YOLOv8简介
YOLOv8是YOLO系列的最新版本,在继承YOLOv7的基础上进行了进一步改进。YOLOv8在网络结构、损失函数和训练策略上都有显著的提升,使其在目标检测任务中表现更加出色。各位只需要记住,做目标检测,无脑选V8就完了。YOLOv8模型的主要特点包括:
- 改进的网络结构:采用更深层次的卷积神经网络,增强了特征提取能力。
- 新的损失函数:引入了优化的损失函数,提高了检测的精度和稳定性。
- 多尺度检测:增强了对不同尺度物体的检测能力。
yoloV8 Github主页

安装环境
一行命令即可
pip install ultralytics
实现原理
预训练模型
YOLOv8在大规模数据集(如COCO数据集)上进行了预训练,模型学习到了丰富的特征表示,具备识别多种类别物体的能力。预训练模型能够加速特定任务(如行人检测)的训练过程,并提高模型的初始性能。转移学习
转移学习是将预训练模型应用到新的特定任务上的关键技术。通过在特定任务的数据集上进行微调,模型可以快速适应新任务的要求。转移学习的核心思想是利用预训练模型的已有知识,在新的数据上进行少量训练,以达到优化性能的目的。冻结层与微调
在转移学习过程中,我们可以冻结模型的部分层,仅训练最后几层。冻结层的目的是保留预训练模型的特征提取能力,避免在新任务的训练过程中丧失已有的知识。微调则是对模型的检测头或少数几层进行训练,使其适应新的任务要求。
冻结层与微调的步骤:
- 加载预训练模型:从预训练的YOLOv8模型开始。
- 冻结前几层:保留这些层的权重不变,确保模型保留原有的特征提取能力。
- 训练最后几层:对模型的检测头或少数几层进行训练,使其优化特定任务(如行人检测)的性能。
数据准备
网上有很多公开数据集。随便一搜,到处都是。这里提供一个整理好的yolo格式的行人数据集。
行人数据集网盘下载:
链接:https://pan.baidu.com/s/1zE8jXUKS9zHwW_Xtcaw2kw?pwd=wkai
提取码:wkai
yolo格式的数据集目录结构:

配置YOLOv8模型
创建一个YAML文件来配置你的数据集,例如data.yaml:
path: E:/yolov8行人检测/ziliao/source # 数据集的根路径
train: images/train # 训练集图像路径
val: images/val # 验证集图像路径
test: images/test # 测试集图像路径
# Number of classes
nc: 1 # 类别数量 (行人检测,所以只有1类)
# Class names
names: ['person'] # 类别名称
训练脚本
from ultralytics import YOLO
def train_yolo():
# 定义模型
model = YOLO('yolov8n.pt') # 使用预训练的 YOLOv8 模型
# 训练模型
model.train(
data='./data.yaml', # 数据集配置文件路径
epochs=10, # 训练轮数
imgsz=640, # 输入图像大小
batch=16, # 批次大小
name='yolov8_person_detection', # 训练运行名称
cache=True # 是否缓存数据集
)
if __name__ == '__main__':
train_yolo()
推理脚本
from ultralytics import YOLO
import cv2
import matplotlib.pyplot as plt
def run_inference(image_path, model_path='runs/best.pt'):
# 加载训练好的模型
model = YOLO(model_path)
# 进行推理
results = model(image_path)
# 显示结果
if isinstance(results, list):
for result in results:
result.show()
else:
results.show()
# 选择第一张图像的结果
result_img = results[0].plot()
# 使用 OpenCV 显示结果图像
cv2.imshow('Inference Result', result_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 保存结果图像
save_path = 'inference_result.jpg'
cv2.imwrite(save_path, result_img)
print(f"Result saved to {save_path}")
if __name__ == '__main__':
# 替换为你想要检测的图像路径
image_path = './test-img/js.jpg'
run_inference(image_path)
模型评估
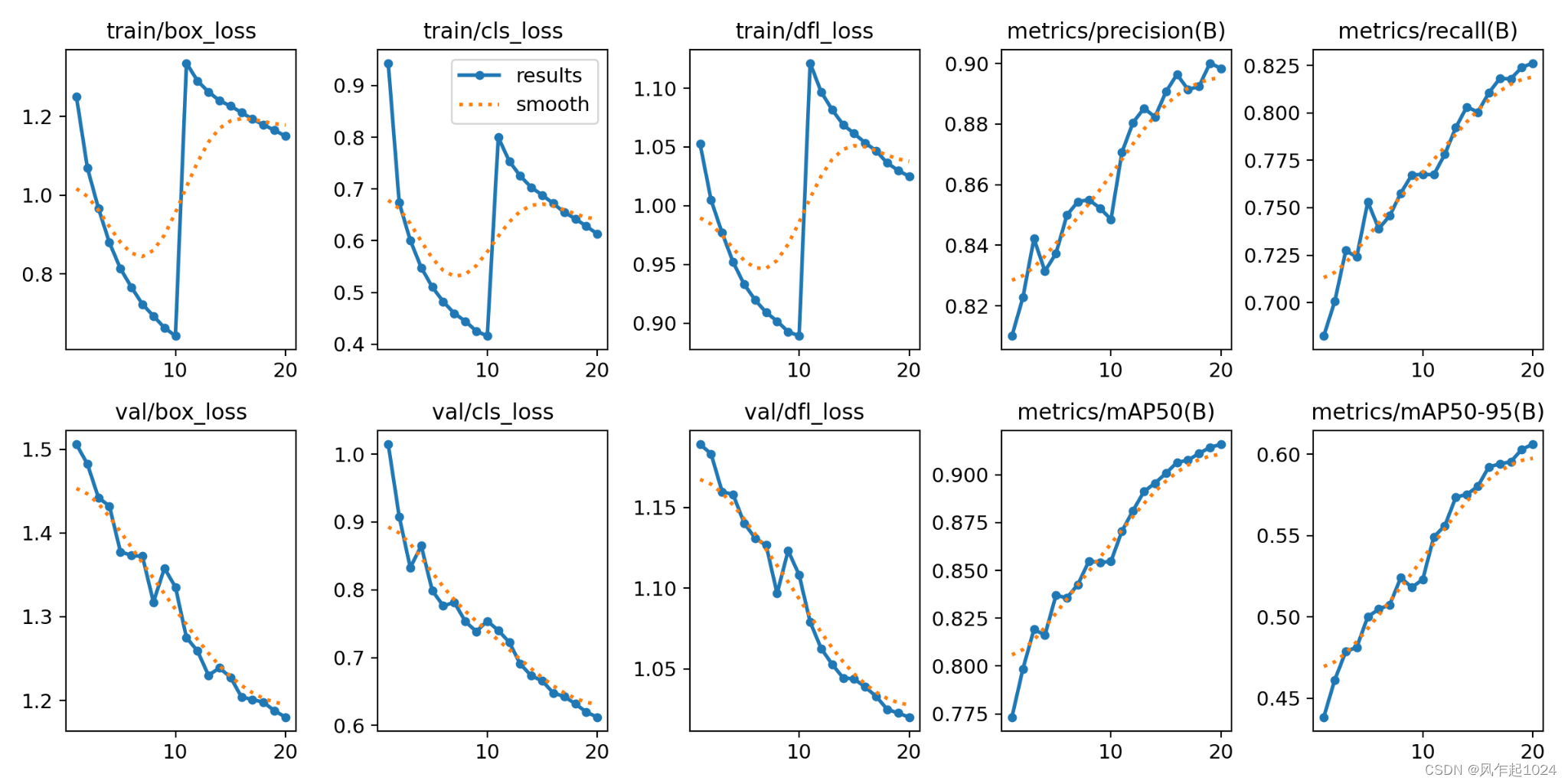
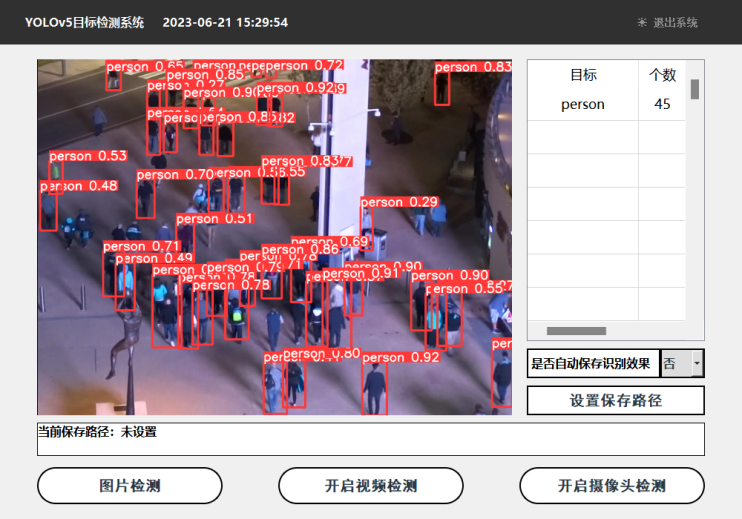
推理结果

结论
要实现对其他目标的检测,方法也类似。如果在推理阶段效果不佳,可能是由于训练数据集不够多样化或样本量不足、模型训练参数设置不当、预训练模型选择不合适或冻结层策略不合理、损失函数和评价指标设置不当等原因。解决方案包括:增加数据量,收集更多包含行人的图像,使用数据增强技术(如旋转、缩放、裁剪、颜色变换等);调整学习率,找到最佳学习率设置,适当增加训练轮次,选择合适的批次大小;尝试不同的预训练模型,调整冻结层策略;检查损失函数,确保适合当前检测任务,使用适当的评价指标(如mAP、F1-score等)监控模型性能。
优化策略可以包括数据增强(随机裁剪、颜色变换、几何变换、添加噪声等)、超参数调整(学习率调度、提前停止、批次大小)、模型架构调整(调整网络层数、多尺度检测、优化检测头)和混合训练数据(多任务学习、使用预训练数据)。通过不断实验和调整,找到适合项目的最佳参数和策略,可以显著提升YOLOv8检测任务上的性能。