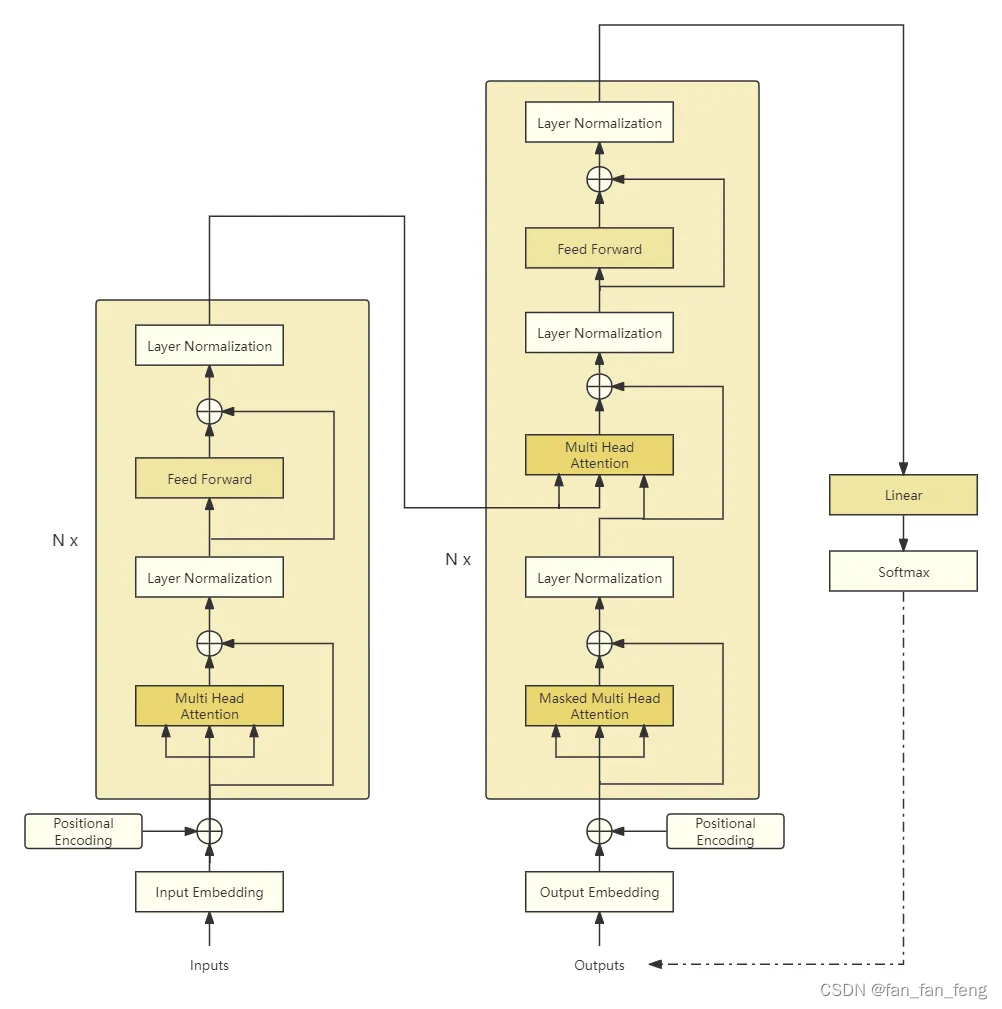
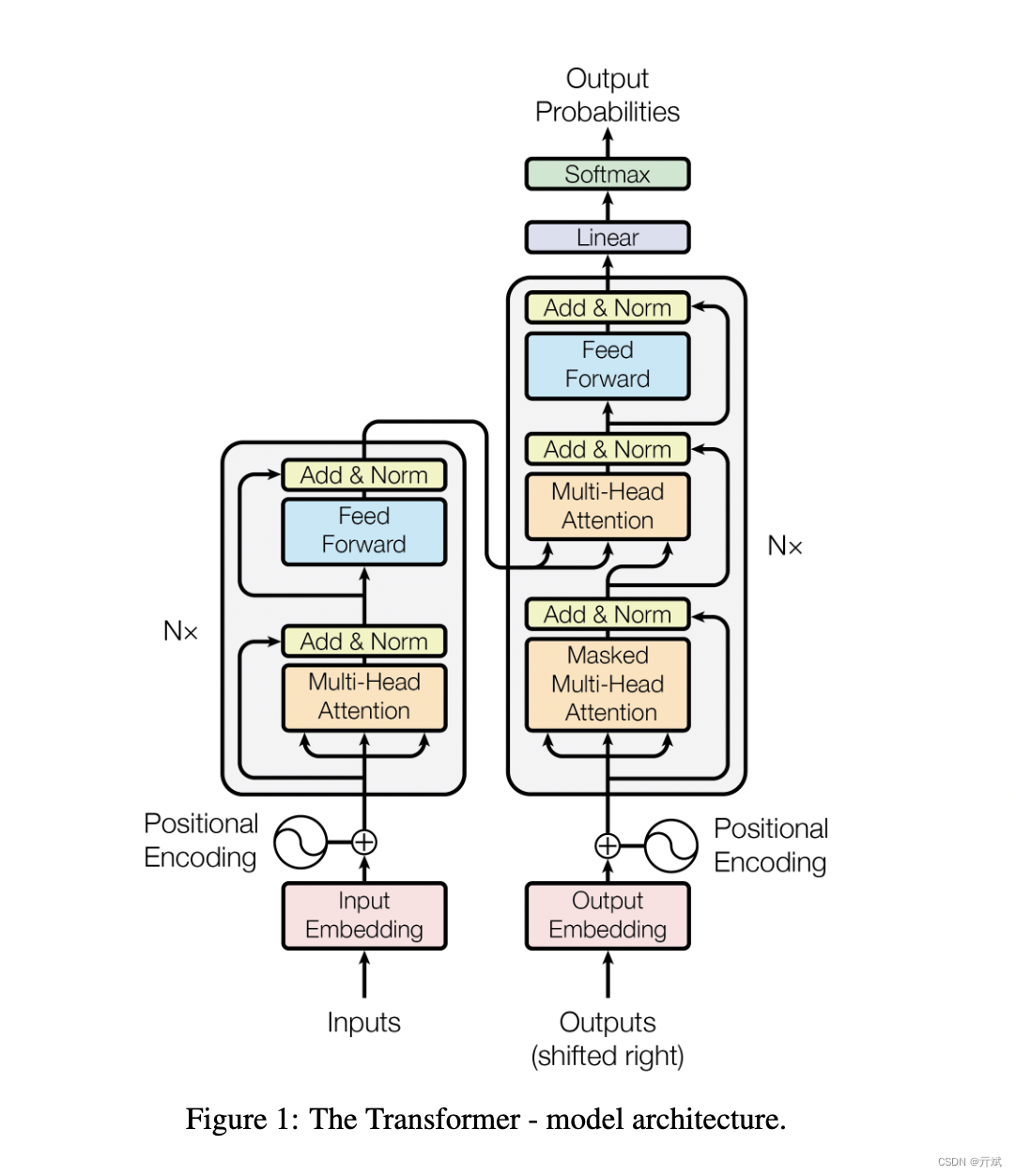
大模型基础——从零实现一个Transformer(1)
一、引言
上一章主要实现了一下Transformer里面的BPE算法和 Embedding模块定义
本章主要讲一下 Transformer里面的位置编码以及多头注意力
二、位置编码
2.1正弦位置编码(Sinusoidal Position Encoding)

