Spark Streaming 原生支持一些不同的数据源。
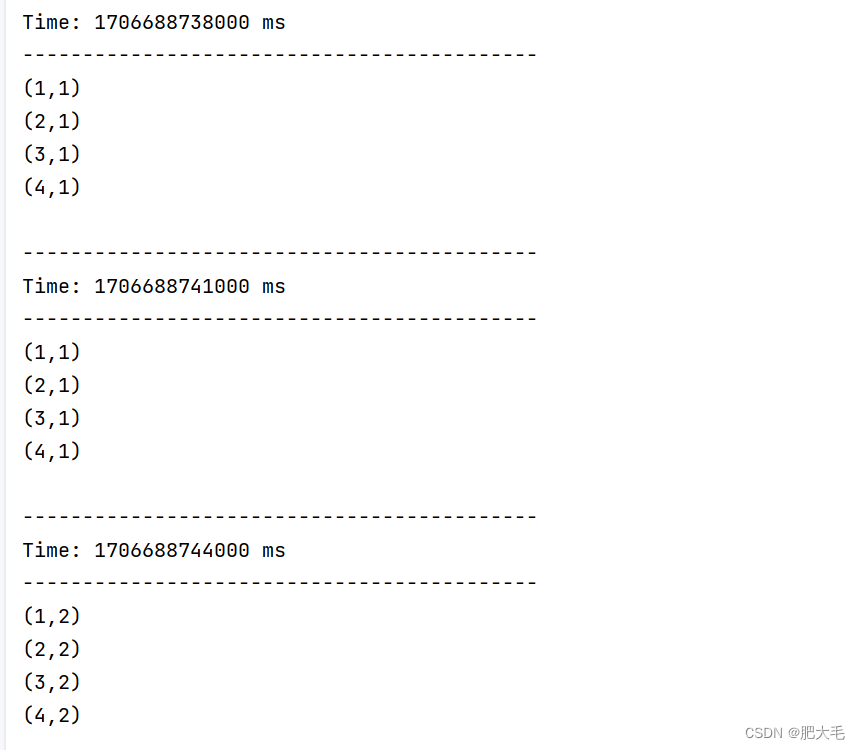
RDD队列
用法说明
通过使用ssc.queueStream(queueOfRDDs)来创建DStream,
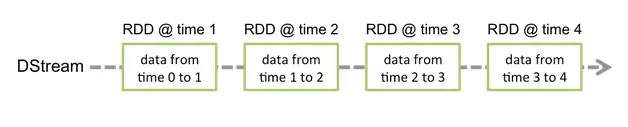
每一个推送到这个队列中的RDD,都会作为一个DStream处理。
案例实操
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object RDDQueueDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDDQueueDemo").setMaster("local[*]")
val scc = new StreamingContext(conf, Seconds(5))
val sc = scc.sparkContext
val queue: mutable.Queue[RDD[Int]] = mutable.Queue[RDD[Int]]()
val rddDS: InputDStream[Int] = scc.queueStream(queue, true)
rddDS.reduce(_ + _).print
scc.start
for (elem <- 1 to 5) {
queue += sc.parallelize(1 to 100)
Thread.sleep(2000)
}
scc.awaitTermination()
}
}
自定义数据源
使用及说明
其实就是自定义接收器
需要继承Receiver,并实现onStart、onStop方法来自定义数据源采集。
案例实操
自定义数据源,实现监控某个端口号,获取该端口号内容。
自定义数据源
object MySource{
def apply(host: String, port: Int): MySource = new MySource(host, port)
}
class MySource(host: String, port: Int) extends Receiver[String](StorageLevel.MEMORY_ONLY){
override def onStart(): Unit = {
new Thread("Socket Receiver"){
override def run(): Unit = {
receive()
}
}.start()
}
def receive()={
val socket = new Socket(host, port)
val reader = new BufferedReader(new InputStreamReader(socket.getInputStream, StandardCharsets.UTF_8))
var line: String = null
while (!isStopped && (line = reader.readLine()) != null ){
store(line)
}
reader.close()
socket.close()
restart("Trying to connect again")
}
override def onStop(): Unit = {
}
}
使用自定义数据源
object MySourceDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("StreamingWordCount").setMaster("local[*]")
val ssc = new StreamingContext(conf, Seconds(5))
val lines: ReceiverInputDStream[String] = ssc.receiverStream[String](MySource("hadoop201", 9999))
val words: DStream[String] = lines.flatMap(_.split("""\s+"""))
val wordAndOne: DStream[(String, Int)] = words.map((_, 1))
val count: DStream[(String, Int)] = wordAndOne.reduceByKey(_ + _)
count.print
ssc.start()
ssc.awaitTermination()
ssc.stop(false)
}
}
开启端口
nc -lk 10000
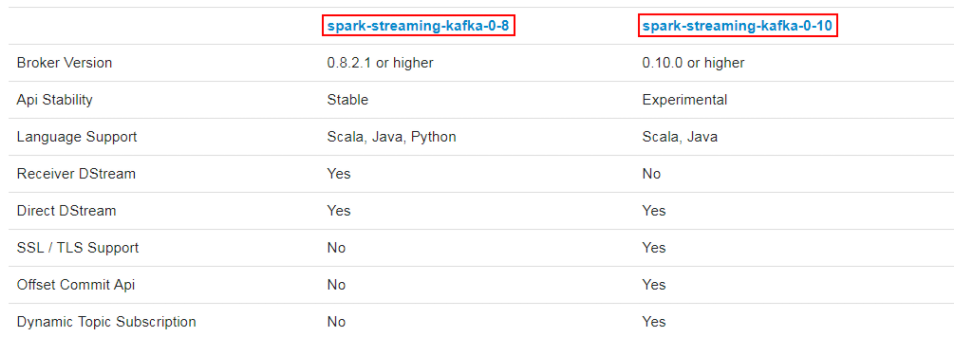
Kafka数据源
用法及说明
在工程中需要引入 Maven 依赖 spark-streaming-kafka_2.11来使用它。
包内提供的 KafkaUtils 对象可以在 StreamingContext和JavaStreamingContext中以你的 Kafka 消息创建出 DStream。
两个核心类:KafkaUtils、KafkaCluster
导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.1.1</version>
</dependency>
案例实操
高级API 1
import kafka.serializer.StringDecoder
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object HighKafka {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("HighKafka")
val ssc = new StreamingContext(conf, Seconds(3))
val brokers = "hadoop201:9092,hadoop202:9092,hadoop203:9092"
val topic = "first"
val group = "bigdata"
val deserialization = "org.apache.kafka.common.serialization.StringDeserializer"
val kafkaParams = Map(
ConsumerConfig.GROUP_ID_CONFIG -> group,
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,
)
val dStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, Set(topic))
dStream.print()
ssc.start()
ssc.awaitTermination()
}
}
高级API 2
import kafka.serializer.StringDecoder
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object HighKafka2 {
def createSSC(): StreamingContext = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("HighKafka")
val ssc = new StreamingContext(conf, Seconds(3))
ssc.checkpoint("./ck1")
val brokers = "hadoop201:9092,hadoop202:9092,hadoop203:9092"
