1、K8s集群的组成
K8s集群由多个节点组成,其中包括主节点(Master)和工作节点(Worker)。主节点负责管理整个集群的状态和配置信息,工作节点用于运行容器应用程序。主节点包括以下组件:
- API服务器(kube-apiserver):提供K8s API接口,用于管理整个集群的状态和配置信息。
- 控制器管理器(kube-controller-manager):负责运行控制器,监控集群状态并做出相应的操作。
- 调度器(kube-scheduler):负责将容器应用程序调度到可用的工作节点上。
- etcd:K8s集群的数据存储后端,用于存储集群的状态和配置信息。
工作节点包括以下组件: - kubelet:负责管理本地节点上的容器,与主节点通信以获取应用程序的状态和配置信息。
- kube-proxy:负责在节点之间进行网络代理,以确保容器应用程序可以相互通信。
- 容器运行时(如Docker):用于在节点上运行容器应用程序。
2、部署方式
(1)minikube用在测试、开发
(2)kubeadm部署主要用在测试线、生产,kubeadm是一个K8s部署工具,提供kubeadm init和kubeadm join,用于快速部署Kubernetes集群。
官方地址:
https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm/
(3)二进制部署(主要用在生产)
3、kubeadm方式部署:
服务器要求:
建议最小硬件配置:linux、2核cpu、2G内存、30G硬盘。
可以访问外网,并且服务器之间网络互通(在一个网段)。
禁止swap分区
安装阿里云yum源(阿里云yum可以下载k8s的flannel组件)
4、环境准备
4.1 注意
kubelet版本不要过高,v1.24版本后kubernetes放弃docker了。
以下命令中的–cri-socket=unix:///var/run/cri-dockerd.sock非必须项,根据个人环境或执行中是否报相关错误使用。
4.2三台服务器进行系统更新:yum -y update systemd

4.3每个节点分别设置对应主机名
master、worker1、worker2分别设置各自主机名
hostnamectl set-hostname master
hostnamectl set-hostname worker1
hostnamectl set-hostname worker2
4.4关闭交换分区 swap。
所有 K8S 节点都需要执行
避免交换分区导致节点不稳定和性能问题,出现异常。
swapoff -a
sed -i '/swap/s/^/#/' /etc/fstab
查看交换分区状态:
swapon --show



4.5、关闭selinux
1、因安全机制较复杂,可能会与k8s本身的流量机制冲突,因为k8s本身会在netfilter里设置流量规则,也即:iptables规则
2、这是允许容器访问主机文件系统所必需的,而这些操作是为了例如 Pod 网络工作正常。
所有 K8S 节点都需要执行:
setenforce 0
sed -i --follow-symlinks 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/sysconfig/selinux


4.6、关闭防火墙
所有 K8S 节点都需要执行:
systemctl stop firewalld && systemctl disable firewalld
systemctl status firewalld

4.7时间同步
所有 K8S 节点都需要执行:
使用date命令查看三个节点时间是否一致,kubernetes要求集群中的节点时间必须精确一直。
安装时钟同步
1.安装:
yum -y install ntpdate
2#手动同步阿里云时间服务器时间
ntpdate ntp.aliyun.com 或 ntpdate ntp.ubuntu.com
4.8、绑定 hosts
所有 K8S 节点都需要执行:
cat << EOF >> /etc/hosts
192.168.xx.241 master
192.168.xx.235 worker1
192.168.xx.238 worker2
EOF

