1、环境准备及安装
1.1、linux环境
# 首先,已经预先安装好了anaconda,在这里新建一个环境
conda create -n sdwebui python=3.10
# 安装完毕后,激活该环境
conda activate sdwebui
# 安装
# 下载stable-diffusion-webui代码
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
cd stable-diffusion-webui
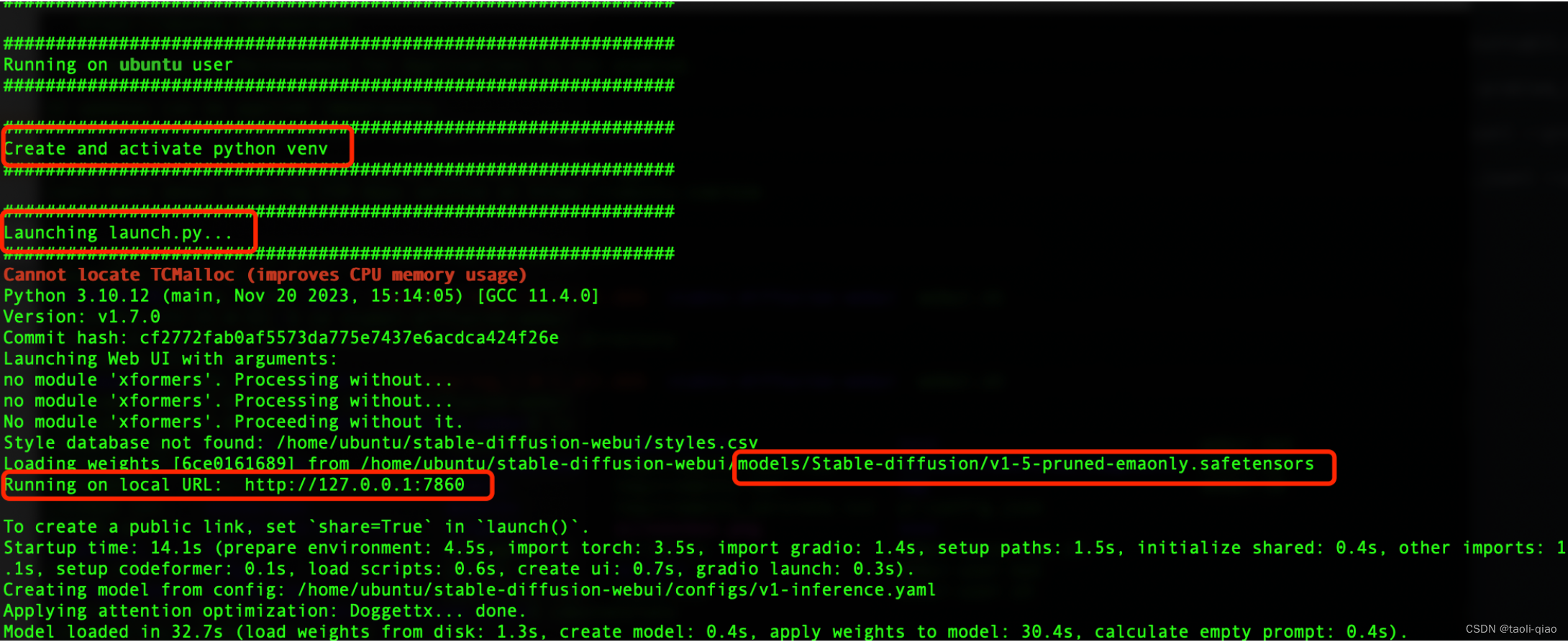
bash webui.sh -f
执行完之后,脚本会自动创建python环境、安装各种包、模型等。
2、使用
2.1、运行
安装完成前期的环境准备之后,之后每次运行只需要:
conda activate sdwebui
cd stable-diffusion-webui
bash webui.sh -f
# 或者按照如下方式,将sd放在后台执行
nohup bash webui.sh -f >> nohup.log 2>&1 &
