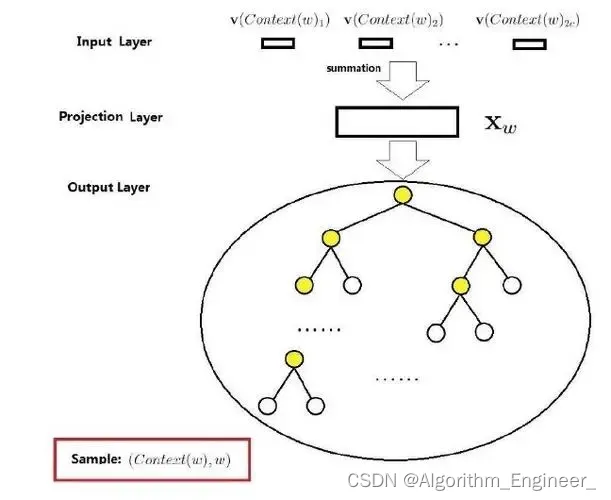
目录
1. 作者介绍
朱梓慧,女,西安工程大学电子信息学院,2023级研究生
研究方向:机器视觉与人工智能
电子邮件:1556867689@qq.com
徐达,男,西安工程大学电子信息学院,2023级研究生,张宏伟人工智能课题组
研究方向:机器视觉与人工智能
电子邮件:1374455905@qq.com
2. 基于网格的CLIQUE聚类算法介绍
2.1 算法介绍
CLIQUE算法是基于网格的空间聚类算法,但它同时也非常好的结合了基于密度的聚类算法,因此既能够发现任意形状的簇,又可以像基于网格的算法一样处理较大的多维数据。
CLIQUE就是将数据空间划分为网格单元,将数据对象集映射到网格单元中,并计算每个单元的密度。根据预设的 密度阈值 判断每个网格单元是否为 高密度单元,由邻近的稠密单元组形成 “类”(簇)。
总结之就是:CLIQUE算法是一种基于网格的聚类算法,用于发现子空间中基于密度的簇。
2.2 算法概述
1、算法需要的两个参数:
网格步长–确定空间的划分
密度阈值–网格中对象数量大于等于该阈值表示该网格为稠密网格
2、聚类思想:
(1)首先扫描所有网格。当发现第一个密集网格时,便以该网格开始扩展,扩展原则是若一个网格与已知密集区域内的网格邻接并且其自身也是密集的,则将该网格加入到该密集区域中,直到不再有这样的网格为止。(密集网格合并)
(2)算法再继续扫描网格并重复上述过程,直到所有网格被遍历。以自动地发现最高维的子空间,高密度聚类存在于这些子空间中,并且对元组的输入顺序不敏感,无需假设任何规范的数据分布,它随输入数据的大小线性地扩展,当数据的维数增加时具有良好的可伸缩性。
2.3 算法步骤
(1) 划分数据空间为不重叠的矩形单元
- 计算每个网格的密度
- 根据阀值识别稠密网格和非稠密网格
- 所有网格初始状态设为“未处理标记”
(2)遍历所有网格判断当前网格是否为“未处理标记
-是 --> 进入步骤4
-否 --> 处理下一个网格 (返回步骤3)
(3)改变网格标记为“已处理”判断网格是否为稠密网格
-是 --> 进入步骤5
-否 --> 返回步骤3
(4)稠密网格处理
-赋予新的簇标记
-创建队列并将稠密网格置入队列
(5)判断队列是否为空
-是 --> 返回步骤3
-否 --> 进入步骤7
(6)处理队列
-取出队头的网格元素
-检查所有邻接的“未处理标记”网格
-更改网格标记为“已处理”
-若邻接网格为稠密网格赋予当前簇标记
-加入队列
(7) 密度连通区域检查结束
-标记相同的稠密网格组成密度连通区域即目标簇
(8) 进行下一簇的查找
-返回步骤3
(9)遍历整个数据集
-将数据元素标记为所在网格的簇标记值
2.4 算法优缺点
优点:
(1) 给定每个属性的划分,单遍数据扫描就可以确定每个对象的网格单元和网格单元的计数。
(2) 尽管潜在的网格单元数量可能很高,但是只需要为非空单元创建网格。
(3) 将每个对象指派到一个单元并计算每个单元的密度的时间复杂度和空间复杂度为O(m),整个聚类过程是非常高效的
缺点:
(1) 像大多数基于密度的聚类算法一样,基于网格的聚类非常依赖于密度阈值的选择。(太高,簇可能丢失。太低,本应分开的簇可能被合并)
(2) 如果存在不同密度的簇和噪声,则有可能找不到适合于数据空间所有部分的值。
(3) 随着维度的增加,网格单元个数迅速增加(指数增长)。即对于高维数据,基于网格的聚类倾向于效果很差。
3. 基于网格的CLIQUE鸢尾花数据集聚类
3.1 实验代码
(1)Clique.py
import os
import sys
import numpy as np
import scipy.sparse.csgraph
from Cluster import Cluster
from sklearn import metrics
from ast import literal_eval
# 从scikit-learn中加载鸢尾花数据集
from sklearn.datasets import load_iris
from Visualization import plot_clusters
# Inserts joined item into candidates list only if its dimensionality fits
def insert_if_join_condition(candidates, item, item2, current_dim):
joined = item.copy()
joined.update(item2)
if (len(joined.keys()) == current_dim) & (not candidates.__contains__(joined)):
candidates.append(joined)
# Prune all candidates, which have a (k-1) dimensional projection not in (k-1) dim dense units
def prune(candidates, prev_dim_dense_units):
for c in candidates:
if not subdims_included(c, prev_dim_dense_units):
candidates.remove(c)
def subdims_included(candidate, prev_dim_dense_units):
for feature in candidate:
projection = candidate.copy()
projection.pop(feature)
if not prev_dim_dense_units.__contains__(projection):
return False
return True
def self_join(prev_dim_dense_units, dim):
candidates = []
for i in range(len(prev_dim_dense_units)):
for j in range(i + 1, len(prev_dim_dense_units)):
insert_if_join_condition(
