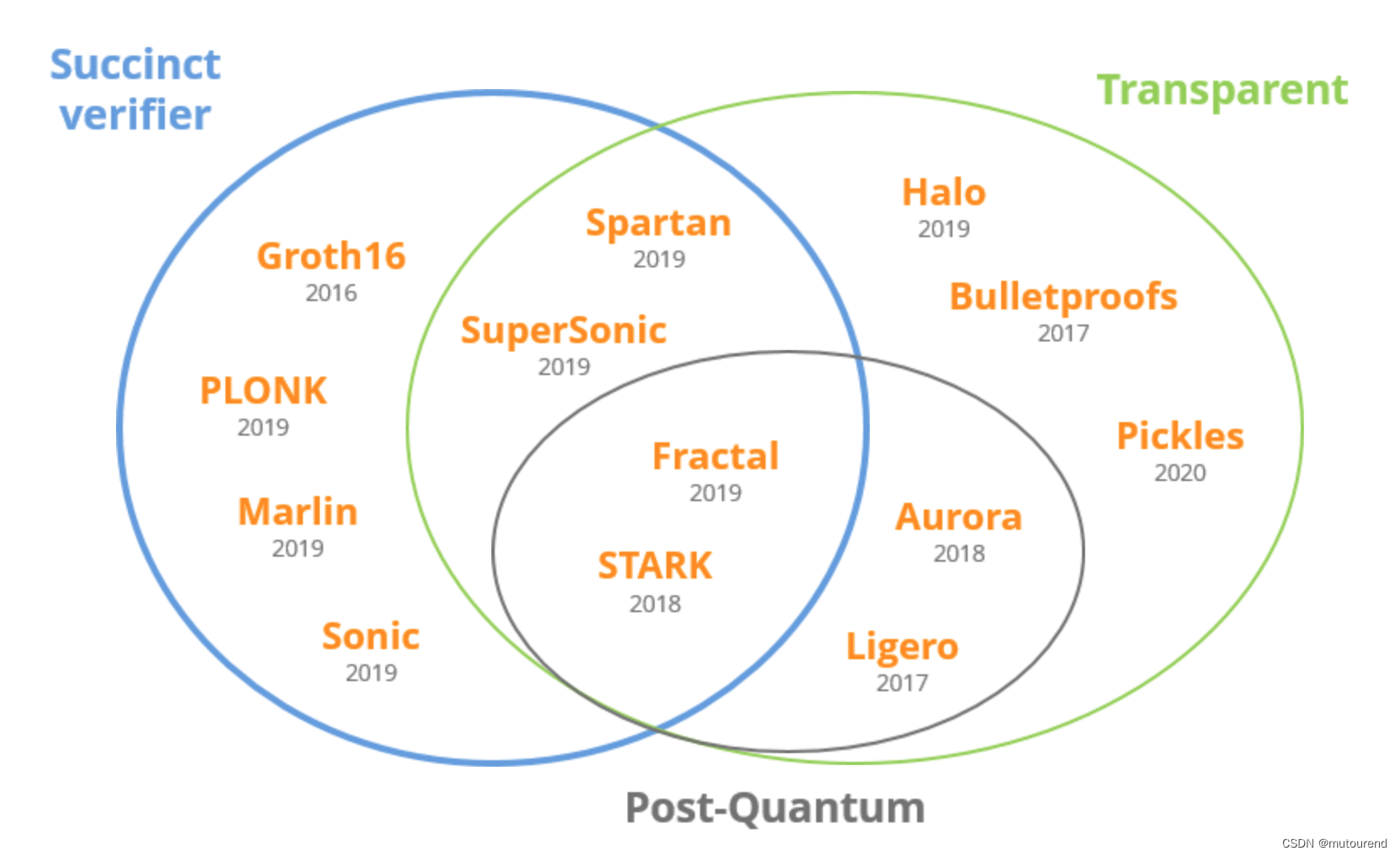
在图论中,最短路径和最小生成树问题是两个重要的课题。本文将介绍三种经典的算法:Dijkstra、Prim和Kruskal,并对它们进行对比分析。我们将讨论这些算法解决的问题、各自的优劣性以及它们之间的异同点,并提供完整的代码示例。
Dijkstra算法
Dijkstra算法用于解决单源最短路径问题,即从图中的一个顶点出发,找到到其他所有顶点的最短路径。
Dijkstra算法的工作原理:
- 初始化:将源点到自己的距离设为0,其他所有顶点到源点的距离设为无穷大。
- 优先队列:使用一个优先队列存储顶点,按照当前最短路径距离进行排序。
- 松弛操作:从优先队列中取出距离最小的顶点,更新与其相邻的顶点的最短路径距离。
- 重复:重复上述步骤,直到优先队列为空。
Java代码示例:
import java.util.*;
public class Dijkstra {
public static int[] dijkstra(Graph graph, int source) {
int V = graph.size();
int[] distTo = new int[V];
boolean[] visited = new boolean[V];
Arrays.fill(distTo, Integer.MAX_VALUE);
distTo[source] = 0;
PriorityQueue<Node> pq = new PriorityQueue<>();
pq.add(new Node(source, 0));
while (!pq.isEmpty()) {
Node node = pq.poll();
int v = node.vertex;
if (visited[v]) continue;
visited[v] = true;
for (Graph.Edge edge : graph.getEdges(v)) {
int w = edge.to;
if (visited[w]) continue;
relax(edge, v, w, distTo, pq);
}
}
return distTo;
}
private static void relax(Graph.Edge edge, int v, int w, int[] distTo, PriorityQueue<Node> pq) {
if (distTo[v] + edge.weight < distTo[w]) {
distTo[w] = distTo[v] + edge.weight;
pq.add(new Node(w, distTo[w]));
}
}
static class Node implements Comparable<Node> {
int vertex;
int distance;
Node(int vertex, int distance) {
this.vertex = vertex;
this.distance = distance;
}
@Override
public int compareTo(Node other) {
return Integer.compare(this.distance, other.distance);
}
}
public static void main(String[] args) {
Graph graph = new Graph(5);
graph.addEdge(0, 1, 10);
graph.addEdge(0, 3, 30);
graph.addEdge(0, 4, 100);
graph.addEdge(1, 2, 50);
graph.addEdge(2, 4, 10);
graph.addEdge(3, 2, 20);
graph.addEdge(3, 4, 60);
int source = 0;
int[] distances = dijkstra(graph, source);
System.out.println("Vertex\tDistance from Source");
for (int i = 0; i < distances.length; i++) {
System.out.println(i + "\t" + distances[i]);
}
}
}
Prim算法
Prim算法用于解决最小生成树(MST)问题,即在一个无向连通图中找到一棵权重最小的生成树。
Prim算法的工作原理:
- 初始化:选择任意一个顶点作为起始点,将其距离设为0,其他顶点距离设为无穷大。
- 优先队列:使用一个优先队列存储顶点,按照当前最短边的权重进行排序。
- 扫描并更新:从优先队列中取出距离最小的顶点,更新与其相邻的尚未加入树的顶点的最短边权重。
- 重复:重复上述步骤,直到所有顶点都加入生成树。
Java代码示例:
import java.util.*;
public class PrimMST {
private Edge[] edgeTo;
private double[] distTo;
private boolean[] marked;
private PriorityQueue<Node> pq;
public PrimMST(Graph G, int s) {
edgeTo = new Edge[G.size()];
distTo = new double[G.size()];
marked = new boolean[G.size()];
pq = new PriorityQueue<>();
Arrays.fill(distTo, Double.POSITIVE_INFINITY);
distTo[s] = 0.0;
pq.add(new Node(s, 0.0));
while (!pq.isEmpty()) {