该种方式会将进程运行在本地,可以通过ip+port的方式直接在网页上访问。 也可以通过如下方式进行简单的改造:
# 编辑webui-user.sh脚本
vim webui-user.sh
# 在终端中输入“i”进入编辑模式,移动到 COMMANDLINE_ARGS,并将其修改为:
export COMMANDLINE_ARGS="--listen --share --enable-insecure-extension-access"
上述命令含义如下:
--listen:将本地连接从127.0.0.1修改为0.0.0.0,即可通过服务器 IP:7861进行访问
--share:生成可供外网访问 Gradio 网址。
--enable-insecure-extension-access:使用–listen时,webui出于安全考虑会禁止用户在UI页面添加插件,添加该参数可允许用户添加插件。
--mdevram或 --lowvarm:降低显存消耗
PS:windows下的同理,在webui-user.bat中修改即可
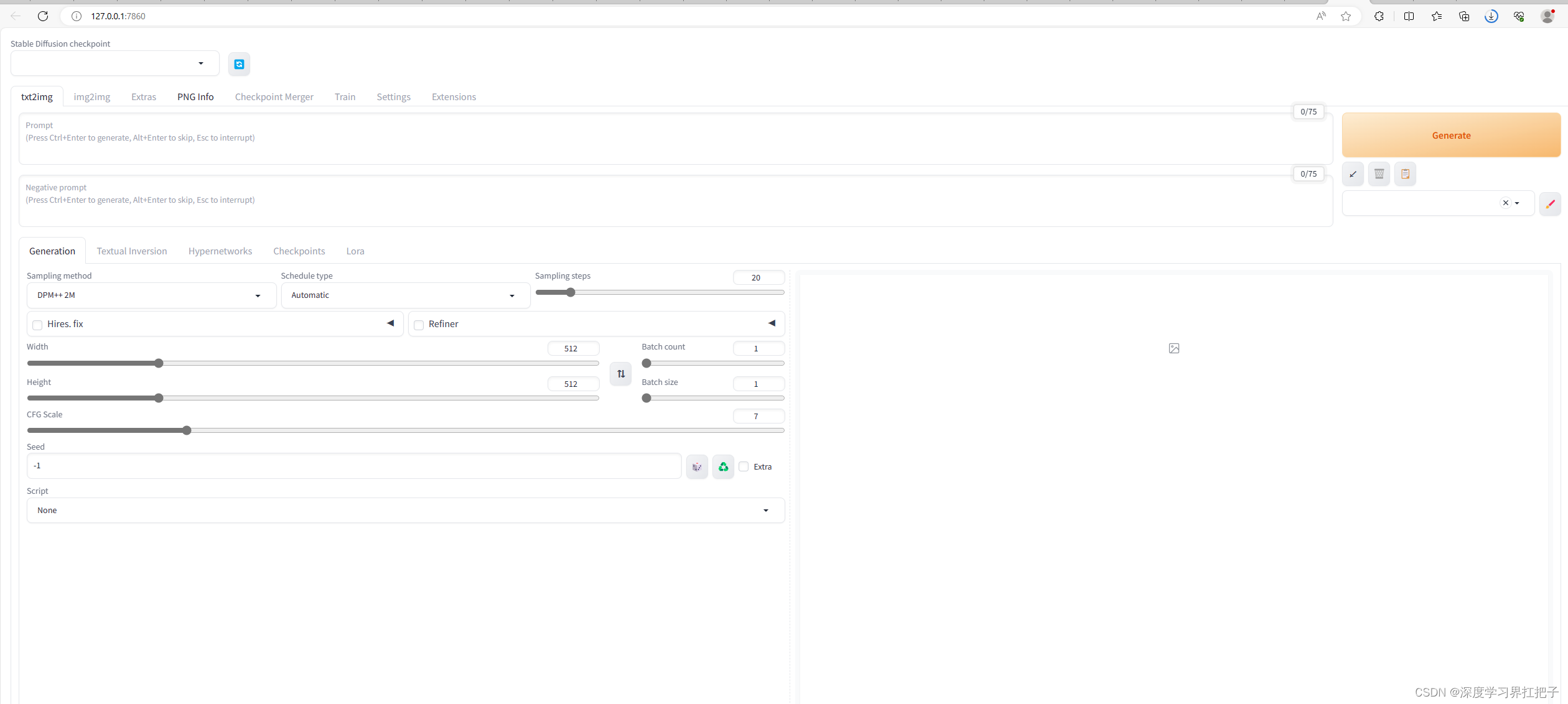
最终效果如下:

2.2、添加模型
2.2.1、各种常用模型
初步安装完成后,打开webui,可以看到左上角自带的模型。如下图示:

模型的分类大概有如下几种:
- CheckPoint
Checkpoint 是 Stable Diffusion 中最重要的模型,也是主模型,几乎所有的操作都要依托于主模型进行。所有的主模型都是基于 Stable Diffusion 模型训练而来.
主模型后缀一般为 .ckpt 或者 .safetensors,并且体积比较庞大,一般在 2G - 7G 之间。放置在 webUI 目录下的 `models/Stable-diffusion` 目录下。 - LoRA/LyCORIS
LoRA 是除了主模型外最常用的模型。LoRA 和 LyCORIS 都属于微调模型,一般用于控制画风、控制生成的角色、控制角色的姿势等等。
LoRA 和 LyCORIS 的后缀均为 .safetensors,体积较主模型要小得多,一般在 4M - 300M 之间。一般使用 LoRA 模型较多,而 LyCORIS 与 LoRA 相比可调节范围更大,但是需要额外的扩展才可使用。放置在 `models/LoRA` 目录下。 - Textual Inversion
Textual Inversion 是文本编码器模型,用于改变文字向量。可以将其理解为一组 Prompt。
Textual Inversion 后缀为 .pt 或者 .safetensors,体积非常小,一般只有几 kb。放置在 `embeddings` 目录下。 - Hypernetworks
Hypernetworks 模型用于调整模型神经网络权重,进行风格的微调。
Hypernetworks 的后缀为 .pt 或者 .safetensors,体积一般在 20M - 200M 之间。放置在 `models/hypernetworks` 目录下。 - ControlNet
ControlNet 是一个及其强大的控制模型,它可以做到画面控制、动作控制、色深控制、色彩控制等等。使用时需要安装相应的扩展才可。
ControlNet 类模型的后缀为 .safetensors。放置在 `models/ControlNet` 目录下。
使用时我们需要先去 Extensions 页面搜索 ControlNet 扩展,然后 Install 并 Reload UI。然后便可以在 txt2img 和 img2img 菜单下找到。 - VAE
VAE全称是变分自动编码器 (Variational Auto-Encoder),是机器学习中的一种人工神经网络结构。VAE在sd模型中负责微调,类似我们熟知的滤镜,调整生成图片的饱和度。
默认的sd-webui页面并没有VAE的设置,需要进入:Settings->User interface->Quick settings list,在输入框中添加sd_vae。然后依次点击Apply settings和Reload UI。随后就会在webui中看到对应区域。
下载好上述模型之后,可以在页面上直接通过标签进入选中,可以直接prompt使用:

2.3、问题
2.3.1、stable diffusion 安装tagger之后报错Attempt to free invalid pointer
报错信息:
20xx-xx-xx 10:35:12.003960: I tensorflow/core/util/port.cc:113] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
20xx-xx-xx 10:35:12.143798: I external/local_tsl/tsl/cuda/cudart_stub.cc:31] Could not find cuda drivers on your machine, GPU will not be used.
20xx-xx-xx 10:35:12.762893: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
20xx-xx-xx 10:35:12.762960: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
20xx-xx-xx 10:35:12.888382: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
src/tcmalloc.cc:283] Attempt to free invalid pointer 0x59c2527199d0
解决:
参考:github.com/AUTOMATIC11…
①在centos7环境下,安装jemalloc
yum install epel-release
yum install jemalloc
②添加到webui-user.sh
export LD_PRELOAD="/usr/lib64/libjemalloc.so.1"
3、关键词(提示词)书写
3.1、使用示例
示例1: 提前下载Checkpoint模型:‘CheckpointLigneClair_120’
可以到p站上下载:civitai.com/
masterpiece,1girl,solo,incredibly absurdres,hoodie,headphones, street,outdoors,rain,neon lights, light smile, hood up, hands in pockets, looking away, from side,asymmetrical bangs, beautiful detailed eyes, eye shadow, huge clocks, glass strips, floating glass fragments, colorful refraction, beautiful detailed sky, dark intense shadows, cinematic lighting, overexposure, expressionless, blank stare, big top sleeves, frills, hair ornament, ribbon, bowtie, buttons, small breasts, pleated skirt, sharp focus, masterpiece, best quality, extremely detailed, colorful, hdr
Sampler: DPM++ 2M Karras
Negative prompt: EasyNegative
CFG scale: 7
Steps: 20
效果如下:

3.2、Controlnet
3.2.1、Controlnet部署使用
1、插件安装:Extension->Install from URL->输入:jihulab.com/hanamizuki/… ->点击Install->安装完毕后,重启ui,可以看到controlnet:

2、controlnet模型安装
进入如下网址:huggingface.co/lllyasviel/… 下载所有pth文件,然后放置到:~/stable-diffusion-webui/extensions/sd-webui-controlnet/models 路径下(yaml文件已有,如果没有可以在url中重新下载)
3.2.2、Controlnet常见模型
汇总如下:
| 类别 | ControlNet模型 | 功能 |
|---|---|---|
| 边缘轮廓 | canny | 边缘检测,根据线稿生图 |
| 边缘轮廓 | mlsd | 直线检测,适用于建筑设计 |
| 边缘轮廓 | softedge | 软边缘检测,保留更多边缘细节 |
| 边缘轮廓 | scribble | 涂鸦生图 |
| 边缘轮廓 | lineart | 提取精细线稿生图 |
| 边缘轮廓 | lineart_anime | 提取动漫线稿 |
| 深度结构 | depth | 深度检测,根据深度信息生图 |
| 深度结构 | normalbae | 法线贴图,提取法线信息 |
| 图片元素 | seg | 语义分割,不同颜色语义代表不同对象类型 |
| 图片元素 | normalbae | 人物姿势检测,根据姿势生图 |
| 图像处理 | inpaint | 图像扩展和修复 |
| 图像处理 | shuffle | 风格迁移融合 |
| 图像处理 | ip2p | 对图片进行指令式变换 |
| 图像处理 | tile | 细节增强 |
3.2.3、Canny
Canny用于识别输入图像的边缘信息。分成两个部分,canny预处理器和canny模型:
首先canny预处理器从上传的图片中生成线稿;然后canny模型根据关键词来生成与上传图片相同构图的画面。
(1)线稿生图
步骤如下:
首先将controlnet插件的enable打开
->如果显存不足(小于4G),还可以将Low VRAM打开
->如果是白底黑线的线稿,Preprocessor选择invert,如果是黑底白线的线稿,Preprocessor选择none
->Model选择canny
->Resize Mode选择Resize and Fill(不然比例会不对) 然后选择合适的sd model,输入prompt,我这里是: (masterpiece:1.2), (best quality), (ultra detailed), (8k, 4k, intricate), oil painting texture, 1girl, solo, black eyes, pink hair, lightly smile, upper body, blue shirts, simple background, lips, long hair, black hair 最后效果如下:
图上红框中选择的controlnet模型为control_v11p_sd15_canny,其含义如下:
(2)以图生图
一般用来给图换色,和第一步不同的是,将Preprocessor选择canny,其他可以保持不变: 
3.2.4、Reference
Reference 是官方最新推出的预处理器,共有三种:Reference_only、Reference_adain和Reference_adain+atten。它只有yaml配置文件,没有pth模型文件,可以根据上传的图像生成类似的变体。
使用reference_only的预处理器和0.5的Style Fidelity:
(相比之前,添加了angry标签) 
3.2.5、Tile
Tile 模型的作用是可以忽略原图的细节,根据现有像素和提示词生成新的细节,目前主要作用是将严重模糊的图片放大并变得高清.
选择tile_resample的预处理器和control_v11f1e_sd15_tile的模型,结果如下:

3.2.6、T2I- Adapter
将一张图片的风格迁移到另一张图片上
3.3、Tag反推
根据图片,一键反推提示词,反推的关键词更精准,生成的图片效果也更接近于原图
3.3.1、安装
两种安装方法:
1、extension->available->搜索wd 4,点击install,安装完毕后,使用install页面的’Apply and restart UI’
实测使用之后会报错:
2024-01-03 14:59:08.369709: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2024-01-03 14:59:08.369772: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2024-01-03 14:59:08.370929: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
src/tcmalloc.cc:284] Attempt to free invalid pointer 0xaa705c0
webui.sh: line 256: 7687 Aborted (core dumped) "${python_cmd}" -u "${LAUNCH_SCRIPT}" "$@"
两种解决方法:
① 注释掉这行代码(在Requirements文件中)
%env LD_PRELOAD=libtcmalloc.so
②使用jemalloc优化内存分配
1、在centos7.x中执行
yum install epel-release
yum install jemalloc
2、在webui-user.sh中添加
export LD_PRELOAD="/usr/lib64/libjemalloc.so.1"
2、第二种方法是直接下载
下载地址: github.com/toriato/sta… 之后重启ui,重启成功后即可在stable-diffusion中看到“Tag反推(Tagger)”
3.3.2、使用
选中Tagger标签,上传一张图片,点击interrogate image,即可生成图片的对应标签

写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。