candidates, prev_dim_dense_units[i], prev_dim_dense_units[j], dim)
return candidates
def is_data_in_projection(tuple, candidate, xsi):
for feature_index, range_index in candidate.items():
feature_value = tuple[feature_index]
if int(feature_value * xsi % xsi) != range_index:
return False
return True
def get_dense_units_for_dim(data, prev_dim_dense_units, dim, xsi, tau):
candidates = self_join(prev_dim_dense_units, dim)
prune(candidates, prev_dim_dense_units)
# Count number of elements in candidates
projection = np.zeros(len(candidates))
number_of_data_points = np.shape(data)[0]
for dataIndex in range(number_of_data_points):
for i in range(len(candidates)):
if is_data_in_projection(data[dataIndex], candidates[i], xsi):
projection[i] += 1
print("projection: ", projection)
# Return elements above density threshold
is_dense = projection > tau * number_of_data_points
print("is_dense: ", is_dense)
return np.array(candidates)[is_dense]
def build_graph_from_dense_units(dense_units):
graph = np.identity(len(dense_units))
for i in range(len(dense_units)):
for j in range(len(dense_units)):
graph[i, j] = get_edge(dense_units[i], dense_units[j])
return graph
def get_edge(node1, node2):
dim = len(node1)
distance = 0
if node1.keys() != node2.keys():
return 0
for feature in node1.keys():
distance += abs(node1[feature] - node2[feature])
if distance > 1:
return 0
return 1
def save_to_file(clusters, file_name):
file = open(os.path.join(os.path.abspath(os.path.dirname(
__file__)), file_name), encoding='utf-8', mode="w+")
for i, c in enumerate(clusters):
c.id = i
file.write("Cluster " + str(i) + ":\n" + str(c))
file.close()
def get_cluster_data_point_ids(data, cluster_dense_units, xsi):
point_ids = set()
# Loop through all dense unit
for u in cluster_dense_units:
tmp_ids = set(range(np.shape(data)[0]))
# Loop through all dimensions of dense unit
for feature_index, range_index in u.items():
tmp_ids = tmp_ids & set(
np.where(np.floor(data[:, feature_index] * xsi % xsi) == range_index)[0])
point_ids = point_ids | tmp_ids
return point_ids
def get_clusters(dense_units, data, xsi):
graph = build_graph_from_dense_units(dense_units)
number_of_components, component_list = scipy.sparse.csgraph.connected_components(
graph, directed=False)
dense_units = np.array(dense_units)
clusters = []
# For every cluster
for i in range(number_of_components):
# Get dense units of the cluster
cluster_dense_units = dense_units[np.where(component_list == i)]
print("cluster_dense_units: ", cluster_dense_units.tolist())
# Get dimensions of the cluster
dimensions = set()
for u in cluster_dense_units:
dimensions.update(u.keys())
# Get points of the cluster
cluster_data_point_ids = get_cluster_data_point_ids(
