在Pandas库中,`loc`是基于标签的索引方法,它允许用户根据行标签和列标签来选择数据。这与`iloc`方法不同,后者是基于整数位置的索引。在处理数据时,尤其是当数据具有描述性标签时,`loc`方法非常有用。
目录
loc详解
`loc`方法通过行标签和列标签来定位数据。在二维数据结构(如DataFrame)中,`loc`的第一个参数通常用于指定行标签,第二个参数用于指定列标签。你可以传递单个标签、标签列表、标签切片或者布尔条件来选择数据。
- 单个标签:选择单个行或列;
- 标签列表:选择多个行或列;
- 标签切片:选择连续的行或列范围(但注意,标签切片在Pandas中不如在Python的列表切片中常见,因为标签可能不是连续的整数);
- 布尔条件:基于某个条件选择行。
代码示例
示例1:选择单个元素
import pandas as pd
# 创建一个简单的DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35], 'City': ['New York', 'London', 'Paris']}
df = pd.DataFrame(data)
# 使用loc选择第一行'Age'列的元素
element = df.loc[0, 'Age']
print(element) # 输出:25示例2:选择多行多列
# 选择标签为'Alice'和'Bob'的行
rows = df.loc[['Alice', 'Bob']]
print(rows)
# 选择'Name'和'Age'列
columns = df.loc[:, ['Name', 'Age']]
print(columns)
# 选择标签为'Alice'和'Bob'的行,以及'Name'和'Age'列
rows_columns = df.loc[['Alice', 'Bob'], ['Name', 'Age']]
print(rows_columns)示例3:使用布尔条件选择行
# 选择年龄大于30的行
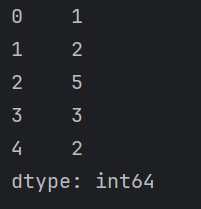
filtered_rows = df.loc[df['Age'] > 30]
print(filtered_rows)
# 使用query方法(基于字符串的查询)
filtered_rows_query = df.query('Age > 30')
print(filtered_rows_query)示例4:标签切片(注意:不常用)
虽然Pandas的`loc`不常用切片来选择基于标签的行(因为标签可能不是连续的),但你可以使用它来选择基于标签的列。然而,这通常不如直接指定列标签列表来得直观。
# 选择'Name'到'City'(包括)的列
slice_columns = df.loc[:, 'Name':'City']
print(slice_columns)注意事项
- `loc`是基于标签的索引,因此它依赖于行标签和列标签的存在;
- 当使用布尔条件选择行时,返回的DataFrame将包含满足条件的所有行,以及原始DataFrame中的所有列;
- 在选择列时,可以直接使用列标签列表,这比使用切片更为常见和直观;
- 如果你正在处理的是一个按时间索引的DataFrame(即时间序列数据),`loc`方法特别有用,因为它允许你基于日期时间标签来选择数据。




















![[大模型]Llama-3-8B-Instruct FastApi 部署调用](https://img-blog.csdnimg.cn/direct/3703f65aaf774a8a93e74155039644de.png#pic_center)