int v = pq.poll().vertex;
scan(G, v);
}
}
private void scan(Graph G, int v) {
marked[v] = true;
for (Graph.Edge e : G.getEdges(v)) {
int w = e.to;
if (marked[w]) continue;
if (e.weight < distTo[w]) {
distTo[w] = e.weight;
edgeTo[w] = e;
pq.add(new Node(w, distTo[w]));
}
}
}
static class Node implements Comparable<Node> {
int vertex;
double distance;
Node(int vertex, double distance) {
this.vertex = vertex;
this.distance = distance;
}
@Override
public int compareTo(Node other) {
return Double.compare(this.distance, other.distance);
}
}
public Iterable<Edge> edges() {
List<Edge> mst = new ArrayList<>();
for (Edge e : edgeTo) {
if (e != null) mst.add(e);
}
return mst;
}
public double weight() {
double weight = 0.0;
for (Edge e : edges()) {
weight += e.weight;
}
return weight;
}
public static void main(String[] args) {
Graph graph = new Graph(5);
graph.addEdge(0, 1, 10);
graph.addEdge(0, 3, 30);
graph.addEdge(0, 4, 100);
graph.addEdge(1, 2, 50);
graph.addEdge(2, 4, 10);
graph.addEdge(3, 2, 20);
graph.addEdge(3, 4, 60);
PrimMST mst = new PrimMST(graph, 0);
System.out.println("Edges in MST:");
for (Edge e : mst.edges()) {
System.out.println(e);
}
System.out.println("Total weight of MST: " + mst.weight());
}
}
Kruskal算法
Kruskal算法也是解决最小生成树问题的另一种算法。它通过逐步添加最小权重的边来构建生成树。
Kruskal算法的工作原理:
- 排序边:将图中的所有边按权重从小到大排序。
- 并查集:使用并查集结构来检测是否形成环路。
- 选择边:从小到大选择边,若加入该边不形成环路,则将其加入生成树。
- 重复:重复上述步骤,直到生成树包含
V-1条边(V为顶点数)。
Java代码示例:
import java.util.*;
public class KruskalMST {
private List<Edge> mst = new ArrayList<>();
public KruskalMST(Graph G) {
PriorityQueue<Edge> pq = new PriorityQueue<>(Comparator.comparingInt(e -> e.weight));
for (List<Edge> edges : G.adjList) {
pq.addAll(edges);
}
UnionFind uf = new UnionFind(G.size());
while (!pq.isEmpty() && mst.size() < G.size() - 1) {
Edge e = pq.poll();
int v = e.from;
int w = e.to;
if (!uf.isConnected(v, w)) {
uf.union(v, w);
mst.add(e);
}
}
}
public Iterable<Edge> edges() {
return mst;
}
public double weight() {
double weight = 0.0;
for (Edge e : mst) {
weight += e.weight;
}
return weight;
}
public static void main(String[] args) {
Graph graph = new Graph(5);
graph.addEdge(0, 1, 10);
graph.addEdge(0, 3, 30);
graph.addEdge(0, 4, 100);
graph.addEdge(1, 2, 50);
graph.addEdge(2, 4, 10);
graph.addEdge(3, 2, 20);
graph.addEdge(3, 4, 60);
KruskalMST mst = new KruskalMST(graph);
System.out.println("Edges in MST:");
for (Edge e : mst.edges()) {
System.out.println(e);
}
System.out.println("Total weight of MST: " + mst.weight());
}
}
class UnionFind {
private int[] parent;
