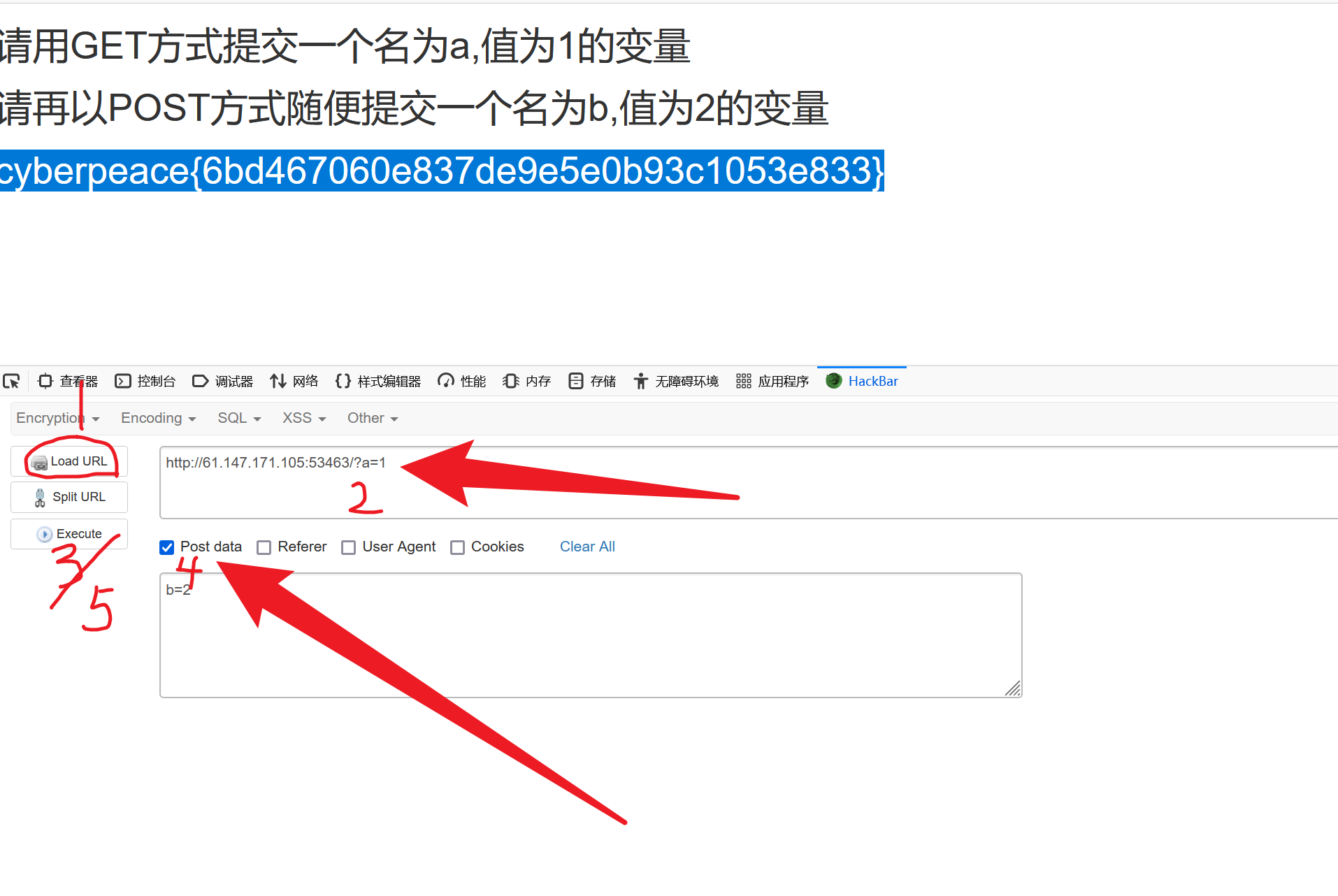
经典神经网络(11)VQ-VAE模型及其在MNIST数据集上的应用
我们之前已经了解了PixelCNN模型。
今天,我们了解下DeepMind在2017年提出的一种基于离散隐变量(Discrete Latent variables)的生成模型:VQ-VAE。
VQ-VAE采用离散隐变量,而不是像VAE那样采用连续的隐变量。其实VQ-VAE本质上是一种AE,只能很好地完成图像压缩,把图像变成一个短得多的向量,而不支持随机图像生成。
那么,VQ-VAE会被归类到图像生成模型中呢?这是因为VQ-VAE单独训练了一个基于自回归的模型如PixelCNN来学习先验(prior),对VQ-VAE的离散编码空间采样。而不是像VAE那样采用一个固定的先验(标准正态分布)。此外,VQ-VAE还是一个强大的无监督表征学习模型,它学习的离散编码具有很强的表征能力:
- OpenAI在2021年发布的文本转图像模型DALL-E就是基于VQ-VAE。
- 另外,在BEiT中也用VQ-VAE得到的离散编码作为训练目标。
1 VQ-VAE
1.1 从AE到VQ-VAE
AE是一类能够把图片压缩成较短的向量的神经网络模型。
- AE的编码器编码出来的向量空间是不规整的。也就是说,解码器只认识经编码器编出来的向量,而不认识其他的向量。
- 如下图,我们在code空间上,两张图片的编码点中间处取一点,然后将这一点交给解码器,我们希望新的生成图片是一张清晰的图片(类似3/4全月的样子)。但是,实际的结果是,生成图片是模糊且无法辨认的乱码图。

只要AE的编码空间比较规整,符合某个简单的数学分布(比如最常见的标准正态分布,如下图所示),那我们就可以从这个分布里随机采样向量,再让解码器根据这个向量来完成随机图片生成了。
- VAE就是这样一种改进版的AE,它用一些巧妙的方法约束了编码向量z,使得z满足标准正态分布。
- 训练完成后,我们就可以扔掉编码器,用来自标准正态分布的随机向量和解码器来实现随机图像生成了。