其中:
pos:表示token在文本中的位置
i : i代表词向量具体的某一维度,即位置编码的每个维度对应一个波长不同的正弦或余弦波
d : d表示位置编码的最大维度,和词嵌入的维度相同,假设是512
对于位置0的编码为:

对于位置1的编码为:

2.2 正弦位置编码特性
- 相对位置关系:pos + k的位置编码可以被位置pos的位置编码线性表示
三角函数公式如下:


对于pos + k的位置编码:

根据式( 3 )和( 4 )整理上式有:


- 位置之间的相对距离
𝑃𝐸𝑝𝑜𝑠+𝑘∙𝑃𝐸𝑝𝑜𝑠 的内积:

位置之间内积的关系大小如下:

可以看到内积会随着相对位置的递增而减少,从而可以表示位置的相对距离。内积的结果是对称的,所以没有方向信息。
2.3 代码实现
import torch
from torch import nn,Tensor
import math
class PositionalEmbedding(nn.Module):
def __init__(self,d_model:int=512,dropout:float=0.1,max_positions:int=1024) -> None:
'''
:param d_model: embedding向量的维度
:param dropout:
:param max_positions: 最大长度
'''
super().__init__()
self.dropout = nn.Dropout(p=dropout)
# Position Embedding (max_positions,d_model)
pe = torch.zeros(max_positions,d_model)
# 创建position index列表 ,形状为:(max_positions, 1)
position = torch.arange(0,max_positions).unsqueeze(1)
# d_model 维度 偶数位是sin ,奇数位是cos
# 计算除数,这里的除数将用于计算正弦和余弦的频率
div_term = torch.exp(
torch.arange(0,d_model,2) * -(math.log(10000.0) /d_model)
)
# 对矩阵的偶数列(0,2,4...)进行正弦函数编码
pe[:, 0::2] = torch.sin(position * div_term)
# 对矩阵的奇数列(1,3,5...)进行余弦函数编码
pe[:, 1::2] = torch.cos(position * div_term)
# 扩展维度,增加batch_size: pe (1, max_positions, d_model)
pe = pe.unsqueeze(0)
# buffers will not be trained
self.register_buffer("pe", pe)
def forward(self,x:Tensor) ->Tensor:
"""
Args:
x (Tensor): (batch_size, seq_len, d_model) embeddings
Returns:
Tensor: (batch_size, seq_len, d_model)
"""
# x.size(1)是指当前x的最大长度
x = x + self.pe[:,:x.size(1)]
return self.dropout(x)
if __name__ == '__main__':
seq_len = 128
d_model = 512
pe = PositionalEmbedding(d_model)
x = torch.rand((1,100,d_model))
print(pe(x).shape)
三、多头注意力
3.1 自注意力
公式如下:

- 假设一个矩阵X,分别乘上权重矩阵,,就得到了Q , K , V向量矩阵

- 然后除以 𝑑𝑘 进行缩放,再经过Softmax,得到注意力权重矩阵,接着乘以value向量矩阵V,就一次得到了所有单词的输出矩阵Z

3.2 多头注意力
将原来n_head分割乘Nx n_sub_head.对于每个头i,都有它自己不同的key,query和value矩阵: 𝑊𝑖𝐾,𝑊𝑖𝑄,𝑊𝑖𝑉 。在多头注意力中,key和query的维度是 𝑑𝑘 ,value嵌入的维度是 𝑑𝑣 (其中key,query和value的维度可以不同,Transformer里面一般设置的是相同的),这样每个头i,权重 𝑊𝑖𝑄∈𝑅𝑑×𝑑𝑘,𝑊𝑖𝐾∈𝑅𝑑×𝑑𝑘,𝑊𝑖𝑉∈𝑅𝑑×𝑑𝑣 ,然后与压缩到X中的输入相乘,得到 𝑄∈𝑅𝑁×𝑑𝑘,𝐾∈𝑅𝑁×𝑑𝑘,𝑉∈𝑅𝑁×𝑑𝑣 .


3.3 代码实现
import math
import torch
from torch import nn,Tensor
from typing import *
class MultiHeadAttention(nn.Module):
def __init__(self,d_model: int = 512,n_heads: int=8,dropout: float = 0.1):
'''
:param d_model: embedding大小
:param n_heads: 多头个数
:param dropout:
'''
super().__init__()
assert d_model % n_heads == 0
self.d_model = d_model
self.n_heads = n_heads
self.d_key = d_model // n_heads
self.q = nn.Linear(d_model,d_model)
self.k = nn.Linear(d_model,d_model)
self.k = nn.Linear(d_model,d_model)
self.concat = nn.Linear(d_model,d_model)
self.dropout = nn.Dropout(dropout)
def split_heads(self,x:Tensor,is_key : bool = False) -> Tensor:
'''
分割向量为N个头,如果是key的话,softmax时候,key需要转置一下
:param x:
:param is_key:
:return:
'''
batch_size = x.size(0)
# x (batch_size,seq_len,n_heads,d_key)
x = x.view(batch_size,-1,self.n_heads,self.d_key)
if is_key:
# (batch_size,n_heads,d_key,seq_len)
return x.permute(0,2,3,1)
# (batch_size,n_heads,seq_len,d_key
return x.transpose(1,2)
def merge_heads(self,x: Tensor) -> Tensor:
x = x.transpose(1,2).contigouse().view(x.size(0),-1,self.d_model)
return x
def attention(self,
query:Tensor,
key:Tensor,
value:Tensor,
mask:Tensor = None,
keep_attentions:bool = False):
scores = torch.matmul(query,key) / math.sqrt(self.d_key)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# weights (batch_size,n_heads,q_length,k_length)
weights = self.dropout(torch.softmax(scores,dim=-1))
# (batch_size,n_heads,q_length,k_length) x (batch_size,n_heads,v_length,d_key)
# -> (batch_size,n_heads,q_length,d_key)
# assert k_length == v_length
# attn_output (batch_size, n_heads, q_length, d_key)
atten_output = torch.matmul(weights,value)
if keep_attentions:
self.weights = weights
else:
del weights
return atten_output
def forward(self,
query: Tensor,
key: Tensor,
value: Tensor,
mask: Tensor = None,
keep_attentions: bool = False)-> Tuple[Tensor,Tensor]:
'''
:param query:(batch_size, q_length, d_model)
:param key:(batch_size, k_length, d_model)
:param value:(batch_size, v_length, d_model)
:param mask: mask for padding or decoder. Defaults to None.
:param keep_attentions: whether keep attention weigths or not. Defaults to False.
:return: (batch_size, q_length, d_model) attention output
'''
query = self.q(query)
key = self.k(key)
value = self.v(value)
query,key,value = (
self.split_heads(query),
self.split_heads(key,is_key=True),
self.split_heads(value)
)
atten_output = self.attention(query,key,value,mask,keep_attentions)
del query
del key
del value
# concat
concat_output = self.merge_heads(atten_output)
# the final liear
# output (batch_size, q_length, d_model)
output = self.concat(concat_output)
return output