data, cluster_dense_units, xsi)
# Add cluster to list
clusters.append(Cluster(cluster_dense_units,
dimensions, cluster_data_point_ids))
return clusters
def get_one_dim_dense_units(data, tau, xsi):
number_of_data_points = np.shape(data)[0]
number_of_features = np.shape(data)[1]
projection = np.zeros((xsi, number_of_features))
for f in range(number_of_features):
for element in data[:, f]:
projection[int(element * xsi % xsi), f] += 1
print("1D projection:\n", projection, "\n")
is_dense = projection > tau * number_of_data_points
print("is_dense:\n", is_dense)
one_dim_dense_units = []
for f in range(number_of_features):
for unit in range(xsi):
if is_dense[unit, f]:
dense_unit = dict({f: unit})
one_dim_dense_units.append(dense_unit)
return one_dim_dense_units
# Normalize data in all features (1e-5 padding is added because clustering works on [0,1) interval)
def normalize_features(data):
normalized_data = data
number_of_features = np.shape(normalized_data)[1]
for f in range(number_of_features):
normalized_data[:, f] -= min(normalized_data[:, f]) - 1e-5
normalized_data[:, f] *= 1 / (max(normalized_data[:, f]) + 1e-5)
return normalized_data
def evaluate_clustering_performance(clusters, labels):
set_of_dimensionality = set()
for cluster in clusters:
set_of_dimensionality.add(frozenset(cluster.dimensions))
# Evaluating performance in all dimensionality
for dim in set_of_dimensionality:
print("\nEvaluating clusters in dimension: ", list(dim))
# Finding clusters with same dimensions
clusters_in_dim = []
for c in clusters:
if c.dimensions == dim:
clusters_in_dim.append(c)
clustering_labels = np.zeros(np.shape(labels))
for i, c in enumerate(clusters_in_dim):
clustering_labels[list(c.data_point_ids)] = i + 1
print("Number of clusters: ", len(clusters_in_dim))
print("Adjusted Rand index: ", metrics.adjusted_rand_score(
labels, clustering_labels))
print("Mutual Information: ", metrics.adjusted_mutual_info_score(
labels, clustering_labels))
print("Homogeneity, completeness, V-measure: ",
metrics.homogeneity_completeness_v_measure(labels, clustering_labels))
print("Fowlkes-Mallows: ",
metrics.fowlkes_mallows_score(labels, clustering_labels))
def run_clique(data, xsi, tau):
# Finding 1 dimensional dense units
dense_units = get_one_dim_dense_units(data, tau, xsi)
# Getting 1 dimensional clusters
clusters = get_clusters(dense_units, data, xsi)
# Finding dense units and clusters for dimension > 2
current_dim = 2
number_of_features = np.shape(data)[1]
while (current_dim <= number_of_features) & (len(dense_units) > 0):
print("\n", str(current_dim), " dimensional clusters:")
dense_units = get_dense_units_for_dim(
data, dense_units, current_dim, xsi, tau)
for cluster in get_clusters(dense_units, data, xsi):