VQ-VAE的作者认为,VAE的生成图片之所以质量不高,是因为图片被编码成了连续向量。而实际上,把图片编码成离散向量会更加自然。
至于离散编码的原因,作者解释如下:https://avdnoord.github.io/homepage/slides/SANE2017.pdf

1.2 VQVAE概述
把图像编码成离散向量后,会带来两个问题:
第一个问题是,神经网络会默认输入满足一个连续的分布,而不善于处理离散的输入。
- 如果你直接输入0, 1, 2这些数字,神经网络会默认1是一个处于0, 2中间的一种状态。为了解决这一问题,我们可以借鉴NLP中对于离散单词的处理方法。
- 我们可以把嵌入层加到VQ-VAE的解码器前,这个嵌入层就是
embedding space(嵌入空间),也称codebook。 注意:其实Encoder编码出来的是二维离散编码,下图画的是一维。

另一个问题是离散向量不好采样。
- VAE之所以把图片编码成符合正态分布的连续向量,就是为了能在图像生成时把编码器扔掉,让随机采样出的向量也能通过解码器变成图片。现在,VQ-VAE把图片编码了一个离散向量,这个离散向量构成的空间是不好采样的。
- VQ-VAE的作者之前设计了一种图像生成网络,叫做PixelCNN。可以用PixelCNN生成离散编码,再利用VQ-VAE的解码器把离散编码变成图像。
VQ-VAE的架构图,如下图所示:
- 训练VQ-VAE的编码器和解码器,使得VQ-VAE能把图像变成
latent image(下图zq),也能把latent image(下图zq)变回图像。 - 训练PixelCNN,让它学习怎么生成
latent image(下图zq)。 - 生成(采样)时,先用PixelCNN采样出
latent image(下图zq),再用VQ-VAE把latent image(下图zq)翻译成最终的生成图像。
- 训练VQ-VAE的编码器和解码器,使得VQ-VAE能把图像变成

1.3 VQ-VAE设计细节
1.3.1 关联编码器的输出与解码器的输入
如何关联编码器的输出与解码器的输入呢?