public UnionFind(int n) {
parent = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = -1;
}
}
public void validate(int v1) {
if (v1 < 0 || v1 >= parent.length) {
throw new IndexOutOfBoundsException("Index " + v1 + " is not valid.");
}
}
public int sizeOf(int v1) {
validate(v1);
int root = find(v1);
return -parent[root];
}
public int parent(int v1) {
validate(v1);
return parent[v1];
}
public boolean isConnected(int v1, int v2) {
validate(v1);
validate(v2);
return find(v1) == find(v2);
}
public void union(int v1, int v2) {
validate(v1);
validate(v2);
int root1 = find(v1);
int root2 = find(v2);
if (root1 == root2) {
return;
}
int size1 = -parent[root1];
int size2 = -parent[root2];
if (size1 <= size2) {
parent[root1] = root2;
parent[root2] = -(size1 + size2);
} else {
parent[root2] = root1;
parent[root1] = -(size1 + size2);
}
}
public int find(int v1) {
validate(v1);
if (parent[v1] < 0) {
return v1;
}
parent[v1] = find(parent[v1]);
return parent[v1];
}
}
Graph类的定义
为了完整性,我们需要定义一个Graph类,以支持上述算法的实现。
import java.util.*;
class Graph {
final List<List<Edge>> adjList;
public Graph(int vertices) {
adjList = new ArrayList<>(vertices);
for (int i = 0; i < vertices; i++) {
adjList.add(new ArrayList<>());
}
}
public void addEdge(int from, int to, int weight) {
adjList.get(from).add(new Edge(from, to, weight));
adjList.get(to).add(new Edge(to, from, weight)); // For undirected graph
}
public List<Edge> getEdges(int vertex) {
return adjList.get(vertex);
}
public List<Edge> edges() {
List<Edge> edges = new ArrayList<>();
for (List<Edge> edgesList : adjList) {
edges.addAll(edgesList);
}
return edges;
}
public int size() {
return adjList.size();
}
static class Edge {
final int from;
final int to;
final int weight;
Edge(int from, int to, int weight) {
this.from = from;
this.to = to;
this.weight = weight;
}
@Override
public String toString() {
return String.format("%d - %d: %d", from, to, weight);
}
}
}
对比分析
解决的问题
- Dijkstra算法:解决单源最短路径问题。
- Prim算法:解决最小生成树问题,适用于稠密图。
- Kruskal算法:解决最小生成树问题,适用于稀疏图。
优劣性
- Dijkstra算法:
- 优点:适用于有权重且无负权边的图。
- 缺点:无法处理负权边。
- Prim算法:
- 优点:适用于稠密图。
- 缺点:在稀疏图中效率较低。
- Kruskal算法:
- 优点:适用于稀疏图,简单易实现。
- 缺点:在处理稠密图时效率较低。
异同点
- 相同点:
- Prim和Kruskal算法都用于解决最小生成树问题。
- 都使用贪心算法思想。
- Dijkstra和Prim算法都使用优先队列来获取下一个应该加入的节点
- 不同点:
- Dijkstra算法用于最短路径问题,Prim和Kruskal算法用于最小生成树问题。
- Prim算法从顶点开始构建生成树,Kruskal算法从边开始构建生成树。
- Dijkstra算法在Relax函数中是与源节点距离作比较,Prim算法在scan函数中是与当前在生成树中的节点距离做比较。
总结
通过对Dijkstra、Prim和Kruskal算法的介绍和代码实现,我们可以更好地理解这三种经典算法在图论中的应用。每种算法都有其适用场景和优劣性,选择合适的算法可以提高解决问题的效率。希望本文能为你在学习和应用图算法时提供帮助。