EOF保存退出或Ctrl+d
或vi /etc/hosts命令编辑
4.9配置 K8S 的 YUM 源
所有 K8S 节点都需要执行:
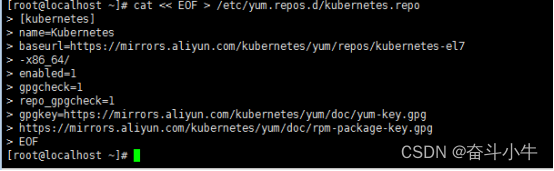
cat << EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
gpgcheck和repo_gpgcheck都被设置为1,意味着系统会对从该仓库下载的所有包和仓库文件进行GPG签名验证,它是一种用于验证软件包完整性和来源的加密工具。
若不需认证设置为0,建议默认为0。
安装 yum-config-manager
yum -y install yum-utils
安装 Docker 安装源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
4.10、安装所需组件
安装 Kubelet、Kubeadm 和 Kubectl、docker
所有 K8S 节点都需要执行:
yum install -y kubelet-1.22.4 kubectl-1.22.4 kubeadm-1.22.4 docker-ce-20.10.17-3.el7
启动:
systemctl enable kubelet
systemctl start kubelet
systemctl enable docker
systemctl start docker
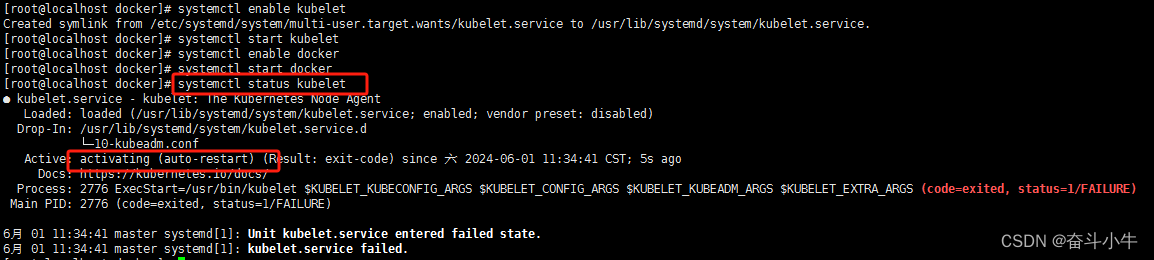
kubelet 并未启动成功,需在k8s初始化后才可以。
查看版本
kubectl version
4.11修改 docker 配置
所有节点执行:
其中,exec-opts 用于设置 Docker 的 cgroup 驱动类型,需要将其修改为 systemd。因
为 K8S 默认就是使用的 systemd,将 Docker 和 K8S 的驱动类型统一,否则后续会有报错。
需要注意的是:K8S 内的节点上 Docker 环境都需要统一。
所有 K8S 节点都需要执行:
cd /etc/docker
cat <<EOF > /etc/docker/daemon.json
{
"exec-opts":["native.cgroupdriver=systemd"],
"registry-mirrors":["http://hub-mirror.c.163.com","https://mirrors.tuna.tsinghua.edu.cn/","https://g6yrjrwf.mirror.aliyuncs.com/","https://docker.mirrors.ustc.edu.cn"]
}
EOF

之后docker重启:
systemctl daemon-reload
systemctl restart docker
4.12内核优化
所有 K8S 节点都需要执行:此次搭建未执行内核优化
在 Docker 的使用过程中有时会看到下面这个警告信息。
WARNING: bridge-nf-call-iptables is disabled
WARNING: bridge-nf-call-ip6tables is disabled
这种警告信息可通过配置内核参数的方式来消除,具体配置如下。
[root@localhost ~]# cat << EOF >> /etc/sysctl.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
[root@localhost ~]# sysctl -p
4.13集群初始化(镜像)
所有 K8S 节点都需要执行:
为了提高初始化执行速度,也可以先通过 kubeadm config images pull 把镜像下载后再执行上述集群初始化命令。下载镜像命令(所有节点都执行):
查看kubelet --version:版本

kubeadm config images pull \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.22.4
//视环境取舍这段命令
--cri-socket=unix:///var/run/cri-dockerd.sock
worker上报错:需要去掉–cri-socket=unix:///var/run/cri-dockerd.sock

报错1:

Docker Engine没有实现CRI,而这是容器运行时在 Kubernetes 中工作所需要的。 为此,必须安装一个额外的服务 cri-dockerd。 cri-dockerd 是一个基于传统的内置 Docker 引擎支持的项目, 它在 1.24 版本从 kubelet 中移除。
cri-dockerd下载:
wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.14/cri-dockerd-0.3.14-3.el7.x86_64.rpm
安装:
rpm -ivh cri-dockerd-0.3.14-3.el7.x86_64.rpm


启动:
systemctl daemon-reload && systemctl enable cri-docker.socket
systemctl start cri-docker.socket cri-docker
报错2:
执行初始化后报有多个cri,选择unix:///var/run/cri-dockerd.sock

)
kubeadm config images pull \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.22.4 --cri-socket=unix:///var/run/cri-dockerd.sock
报错3:

检查kubeadm命令的正确用法,确保你没有误输入或使用了错误的子命令。重新修改下命令,去掉空格等。
报错4:

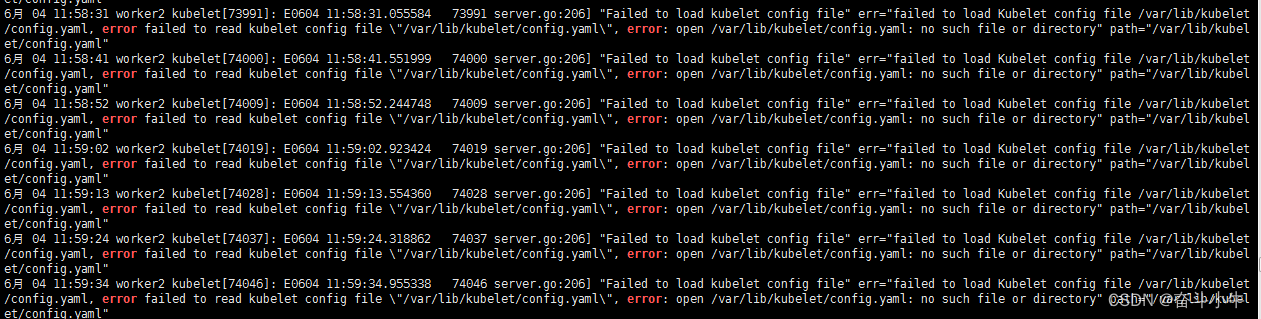
查询日志报错点:
journalctl -xeu kubelet | grep error
修改containerd的配置文件,下文有提到解决办法。
4.14集群初始化(控制台)
只在 master 节点执行命令:
初始化集群控制台 Control plane,kubernetes-version 和下载的镜像版本保持一致。
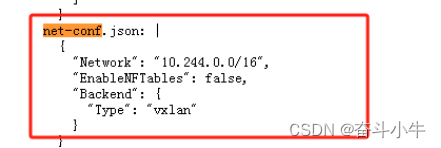
pod-network-cidr:10.244.0.0/16版本无需修改,直接使用即可,节点之间通信网段。