假设嵌入空间codebook已经训练完毕,那么对于编码器的每个输出向量 z e ( x ) ze(x) ze(x),我们需要找出它在嵌入空间里的最近邻 z q ( x ) zq(x) zq(x),把 z e ( x ) ze(x) ze(x)替换成 z q ( x ) zq(x) zq(x)作为解码器的输入。- 方式是:求最近邻,即先计算向量与嵌入空间K个向量每个向量的距离,再对距离数组取一个
argmin,求出最近的下标(如上图中的shape为[1,7,7]),最后用下标去嵌入空间里取向量,就得到了 z q zq zq(如上图中的shape为[1,32,7,7])。下标构成的多维数组,也正是VQ-VAE的离散编码。
1.3.2 梯度复制
- 我们现在能把编码器和解码器拼接到一起,但怎么让梯度从解码器的输入 z q ( x ) zq(x) zq(x)传到 z e ( x ) ze(x) ze(x)?从 z e ( x ) ze(x) ze(x)到 z q ( x ) zq(x) zq(x)的变换是一个从数组里取值,这个操作无法求导。
- VQ-VAE使用了一种叫做"straight-through estimator"的技术【即前向传播和反向传播的计算可以不对应】来完成梯度复制。VQ-VAE使用了一种叫做sg(stop gradient,停止梯度)的运算:
s g ( x ) = { x , 前向传播 0 , 反向传播 前向传播时, s g 里的值不变;反向传播时, s g 按值为 0 求导,即此次计算无梯度。 sg(x)=\begin{cases} x, & 前向传播\\ 0,& 反向传播 \end{cases}\\ 前向传播时,sg里的值不变;反向传播时,sg按值为0求导,即此次计算无梯度。 sg(x)={x,0,前向传播反向传播前向传播时,sg里的值不变;反向传播时,sg按值为0求导,即此次计算无梯度。
由于VQ-VAE其实是一个AE,误差函数里应该只有原图像和目标图像的重建误差:
L r e c o n s t r u c t = ∣ ∣ x − d e c o d e r ( z q ( x ) ) ∣ ∣ 2 2 L_{reconstruct}=||x-decoder(z_q(x))||_2^2 Lreconstruct=∣∣x−decoder(zq(x))∣∣22
我们现在利用sg运算,设计新的重建误差:
L r e c o n s t r u c t = ∣ ∣ x − d e c o d e r ( z e ( x ) + s g [ z q ( x ) − z e ( x ) ] ) ∣ ∣ 2 2 前向传播时,就是拿解码器的输入 z q ( x ) 来算误差: L r e c o n s t r u c t = ∣ ∣ x − d e c o d e r ( z e ( x ) + z q ( x ) − z e ( x ) ) ∣ ∣ 2 2 = ∣ ∣ x − d e c o d e r ( z q ( x ) ) ∣ ∣ 2 2 反向传播时,等价于把解码器的梯度全部传给 z e ( x ) : L r e c o n s t r u c t = ∣ ∣ x − d e c o d e r ( z e ( x ) + s g [ z q ( x ) − z e ( x ) ] ) ∣ ∣ 2 2 = ∣ ∣ x − d e c o d e r ( z e ( x ) ) ∣ ∣ 2 2 L_{reconstruct}=||x-decoder(z_e(x)+sg[z_q(x)-z_e(x)])||_2^2\\ 前向传播时,就是拿解码器的输入z_q(x)来算误差:\\ L_{reconstruct}=||x-decoder(z_e(x)+z_q(x)-z_e(x))||_2^2\\ =||x-decoder(z_q(x))||_2^2\\ 反向传播时,等价于把解码器的梯度全部传给z_e(x):\\ L_{reconstruct}=||x-decoder(z_e(x)+sg[z_q(x)-z_e(x)])||_2^2\\ =||x-decoder(z_e(x))||_2^2 Lreconstruct=∣∣x−decoder(ze(x)+sg[zq(x)−ze(x)])∣∣22前向传播时,就是拿解码器的输入zq(x)来算误差:Lreconstruct=∣∣x−decoder(ze(x)+zq(x)−ze(x))∣∣22=∣∣x−decoder(zq(x))∣∣22反向传播时,等价于把解码器的梯度全部传给ze(x):Lreconstruct=∣∣x−decoder(ze(x)+sg[zq(x)−ze(x)])∣∣22=∣∣x−decoder(ze(x))∣∣22
在PyTorch里,(x).detach()就是sg(x),它的值在前向传播时取x,反向传播时取0。
# stop gradient
decoder_input = ze + (zq - ze).detach()
# decode
x_hat = decoder(decoder_input)
# l_reconstruct
l_reconstruct = mse_loss(x, x_hat)
1.3.3 优化嵌入空间codebook
嵌入空间的优化目标是什么呢?嵌入空间的每一个向量应该能概括一类编码器输出的向量。因此,嵌入空间的向量应该和其对应编码器输出尽可能接近。
L e = ∣ ∣ z e ( x ) − z q ( x ) ∣ ∣ 2 2 z e ( x ) 是编码器的输出向量, z q ( x ) 是其在嵌入空间的最近邻向量 L_e=||z_e(x)-z_q(x)||_2^2\\ z_e(x)是编码器的输出向量,z_q(x)是其在嵌入空间的最近邻向量 Le=∣∣ze(x)−zq(x)∣∣22ze(x)是编码器的输出向量,zq(x)是其在嵌入空间的最近邻向量
作者认为,编码器和嵌入向量的学习速度应该不一样快。
于是,他们再次使用了停止梯度的技巧,把上面那个误差函数拆成了两部分。其中,β控制了编码器的相对学习速度。作者发现,算法对β的变化不敏感,β取0.1~2.0都差不多。
L e = ∣ ∣ s g [ z e ( x ) ] − z q ( x ) ∣ ∣ 2 2 + β ∣ ∣ z e ( x ) − s g [ z q ( x ) ] ∣ ∣ 2 2 L_e=||sg[z_e(x)]-z_q(x)||_2^2+\beta||z_e(x)-sg[z_q(x)]||_2^2\\ Le=∣∣sg[ze(x)]−zq(x)∣∣22+β∣∣ze(x)−sg[zq(x)]∣∣22