clusters.append(cluster)
current_dim += 1
return clusters
def read_labels(delimiter, label_column, path):
return np.genfromtxt(path, dtype="U10", delimiter=delimiter, usecols=[label_column])
def read_data(delimiter, feature_columns, path):
return np.genfromtxt(path, dtype=float, delimiter=delimiter, usecols=feature_columns)
# 主程序部分
if __name__ == "__main__":
print("Running CLIQUE algorithm on Iris dataset")
# 从鸢尾花数据集加载数据和标签
iris = load_iris()
original_data = iris.data
labels = iris.target
# 标准化数据
data = normalize_features(original_data)
# 设置参数
xsi = 3
tau = 0.1
clusters = run_clique(data=data, xsi=xsi, tau=tau)
output_file = "output_clusters.txt"
save_to_file(clusters, output_file)
print("\nClusters exported to " + output_file)
# 评估结果
evaluate_clustering_performance(clusters, labels)
# 可视化聚类结果
title = f"Clustering Results with Iris Dataset - Parameters: Tau={tau} Xsi={xsi}"
plot_clusters(data, clusters, title, xsi)
(2) Cluster
class Cluster:
def __init__(self, dense_units, dimensions, data_point_ids):
self.id = None
self.dense_units = dense_units
self.dimensions = dimensions
self.data_point_ids = data_point_ids
def __str__(self):
return "Dense units: " + str(self.dense_units.tolist()) + "\nDimensions: " \
+ str(self.dimensions) + "\nCluster size: " + str(len(self.data_point_ids)) \
+ "\nData points:\n" + str(self.data_point_ids) + "\n"
(3) Visualization.py
import math
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
def plot_clusters(data, clusters, title, xsi):
# Check if there are clusters to plot
if len(clusters) <= 0:
return
ndim = data.shape[1]
nrecords = data.shape[0]
data_extent = [[min(data[:, x]), max(data[:, x])] for x in range(0, ndim)]
plt_cmap = plt.cm.tab10
plt_marker_size = 10
plt_spacing = 0 # change spacing to apply a margin to data_extent
fig, axs = plt.subplots(1, 2, figsize=(14, 7))
# Plot 1D clusters
clusters_in_1d = [c for c in clusters if len(c.dimensions) == 1]
ax1 = axs[0]
for i, c in enumerate(clusters_in_1d):
c_size = len(c.data_point_ids)
c_attrs = list(c.dimensions)
c_elems = list(c.data_point_ids)
x = data[c_elems, 0] if c_attrs[0] == 0 else [0] * c_size
y = [0] * c_size
ax1.scatter(x, y, s=plt_marker_size, c=[plt_cmap(c.id)], label=f"Cluster {c.id}")
ax1.set_xlim(data_extent[0][0] - plt_spacing, data_extent[0][1] + plt_spacing)
ax1.set_ylim(-0.1, 0.1)
ax1.set_title("1-dimensional clusters")
ax1.legend(title="Cluster ID")
# Plot 2D clusters
clusters_in_2d = [c for c in clusters if len(c.dimensions) == 2]
ax2 = axs[1]
for i, c in enumerate(clusters_in_2d):
c_size = len(c.data_point_ids)
c_attrs = list(c.dimensions)
c_elems = list(c.data_point_ids)
x = data[c_elems, c_attrs[0]]
y = data[c_elems, c_attrs[1]]