kubeadm init --kubernetes-version=v1.22.4 --image-repository=registry.aliyuncs.com/google_containers --pod-network-cidr=10.244.0.0/16
注意:使用带有advertise-address(master的ip)的初始化失败了,可能上一个步骤下载镜像的时候未指向地址,但查阅资料中全部带有此项,因初始化过程中报错太多,大概率与apiserver-advertise-address无关,待考证。
kubeadm init --kubernetes-version=v1.22.4 --apiserver-advertise-address=192.168.xx.241 --pod-network-cidr=10.244.0.0/16 --image-repository=registry.aliyuncs.com/google_containers
失败时可以用 kubeadm reset 重置。
kubeadm reset --cri-socket=unix:///var/run/cri-dockerd.sock
rm -rf $HOME/.kube
超时报错:
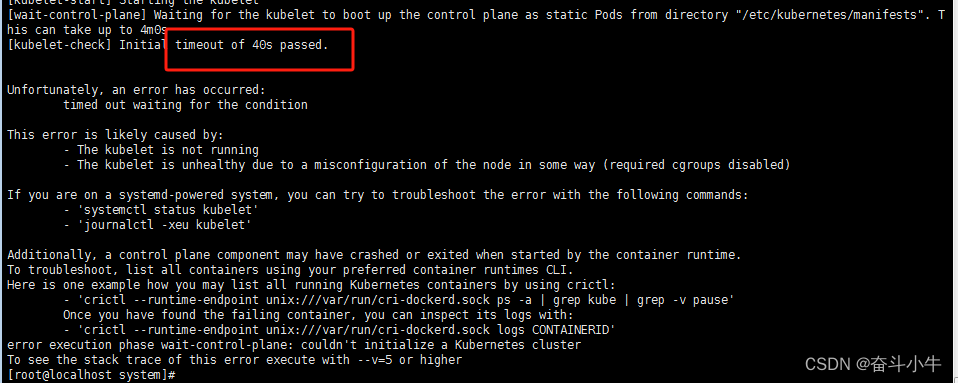
查询日志报错点:journalctl -xeu kubelet | grep error
未加国内镜像时报错:
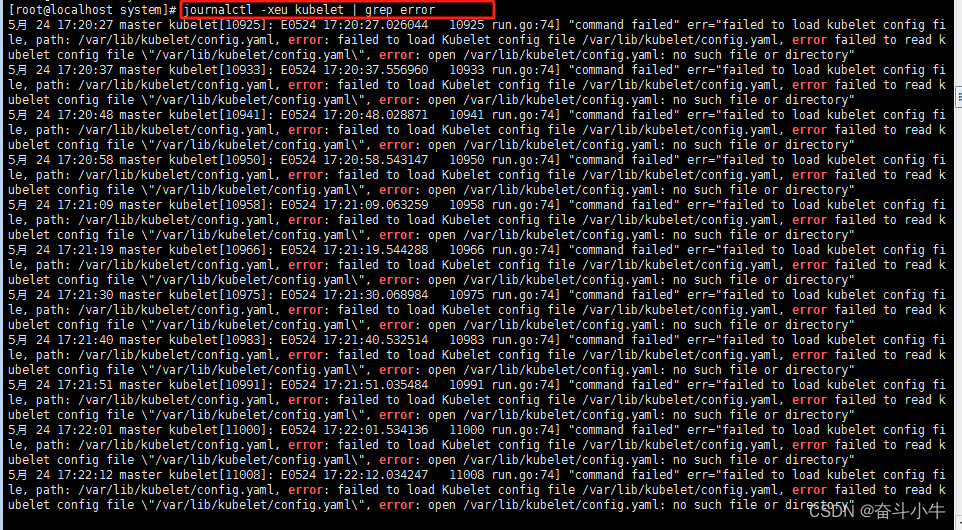
#生成containerd的默认配置文件
containerd config default > /etc/containerd/config.toml
#查看 sandbox 的默认镜像仓库在文件中的第几行
cat /etc/containerd/config.toml | grep -n "sandbox_image"

#使用 vim 编辑器 定位到 sandbox_image,将仓库地址修改成
vi /etc/containerd/config.toml
修改:
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.9"