# vq loss
l_embedding = mse_loss(ze.detach(), zq)
# commitment loss
l_commitment = mse_loss(ze, zq.detach())
VQ-VAE总体的损失函数可以写成:
L t o t a l = L r e c o n s t r u c t + L e = ∣ ∣ x − d e c o d e r ( z e ( x ) + s g [ z q ( x ) − z e ( x ) ] ) ∣ ∣ 2 2 + α ∣ ∣ s g [ z e ( x ) ] − z q ( x ) ∣ ∣ 2 2 + β ∣ ∣ z e ( x ) − s g [ z q ( x ) ] ∣ ∣ 2 2 L_{total}=L_{reconstruct} + L_e \\ =||x-decoder(z_e(x)+sg[z_q(x)-z_e(x)])||_2^2 +\alpha||sg[z_e(x)]-z_q(x)||_2^2\\+\beta||z_e(x)-sg[z_q(x)]||_2^2 Ltotal=Lreconstruct+Le=∣∣x−decoder(ze(x)+sg[zq(x)−ze(x)])∣∣22+α∣∣sg[ze(x)]−zq(x)∣∣22+β∣∣ze(x)−sg[zq(x)]∣∣22
# reconstruct loss
l_reconstruct = mse_loss(x, x_hat)
# vq loss
l_embedding = mse_loss(ze.detach(), zq)
# commitment loss
l_commitment = mse_loss(ze, zq.detach())
# total loss
loss = l_reconstruct + \
l_w_embedding * l_embedding + l_w_commitment * l_commitment
1.3.4 先验模型PixelCNN
- 训练好VQ-VAE后,还需要训练一个先验模型来完成数据生成,论文中采用PixelCNN模型。
- 这里我们不再是学习生成原始的pixels,而是学习生成离散编码:
- 首先,我们需要用已经训练好的VQ-VAE模型对训练图像推理,得到每张图像对应的离散编码;
- 然后用一个PixelCNN来对离散编码进行建模
- 最后的预测层采用基于softmax的多分类,类别数为embedding空间的大小K。
- 那么,生成图像的过程就比较简单了,首先用训练好的PixelCNN模型来采样一个离散编码样本(上图中shape为[1, 32, 7, 7]),然后送入VQ-VAE的decoder中,得到生成的图像。
- 实际上,PixelCNN不是唯一可用的拟合离散分布的模型。
我们可以把它换成Transformer,甚至是diffusion模型。
2 VQ-VAE模型在MNIST数据集上的应用
这里使用的模型为Gated PixelCNN模型,具体可参考:
经典神经网络(10)PixelCNN模型、Gated PixelCNN模型及其在MNIST数据集上的应用
网络结构图如下所示:

2.1 VQ-VAE模型
VQVAE的编码器和解码器的结构很简单,仅由普通的上/下采样层和残差块组成。
- 编码器先是有两个3x3卷积+2倍下采样卷积的模块,再有两个残差块(ReLU, 3x3卷积, ReLU, 1x1卷积);
- 解码器则反过来,先有两个残差块,再有两个3x3卷积+2倍上采样反卷积的模块。
# Reference: https://github.com/SingleZombie/DL-Demos/tree/master/dldemos/VQVAE
import os
import time
import cv2
import einops
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torch.utils.data import DataLoader, Dataset
from torch.utils.data.distributed import DistributedSampler
from torchvision import transforms
from GatedPixelCNNDemo import GatedPixelCNN, GatedBlock
class ResidualBlock(nn.Module):
def __init__(self, dim):
super().__init__()
self.relu = nn.ReLU()
self.conv1 = nn.Conv2d(dim, dim, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(dim, dim, kernel_size=1)
def forward(self, x):
tmp = self.relu(x)
tmp = self.conv1(tmp)
tmp = self.relu(tmp)
tmp = self.conv2(tmp)
return x + tmp
class VQVAE(nn.Module):
def __init__(self, input_dim, dim, n_embedding):
super().__init__()
# 1、编码器
self.encoder = nn.Sequential(nn.Conv2d(input_dim, dim, kernel_size=4, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(dim, dim, kernel_size=4, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(dim, dim, kernel_size=3, stride=1, padding=1),
ResidualBlock(dim),
ResidualBlock(dim)
)
self.vq_embedding = nn.Embedding(n_embedding, dim)