ax2.scatter(x, y, s=plt_marker_size, c=[plt_cmap(c.id)], label=f"Cluster {c.id}")
ax2.set_xlim(data_extent[0][0] - plt_spacing, data_extent[0][1] + plt_spacing)
ax2.set_ylim(data_extent[1][0] - plt_spacing, data_extent[1][1] + plt_spacing)
ax2.set_title("2-dimensional clusters")
ax2.legend(title="Cluster ID")
fig.suptitle(title)
plt.show()
# Plot 3D clusters
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
clusters_in_3d = [c for c in clusters if len(c.dimensions) == 3]
for i, c in enumerate(clusters_in_3d):
c_size = len(c.data_point_ids)
c_attrs = list(c.dimensions)
c_elems = list(c.data_point_ids)
x = data[c_elems, c_attrs[0]]
y = data[c_elems, c_attrs[1]]
z = data[c_elems, c_attrs[2]]
ax.scatter(x, y, z, s=plt_marker_size, c=[plt_cmap(c.id)], label=f"Cluster {c.id}")
ax.set_xlim(data_extent[0][0] - plt_spacing, data_extent[0][1] + plt_spacing)
ax.set_ylim(data_extent[1][0] - plt_spacing, data_extent[1][1] + plt_spacing)
ax.set_zlim(data_extent[2][0] - plt_spacing, data_extent[2][1] + plt_spacing)
ax.set_title("3-dimensional clusters")
ax.legend(title="Cluster ID")
plt.show()
# Plot 4D clusters (3D with color indicating the 4th dimension)
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
clusters_in_4d = [c for c in clusters if len(c.dimensions) == 4]
for i, c in enumerate(clusters_in_4d):
c_size = len(c.data_point_ids)
c_attrs = list(c.dimensions)
c_elems = list(c.data_point_ids)
x = data[c_elems, c_attrs[0]]
y = data[c_elems, c_attrs[1]]
z = data[c_elems, c_attrs[2]]
color = data[c_elems, c_attrs[3]]
scatter = ax.scatter(x, y, z, s=plt_marker_size, c=color, cmap=plt_cmap, label=f"Cluster {c.id}")
fig.colorbar(scatter, ax=ax, label="4th dimension")
ax.set_xlim(data_extent[0][0] - plt_spacing, data_extent[0][1] + plt_spacing)
ax.set_ylim(data_extent[1][0] - plt_spacing, data_extent[1][1] + plt_spacing)
ax.set_zlim(data_extent[2][0] - plt_spacing, data_extent[2][1] + plt_spacing)
ax.set_title("4-dimensional clusters (3D with color for 4th dimension)")
ax.legend(title="Cluster ID")
plt.show()
3.2 代码内容
数据加载和预处理:
(1)从scikit-learn加载鸢尾花数据集,包括特征数据和标签。
(2)对数据进行标准化,使每个特征的值在[0,1)范围内。
3.3 CLIQUE算法实现
insert_if_join_condition: 在满足特定条件时将候选集插入列表。
prune: 剪枝操作,移除不满足条件的候选集。
self_join: 对前一个维度的稠密单元进行自连接生成新的候选集。
is_data_in_projection: 检查数据点是否在候选投影中。
get_dense_units_for_dim: 计算在当前维度上的稠密单元。
build_graph_from_dense_units: 从稠密单元构建图。
get_edge: 获取两个稠密单元之间的边。
get_cluster_data_point_ids: 获取属于某个聚类的数据点ID。
get_clusters: 获取聚类结果。
get_one_dim_dense_units: 获取一维稠密单元。
normalize_features: 对特征进行标准化。
evaluate_clustering_performance: 评估聚类性能
CLIQUE算法运行:
(1)使用run_clique函数来运行CLIQUE算法,获取所有维度上的稠密单元和聚类结果。
(2)将聚类结果保存到文件中。
(3)评估聚类性能,打印调整兰德指数、互信息、同质性、完整性、V测度和Fowlkes-Mallows指数。
可视化聚类结果:
使用plot_clusters函数来可视化聚类结果。