为什么要使用kafka?kafka是什么东西?
案例场景
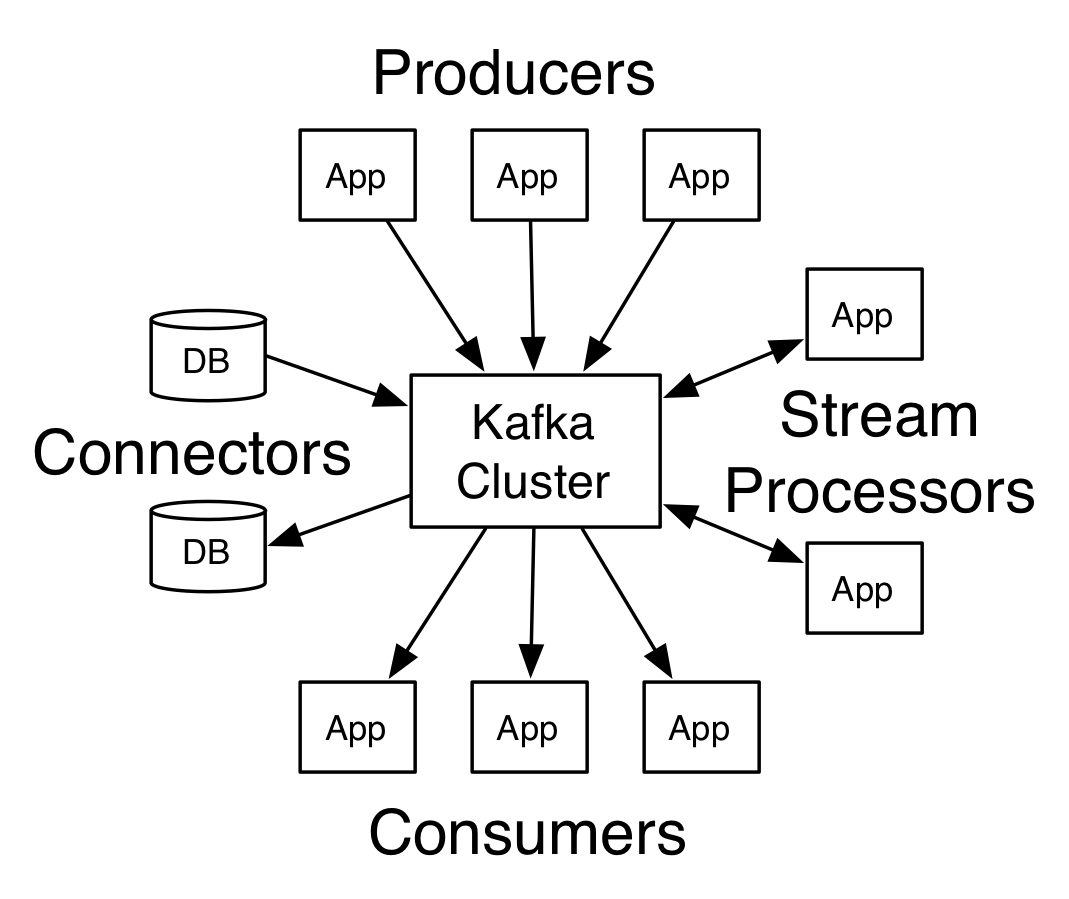
A服务向B服务发送消息,A服务传输数据很快,B服务处理数据很慢,这样B服务就会承受不住,怎么办?通过添加消息队列作为缓冲。kafka就是消息队列中的其中一种。其他的还有比如rocketMQ。
第一种方式:在B服务的内存添加队列,用于存储A服务快速发送而来的信息。
缺点:在B服务重启的时候,内存中所有消息将会丢失。
因此,我们将队列从内存中挪出来,成为一个单独的进程,这样,即使B服务重启的时候,队列里堆积的消息也不会丢失。
此时,我们称
产生消息的服务A为生产者;
接收消息的服务B为消费者;
优化消息队列?