# 初始化为均匀分布
self.vq_embedding.weight.data.uniform_(-1.0 / n_embedding, 1.0 / n_embedding)
# 2、解码器
self.decoder = nn.Sequential(
nn.Conv2d(dim, dim, 3, 1, 1),
ResidualBlock(dim),
ResidualBlock(dim),
nn.ConvTranspose2d(dim, dim, 4, 2, 1),
nn.ReLU(),
nn.ConvTranspose2d(dim, input_dim, 4, 2, 1)
)
self.n_downsample = 2
def forward(self, x):
# encode [N, 1, 28, 28] -> [N, 32, 7, 7]
ze = self.encoder(x)
# ze: [N, C, H, W]
# embedding [K, C] [32, 32]
embedding = self.vq_embedding.weight.data
N, C, H, W = ze.shape
K, _ = embedding.shape
# 求解最近邻
embedding_broadcast = embedding.reshape(1, K, C, 1, 1)
ze_broadcast = ze.reshape(N, 1, C, H, W)
distance = torch.sum((embedding_broadcast - ze_broadcast)**2, 2)
nearest_neighbor = torch.argmin(distance, 1)
# make C to the second dim
zq = self.vq_embedding(nearest_neighbor).permute(0, 3, 1, 2)
# stop gradient
decoder_input = ze + (zq - ze).detach()
# decode
x_hat = self.decoder(decoder_input)
return x_hat, ze, zq
@torch.no_grad()
def encode(self, x):
ze = self.encoder(x)
embedding = self.vq_embedding.weight.data
# ze: [N, C, H, W]
# embedding [K, C]
N, C, H, W = ze.shape
K, _ = embedding.shape
embedding_broadcast = embedding.reshape(1, K, C, 1, 1)
ze_broadcast = ze.reshape(N, 1, C, H, W)
distance = torch.sum((embedding_broadcast - ze_broadcast)**2, 2)
nearest_neighbor = torch.argmin(distance, 1)
return nearest_neighbor
@torch.no_grad()
def decode(self, discrete_latent):
zq = self.vq_embedding(discrete_latent).permute(0, 3, 1, 2)
x_hat = self.decoder(zq)
return x_hat
# Shape: [C, H, W]
def get_latent_HW(self, input_shape):
C, H, W = input_shape
return (H // 2**self.n_downsample, W // 2**self.n_downsample)
2.2 先验模型
我们已经有了一个普通的PixelCNN模型GatedPixelCNN
- 需要在整个模型的最前面套一个嵌入层,嵌入层的嵌入个数等于离散编码的个数(
color_level),嵌入长度等于模型的特征长度(p)。 - 由于嵌入层会直接输出一个长度为
p的向量,我们还需要把第一个模块的输入通道数改成p。
# 继承自我们之前实现的模型GatedPixelCNN
class PixelCNNWithEmbedding(GatedPixelCNN):
def __init__(self, n_blocks, p, linear_dim, bn=True, color_level=256):
super().__init__(n_blocks, p, linear_dim, bn, color_level)
self.embedding = nn.Embedding(color_level, p)
self.block1 = GatedBlock('A', p, p, bn)
def forward(self, x):
x = self.embedding(x)
x = x.permute(0, 3, 1, 2).contiguous()
return super().forward(x)
2.3 两种模型的训练
- 下面就是常规的训练代码
- 先训练VQVAE、再训练PixelCNN
def train_vqvae(model: VQVAE,
img_shape=None,
device='cuda',
ckpt_path='./model.pth',
batch_size=64,
dataset_type='MNIST',
lr=1e-3,
n_epochs=100,
l_w_embedding=1,
l_w_commitment=0.25):
print('batch size:', batch_size)
dataloader = get_dataloader(dataset_type,
batch_size,
img_shape=img_shape)
model.to(device)
model.train()
optimizer = torch.optim.Adam(model.parameters(), lr)
mse_loss = nn.MSELoss()
tic = time.time()
for e in range(n_epochs):
total_loss = 0
for x in dataloader:
current_batch_size = x.shape[0]
x = x.to(device)