重启 containerd 服务
systemctl daemon-reload
systemctl restart containerd.service
systemctl status containerd.service
初始化执行成功后:
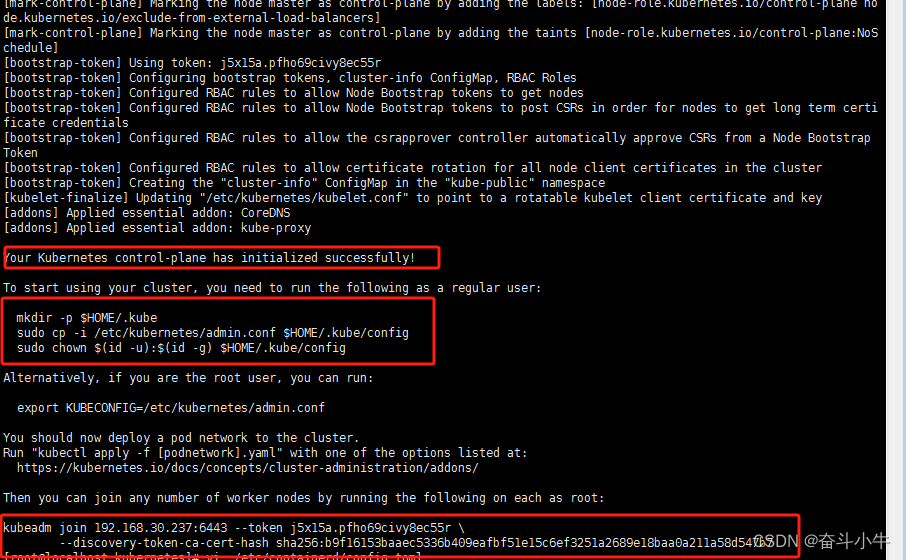
查看下载后的完整镜像:
master:
docker image ls

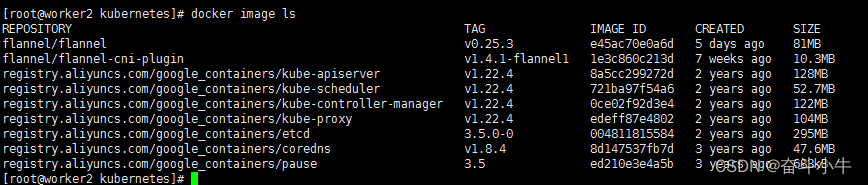
其中的 coredns 镜像,需要保证在 worker1 和 worker2 上同样下载好。
worker2:
4.15集群初始化(token令牌)
初始化成功后会生成token令牌,保存记录下来:
token令牌:
kubeadm join 192.168.30.241:6443 --token 30e7vh.qgct7j66o2f8wihy \
--discovery-token-ca-cert-hash sha256:cbdba315b70cd09edd2fda0a1ddd5e429ef94afad16ec0fc1b8c7b2b5a2a5242
默认token有效期为24小时,节点加入master集群使用,当过期之后,该token就不可用了。这时就需要重新创建token,可以直接使用命令快捷生成:
kubeadm token create --print-join-command
执行初始化后提示的文件操作信息:
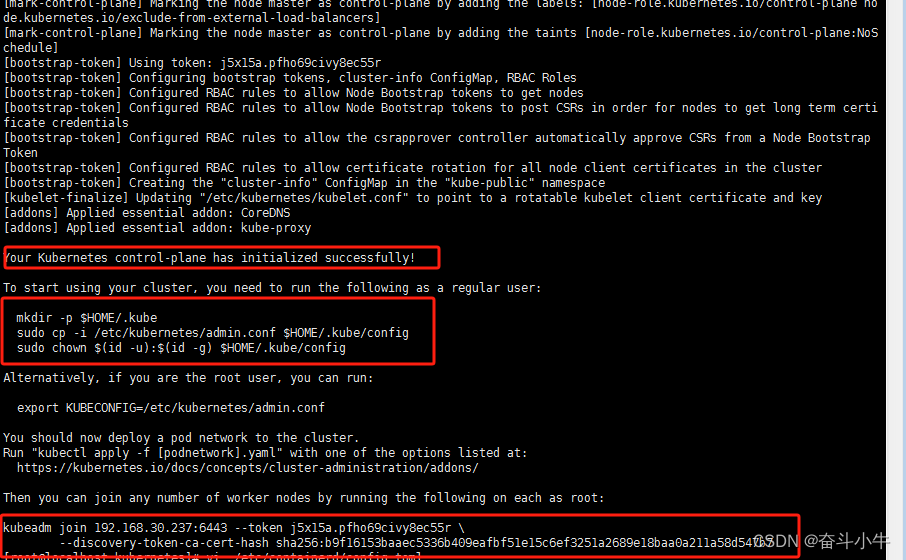
#复制授权文件,以便 kubectl 可以有权限访问集群
#拷贝 config 文件,在 master 节点执行 kubectl 命令
在master节点执行:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
在worker1和worker2执行:
kubeadm join 192.168.30.241:6443 --token 30e7vh.qgct7j66o2f8wihy \
--discovery-token-ca-cert-hash sha256:cbdba315b70cd09edd2fda0a1ddd5e429ef94afad16ec0fc1b8c7b2b5a2a5242 --cri-socket=unix:///var/run/cri-dockerd.sock
报错:

此处原因是worker与maste节点时间不一致导致的,更新时间。
以下报错因token重新生成问题加入集群,节点执行初始化设置:
kubeadm reset --cri-socket=unix:///var/run/cri-dockerd.sock
,每次初始化失败后都要执行重置。
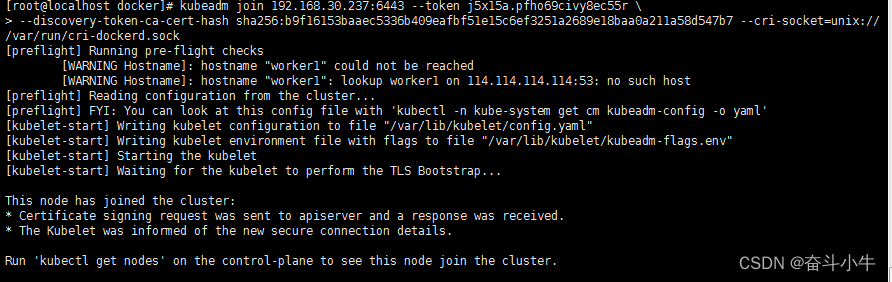
如果你其他节点需要调用访问集群,执行 kubectl 等命令,需要从主节点复制这个文件$HOME/.kube/config过去其他工作节点 ,否则报一下错误:

在工作节点先建好目录执行:
mkdir -p $HOME/.kube
在 master 节点执行:
scp $HOME/.kube/config root@worker1:$HOME/.kube/config
scp $HOME/.kube/config root@worker2:$HOME/.kube/config
scp命令需要节点输入服务器的密码。
kubectl get nodes