val topic = "first"
val group = "bigdata"
val deserialization = "org.apache.kafka.common.serialization.StringDeserializer"
val kafkaParams = Map(
"zookeeper.connect" -> "hadoop201:2181,hadoop202:2181,hadoop203:2181",
ConsumerConfig.GROUP_ID_CONFIG -> group,
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> deserialization,
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> deserialization
)
val dStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, Set(topic))
dStream.print()
ssc
}
def main(args: Array[String]): Unit = {
val ssc: StreamingContext = StreamingContext.getActiveOrCreate("./ck1", () => createSSC())
ssc.start()
ssc.awaitTermination()
}
}
低级API
import kafka.common.TopicAndPartition
import kafka.message.MessageAndMetadata
import kafka.serializer.StringDecoder
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka.KafkaCluster.Err
import org.apache.spark.streaming.kafka.{HasOffsetRanges, KafkaCluster, KafkaUtils, OffsetRange}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object LowKafka {
def getOffset(kafkaCluster: KafkaCluster, group: String, topic: String): Map[TopicAndPartition, Long] = {
var topicAndPartition2Long: Map[TopicAndPartition, Long] = Map[TopicAndPartition, Long]()
val topicMetadataEither: Either[Err, Set[TopicAndPartition]] = kafkaCluster.getPartitions(Set(topic))
if (topicMetadataEither.isRight) {
val topicAndPartitions: Set[TopicAndPartition] = topicMetadataEither.right.get
val topicAndPartition2LongEither: Either[Err, Map[TopicAndPartition, Long]] =
kafkaCluster.getConsumerOffsets(group, topicAndPartitions)
if (topicAndPartition2LongEither.isLeft) {
topicAndPartitions.foreach {
topicAndPartition => topicAndPartition2Long = topicAndPartition2Long + (topicAndPartition -> 0)
}
} else {
val current: Map[TopicAndPartition, Long] = topicAndPartition2LongEither.right.get
topicAndPartition2Long ++= current
}
}
topicAndPartition2Long
}
def saveOffset(kafkaCluster: KafkaCluster, group: String, dStream: InputDStream[String]) = {
dStream.foreachRDD(rdd => {
var map: Map[TopicAndPartition, Long] = Map[TopicAndPartition, Long]()
val hasOffsetRangs: HasOffsetRanges = rdd.asInstanceOf[HasOffsetRanges]
val ranges: Array[OffsetRange] = hasOffsetRangs.offsetRanges
ranges.foreach(range => {
map += range.topicAndPartition() -> range.untilOffset
})
kafkaCluster.setConsumerOffsets(group,map)
})
}
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("HighKafka")
val ssc = new StreamingContext(conf, Seconds(3))
val brokers = "hadoop201:9092,hadoop202:9092,hadoop203:9092"
val topic = "first"
val group = "bigdata"
val deserialization = "org.apache.kafka.common.serialization.StringDeserializer"
val kafkaParams = Map(
"zookeeper.connect" -> "hadoop201:2181,hadoop202:2181,hadoop203:2181",
ConsumerConfig.GROUP_ID_CONFIG -> group,
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> deserialization,
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> deserialization
)
val kafkaCluster = new KafkaCluster(kafkaParams)
val fromOffset: Map[TopicAndPartition, Long] = getOffset(kafkaCluster, group, topic)
val dStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, String](
ssc,
kafkaParams,
fromOffset,
(message: MessageAndMetadata[String, String]) => message.message()
)
dStream.print()
saveOffset(kafkaCluster, group, dStream)
ssc.start()
ssc.awaitTermination()
}
}