1. 高性能:
方式:增加消费者,增加生产者,提高了消息队列的吞吐量。
缺点:争夺同一个消息队列,等待。
解决:
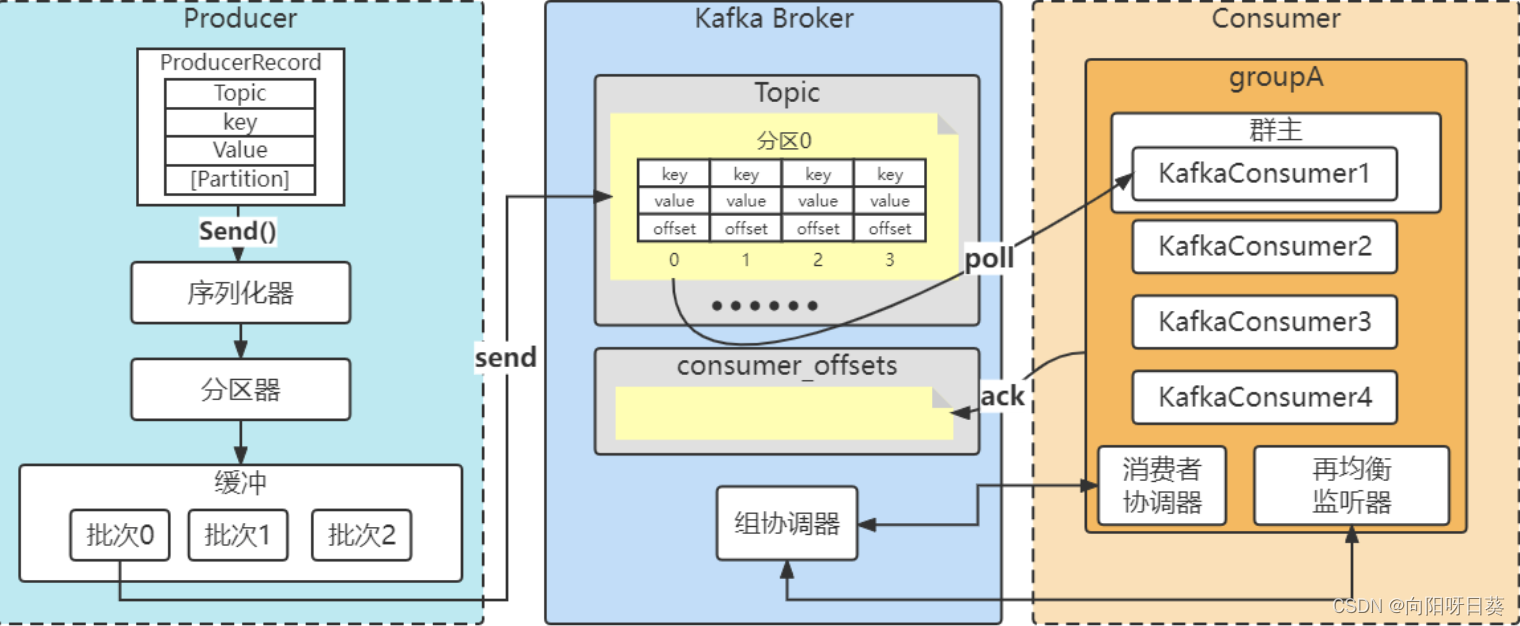
- 添加topic,不同消费者消费不同topic的消息
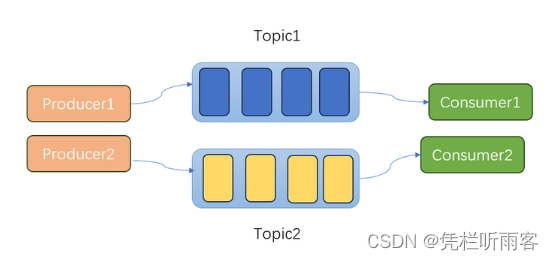
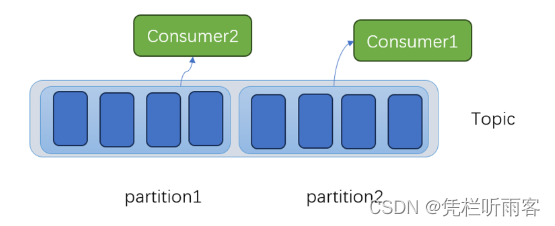
同一个topic里面消息还是很多,就分区,降低消费者争抢的可能性。
高扩展性:partition分在不同的机器上,一台机器就成为一个broker。多机器来缓解机器CPU压力
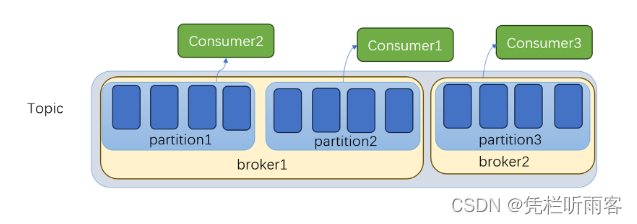
高可用:万一其中一个机器(broker)挂了?怎么办?
因此,需要做备份。如果 Leader partition 挂了,那么就会 有Flower Partition来做备份。

持久化和过期策略:如果都挂了呢,因此需要将数据同步在磁盘中,到那时磁盘又不是无限的,因此也需要进行定时的清理。每个partition内部写入磁盘都是顺序写入的,因此效率很高,但是不同的partition之间在磁盘的写入并不是顺序写入的。