此处出现这个问题的原因是kubectl命令需要使用kubernetes-admin的身份来运行,在“kubeadm int”启动集群的步骤中就生成了/etc/kubernetes/admin.conf,将此文件复制到节点同目录下:
scp /etc/kubernetes/admin.conf root@worker2:/etc/kubernetes/admin.conf
因此,解决方法如下,将master节点中的/etc/kubernetes/admin.conf文件拷贝到工作节点相同目录下:
#然后在该工作节点上配置环境变量:
设置kubeconfig文件
export KUBECONFIG=/etc/kubernetes/admin.conf
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
接下来,工作节点执行kubectl就正常了
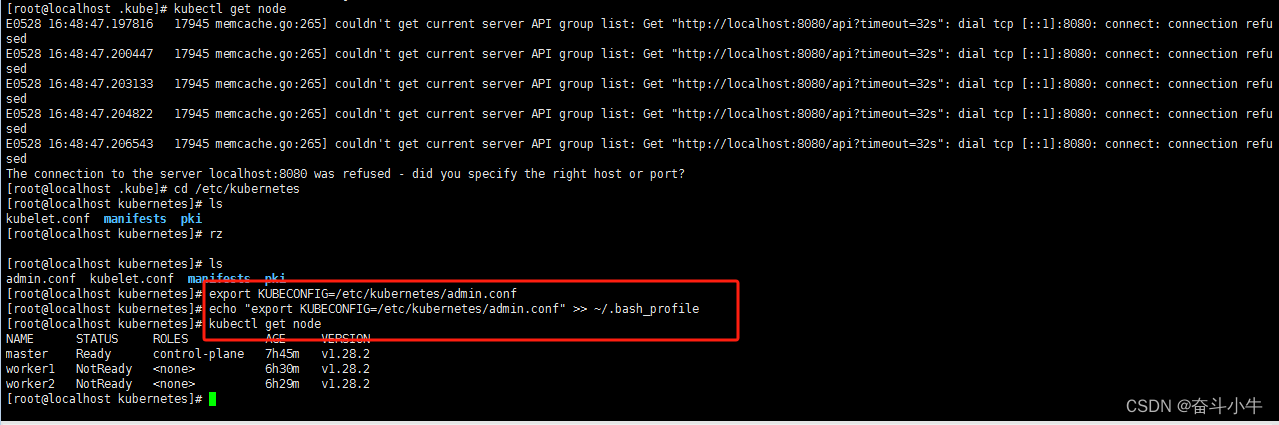
4.16安装网络插件
先查看各节点状态执行:
kubectl get node
查看 node 是 NotReady 状态,需要安装网络插件,促使节点之间正常通信。
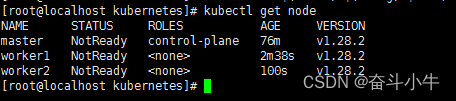
kubectl get nodes
kubectl get pod --all-namespaces
//查看pod是否是running状态
master节点执行:
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
也可先下载到本地:
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
可查看kube-flannel.yml文件中network是否与初始化时设置的值一致。
再执行
kubectl apply -f kube-flannel.yml
确保能够访问到quay.io这个registry(需要用阿里云yum源才可访问下载)

稍等片刻后执行成功后查看:
kubectl get pod --all-namespaces //查看pod是否是running状态
或 kubectl get nodes
成功后截图:


若搭建过程中出现的问题可参照以下思路解决。
4.17重置
记录重置命令:
kubeadm reset --cri-socket=unix:///var/run/cri-dockerd.sock
rm -rf $HOME/.kube
其他过程问题记录
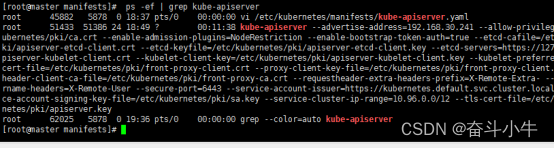
1、确认 kube-apiserver 进程是否在运行中。
ps -ef | grep kube-apiserver
使用的一些命令:
kubelet重启:
systemctl restart kubelet
kubectl get nodes 查看节点信息
节点上执行:
journalctl -f -u kubelet.service
查询日志报错点:
journalctl -xeu kubelet | grep error
查看运行状态及是否有报错:
systemctl status docker -l
systemctl status kubelet -l
2、查看各版本:
kubelet --version
kubectl version
kubeadm version
3、卸载kubernetes
查看安装组件:
yum list installed | grep kube*

