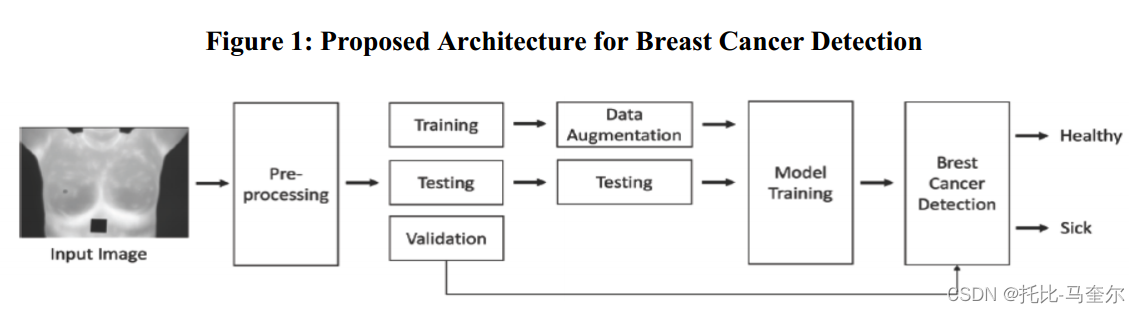
ICESat-2 ATL08 数据概述
ICESat-2(Ice, Cloud, and land Elevation Satellite-2)是美国宇航局(NASA)的一颗卫星,旨在测量地球的冰盖、云层和陆地的高程。ATL08数据产品专注于测量地表高程和植被的高度,主要用于研究森林、草地和冰川等地表特征。
ATL08 数据产品结构
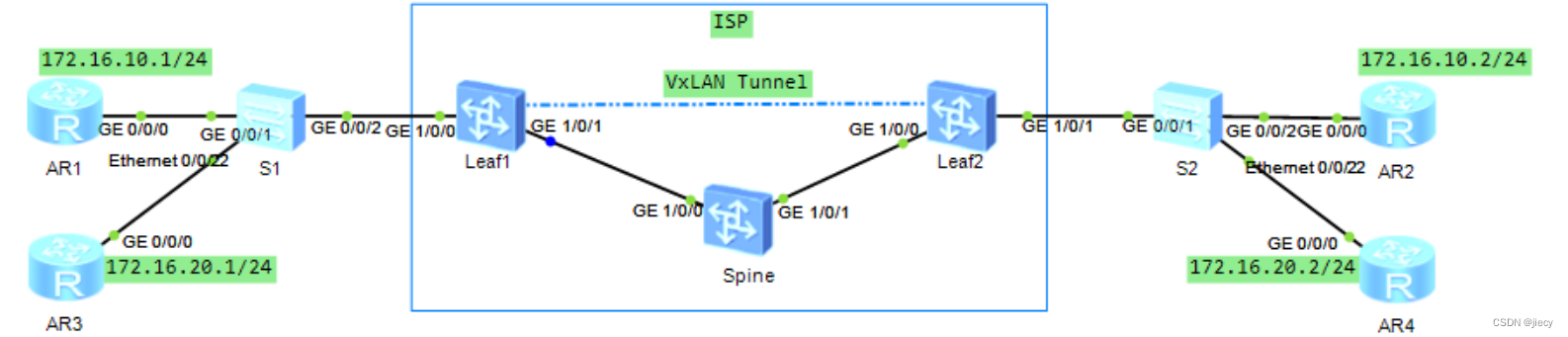
ATL08数据产品是一个HDF5格式的文件,包含多个数据组(group),每个数据组对应卫星的一个激光光束。ICESat-2有三个激光光束,每个光束分为左(left, l)和右(right, r)两个子光束,因此总共有六个数据组:/gt1l、/gt1r、/gt2l、/gt2r、/gt3l、/gt3r。
主要数据字段
每个光束数据组下包含多个数据字段,以下是一些关键字段的解释:
latitude: 光子测量点的纬度。
longitude: 光子测量点的经度。
h_canopy: 植被顶端的高度(相对于参考椭球面)。
h_canopy_uncertainty: 植被高度的不确定性。
dem_h: 数字高程模型(DEM)中的地形高度。
下面是一个可以批量读取ICESat-2 ATL08数据的脚本,可以根据需要的变量进行改写。同时可以使用HDFView查看 ATL08 数据的变量内容。
import h5py import os import pandas as pd from datetime import datetime, timedelta def extract_track_info(fname): """ 从文件名中提取轨道号、时间和周期信息。 参数: fname (str): 文件名。 返回: info (dict): 包含轨道号、时间和周期信息的字典。 """ try: base_name = os.path.basename(fname) parts = base_name.split('_') info = { 'date': parts[1], 'track': int(parts[2][:4]), 'cycle': int(parts[2][4:6]) } return info except (IndexError, ValueError) as e: print(f"文件名格式错误: {fname}, 错误信息: {e}") return None def read_atl08(fname): """ 读取ICESat-2 ATL08数据,并返回数据和每个光束的数据。 参数: fname (str): HDF5文件的路径。 返回: trajectory_data (dict): 包含每个光束数据的字典。 """ groups = ['/gt1l', '/gt1r', '/gt2l', '/gt2r', '/gt3l', '/gt3r'] trajectory_data = {} try: with h5py.File(fname, 'r') as fi: for g in groups: lat = fi[g + '/land_segments/latitude'][:] lon = fi[g + '/land_segments/longitude'][:] dem_h = fi[g + '/land_segments/dem_h'][:] h_te_best_fit = fi[g + '/land_segments/terrain/h_te_best_fit'][:] h_te_best_mean = fi[g + '/land_segments/terrain/h_te_mean'][:] h_te_median = fi[g + '/land_segments/terrain/h_te_median'][:] h_te_interp = fi[g + '/land_segments/terrain/h_te_interp'][:] terrain_slope = fi[g + '/land_segments/terrain/terrain_slope'][:] cloud_flag_atm = fi[g + '/land_segments/cloud_flag_atm'][:] result = pd.DataFrame({ 'lon': lon, 'lat': lat, 'dem_h': dem_h, 'h_te_best_fit': h_te_best_fit, 'h_te_best_mean': h_te_best_mean, 'h_te_median': h_te_median, 'h_te_interp': h_te_interp, 'terrain_slope': terrain_slope, 'cloud_flag_atm': cloud_flag_atm }) trajectory_data[g] = result except Exception as e: print(f"读取文件失败: {fname}, 错误信息: {e}") return None return trajectory_data def read_icesat2_ATL08_files(folder_path): """ 处理文件夹中的所有HDF5文件,并根据轨道号、时间和周期进行分组。 参数: folder_path (str): 文件夹路径。 返回: grouped_data_by_cycle (dict): 包含每个周期的数据字典。 """ file_list = [] grouped_data_by_cycle = {} groups = ['/gt1l', '/gt1r', '/gt2l', '/gt2r', '/gt3l', '/gt3r'] for file_name in os.listdir(folder_path): if file_name.endswith('.h5'): file_path = os.path.join(folder_path, file_name) file_info = extract_track_info(file_name) if file_info is not None: file_list.append((file_path, file_info)) for file_path, file_info in file_list: cycle = file_info['cycle'] if cycle not in grouped_data_by_cycle: grouped_data_by_cycle[cycle] = {} grouped_data_by_cycle[cycle][file_path] = file_info for cycle, files_info in grouped_data_by_cycle.items(): print(f"处理周期: {cycle}") cycle_dates = [] for file_path, file_info in files_info.items(): if isinstance(file_info, dict): print(f"读取文件: {file_path}") trajectory_data = read_atl08(file_path) if trajectory_data is not None: grouped_data_by_cycle[cycle][file_path] = trajectory_data file_date = datetime.strptime(file_info['date'], '%Y%m%d%H%M%S') cycle_dates.append(file_date) if cycle_dates: avg_date = datetime.fromtimestamp(sum(d.timestamp() for d in cycle_dates) / len(cycle_dates)) avg_date_str = avg_date.strftime('%Y-%m-%d') else: avg_date_str = None grouped_data_by_cycle[cycle]['average_date'] = avg_date_str return grouped_data_by_cycle