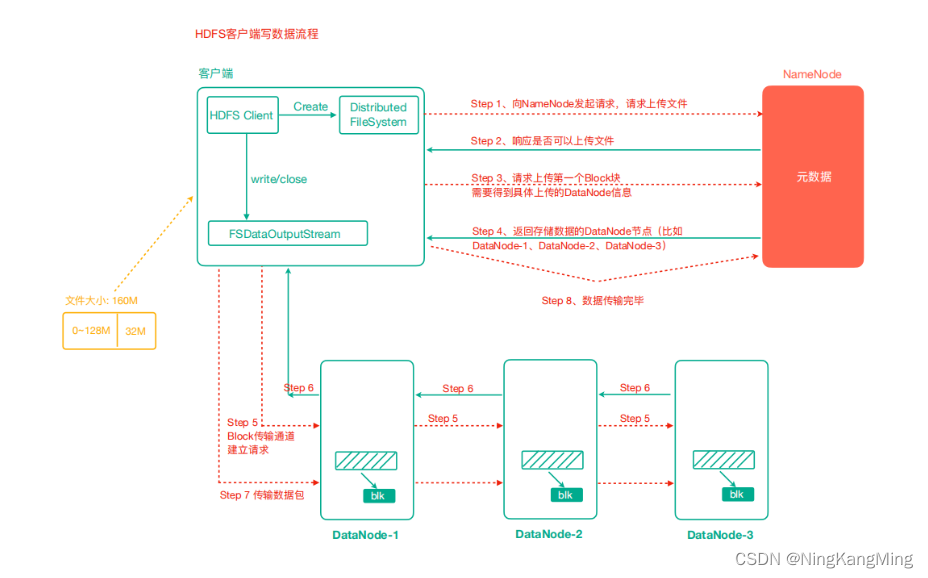
- 客户端通过Distributed FileSystem模块向HDFS发送写请求,指定要写入的文件名和内容。
- NameNode接收到请求后,会检查文件是否存在,如果不存在,则创建新文件,并分配一个文件