x_hat, ze, zq = model(x)
# 1、reconstruct loss
l_reconstruct = mse_loss(x, x_hat)
# 2、vq loss + commitment loss
l_embedding = mse_loss(ze.detach(), zq)
l_commitment = mse_loss(ze, zq.detach())
# total loss
loss = l_reconstruct + \
l_w_embedding * l_embedding + l_w_commitment * l_commitment
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item() * current_batch_size
total_loss /= len(dataloader.dataset)
toc = time.time()
torch.save(model.state_dict(), ckpt_path)
print(f'epoch {e} loss: {total_loss} elapsed {(toc - tic):.2f}s')
print('Done')
def train_generative_model(vqvae: VQVAE,
model,
img_shape=None,
device='cuda',
ckpt_path='./gen_model.pth',
dataset_type='MNIST',
batch_size=64,
n_epochs=50):
print('batch size:', batch_size)
dataloader = get_dataloader(dataset_type,
batch_size,
img_shape=img_shape)
vqvae.to(device)
vqvae.eval()
model.to(device)
model.train()
optimizer = torch.optim.Adam(model.parameters(), 1e-3)
# 交叉熵损失
loss_fn = nn.CrossEntropyLoss()
tic = time.time()
for e in range(n_epochs):
total_loss = 0
for x in dataloader:
current_batch_size = x.shape[0]
with torch.no_grad():
x = x.to(device)
# 1、训练好的VQ-VAE模型对训练图像推理,得到每张图像对应的离散编码
x = vqvae.encode(x)
# 2、用一个PixelCNN来对离散编码进行建模
predict_x = model(x)
# 3、预测层采用基于softmax的多分类
loss = loss_fn(predict_x, x)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item() * current_batch_size
total_loss /= len(dataloader.dataset)
toc = time.time()
torch.save(model.state_dict(), ckpt_path)
print(f'epoch {e} loss: {total_loss} elapsed {(toc - tic):.2f}s')
print('Done')
def reconstruct(model, x, device, dataset_type='MNIST'):
model.to(device)
model.eval()
with torch.no_grad():
x_hat, _, _ = model(x)
n = x.shape[0]
n1 = int(n**0.5)
x_cat = torch.concat((x, x_hat), 3)
x_cat = einops.rearrange(x_cat, '(n1 n2) c h w -> (n1 h) (n2 w) c', n1=n1)
x_cat = (x_cat.clip(0, 1) * 255).cpu().numpy().astype(np.uint8)
cv2.imwrite(f'work_dirs/vqvae_reconstruct_{dataset_type}.jpg', x_cat)
class MNISTImageDataset(Dataset):
def __init__(self, img_shape=(28, 28)):
super().__init__()
self.img_shape = img_shape
self.mnist = torchvision.datasets.MNIST(root='/root/autodl-fs/data/minist')
def __len__(self):
return len(self.mnist)
def __getitem__(self, index: int):
img = self.mnist[index][0]
pipeline = transforms.Compose(
[transforms.Resize(self.img_shape),
transforms.ToTensor()])
return pipeline(img)
def get_dataloader(type,
batch_size,
img_shape=None,
dist_train=False,
num_workers=0,
**kwargs):
if type == 'MNIST':
if img_shape is not None:
dataset = MNISTImageDataset(img_shape)
else:
dataset = MNISTImageDataset()
if dist_train:
sampler = DistributedSampler(dataset)
dataloader = DataLoader(dataset,
batch_size=batch_size,
sampler=sampler,
num_workers=num_workers)
return dataloader, sampler
else:
dataloader = DataLoader(dataset,
batch_size=batch_size,
shuffle=True,
num_workers=num_workers)
return dataloader
cfg = dict(dataset_type='MNIST',
img_shape=(1, 28, 28),
dim=32,
n_embedding=32,
batch_size=32,
n_epochs=20,
l_w_embedding=1,
l_w_commitment=0.25,
lr=2e-4,
n_epochs_2=50,
batch_size_2=32,
pixelcnn_n_blocks=15,
pixelcnn_dim=128,
pixelcnn_linear_dim=32,
vqvae_path='./model_mnist.pth',
gen_model_path='./gen_model_mnist.pth')
if __name__ == '__main__':
os.makedirs('work_dirs', exist_ok=True)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
img_shape = cfg['img_shape']
# 初始化模型
vqvae = VQVAE(img_shape[0], cfg['dim'], cfg['n_embedding'])
gen_model = PixelCNNWithEmbedding(cfg['pixelcnn_n_blocks'],
cfg['pixelcnn_dim'],
cfg['pixelcnn_linear_dim'], True,
cfg['n_embedding'])
# 1. Train VQVAE
train_vqvae(vqvae,
img_shape=(img_shape[1], img_shape[2]),
device=device,
ckpt_path=cfg['vqvae_path'],
batch_size=cfg['batch_size'],
dataset_type=cfg['dataset_type'],
lr=cfg['lr'],
n_epochs=cfg['n_epochs'],
l_w_embedding=cfg['l_w_embedding'],
l_w_commitment=cfg['l_w_commitment'])
# 2. Test VQVAE by visualizaing reconstruction result
vqvae.load_state_dict(torch.load(cfg['vqvae_path']))
dataloader = get_dataloader(cfg['dataset_type'],
16,
img_shape=(img_shape[1], img_shape[2]))
img = next(iter(dataloader)).to(device)
reconstruct(vqvae, img, device, cfg['dataset_type'])
# 3. Train Generative model (Gated PixelCNN)
vqvae.load_state_dict(torch.load(cfg['vqvae_path']))
train_generative_model(vqvae,
gen_model,
img_shape=(img_shape[1], img_shape[2]),
device=device,
ckpt_path=cfg['gen_model_path'],
dataset_type=cfg['dataset_type'],
batch_size=cfg['batch_size_2'],
n_epochs=cfg['n_epochs_2'])
# 4. Sample VQVAE
vqvae.load_state_dict(torch.load(cfg['vqvae_path']))
gen_model.load_state_dict(torch.load(cfg['gen_model_path']))
sample_imgs(vqvae,
gen_model,
cfg['img_shape'],
device=device,
n_sample=1,
dataset_type=cfg['dataset_type'])
2.4 图像生成(采样)
def sample_imgs(vqvae: VQVAE,
gen_model,
img_shape,
n_sample=81,
device='cuda',
dataset_type='MNIST'):
vqvae = vqvae.to(device)
vqvae.eval()
gen_model = gen_model.to(device)
gen_model.eval()
C, H, W = img_shape
H, W = vqvae.get_latent_HW((C, H, W))
input_shape = (n_sample, H, W)
# 初始化为0
x = torch.zeros(input_shape).to(device).to(torch.long)
with torch.no_grad():
# 逐像素预测
for i in range(H):
for j in range(W):
output = gen_model(x)
prob_dist = F.softmax(output[:, :, i, j], -1)
# 从概率分布中采样
pixel = torch.multinomial(prob_dist, 1)
x[:, i, j] = pixel[:, 0]
# 解码
imgs = vqvae.decode(x)
imgs = imgs * 255
imgs = imgs.clip(0, 255)
imgs = einops.rearrange(imgs,
'(n1 n2) c h w -> (n1 h) (n2 w) c',
n1=int(n_sample**0.5))
imgs = imgs.detach().cpu().numpy().astype(np.uint8)
cv2.imwrite(f'work_dirs/vqvae_sample_{dataset_type}.jpg', imgs)