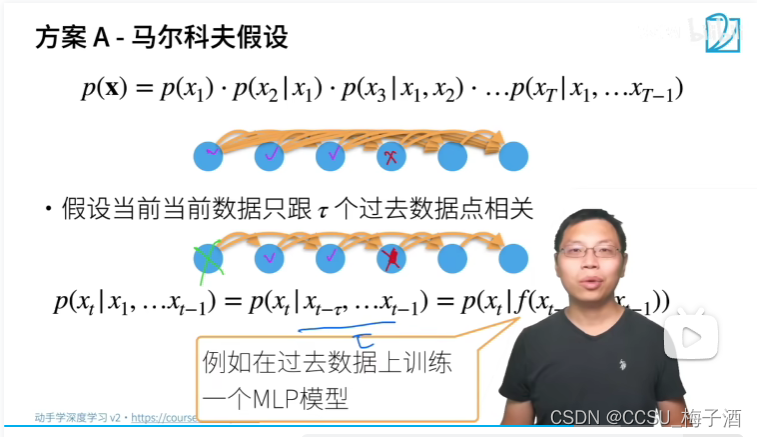
探讨多模态视觉语言模型的一些有趣结论欢迎关注 CVHub!![]() https://mp.weixin.qq.com/s/zouNu-g-33_7JoX3Uscxtw1.Introduction
https://mp.weixin.qq.com/s/zouNu-g-33_7JoX3Uscxtw1.Introduction
多模态模型架构上的变化不大,数据的差距比较大,输入分辨率和输入llm的视觉token大小是比较关键的,适配器,VIT和语言模型则不是那么关键。InternVL-1.5,Qwen-VL-Max和DeepSeek-VL利用了Laion-5B和COYO这样的大规模预训练数据,数据量达到10亿,InternVL-1.5将sft划分为11个子类,并为每个子类收集相应的开源数据,对于预训练数据,LLM存在一个scaling law,但是在LVM中尚未发现。LLaVA在60多万数据上预训练,15w数据上sft效果就很好了。