卸载:
kubeadm reset -f --cri-socket=unix:///var/run/cri-dockerd.sock
yum -y remove kubelet kubeadm kubectl
rm -rvf $HOME/.kube
rm -rvf ~/.kube/
rm -rvf /etc/kubernetes/
rm -rvf /etc/systemd/system/kubelet.service.d
rm -rvf /etc/systemd/system/kubelet.service
rm -rvf /usr/bin/kube*
rm -rvf /etc/cni
rm -rvf /opt/cni
rm -rvf /var/lib/etcd
rm -rvf /var/etcd
4、卸载docker
1、删除docker所在目录
rm -rf /etc/docker
rm -rf /run/docker
rm -rf /var/lib/dockershim
rm -rf /var/lib/docker
2、杀掉docker进程:
ps -ef|grep docker
kill -9 pid
3、查看相关包:
yum list installed | grep docker
4、卸载相关包
yum remove containerd.io.x86_64
yum remove docker-ce.x86_64
yum remove docker-ce-cli.x86_64
yum remove docker-ce-rootless-extras.x86_64
yum remove docker-compose-plugin.x86_64
yum remove docker-scan-plugin.x86_64
4、docker --version 查看结果
5、卸载flannel
看下面的记录11项卸载。
kubectl delete -f
https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
6、网络插件状态:
检查网络插件的状态
docker network ls
检查网络插件的配置
ls -l /opt/cni/bin
ls -l /etc/cni/net.d
重启网络插件
systemctl restart docker
再次检查网络插件的状态
docker network ls
7、卸载网络插件时提示forbidden无权限
这可能是由于config没有更新导致的,/root/.kube/config是从/etc/kubernetes/admin.conf复制而来。复制来之后,是需要执行更新kubeconfig命令的。
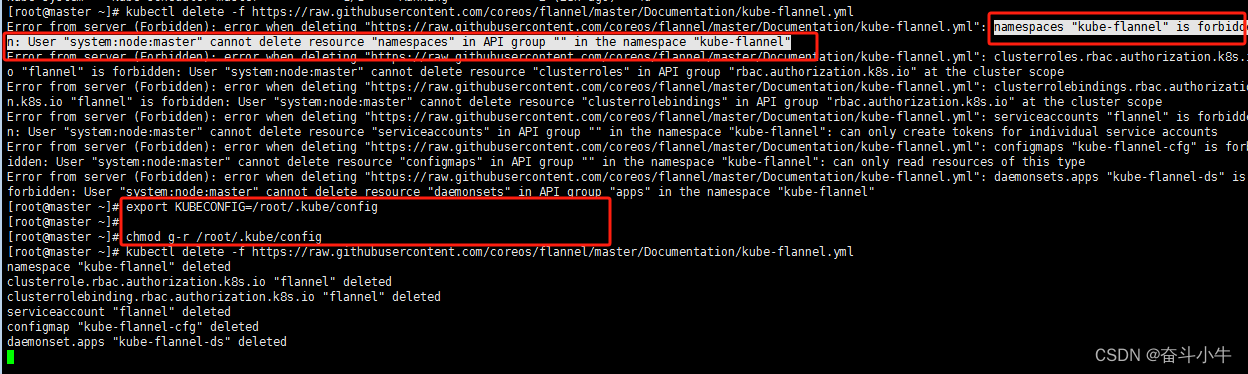
更新 kubeconfig 命令:
export KUBECONFIG=/root/.kube/config
chmod g-r /root/.kube/config
再次执行:
kubectl delete -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
#删除kube-flannel的DaemonSet
kubectl delete -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
删除kube-flannel的ClusterRole和ClusterRoleBinding
kubectl delete clusterrole flannel
kubectl delete clusterrolebinding flannel
删除kube-flannel创建的配置文件和网络接口
这一步可能需要根据你的系统和flannel版本具体分析
以下命令是一个大概的指导,可能需要根据实际情况调整
在每个节点上执行以下命令
删除flannel创建的网络接口(interface)
ip link delete flannel.1
删除flannel创建的路由
ip route del 10.2.0.0/16
清理flannel使用的etcd目录(请注意,这将删除所有存储在该目录下的数据,谨慎操作)
etcdctl rm --dir --recursive /coreos.com/network
8、证书过期
集群是由kubeadm创建。但是它创建的apiserver、controller-manager等证书默认只有一年的有效期,同时kubelet 证书也只有一年有效期,一年之后kubernetes将停止服务。
查看证书过期时间:
kubeadm certs check-expiration
更新自签日期:
kubeadm certs renew all
重新查看过期时间:
kubeadm certs check-expiration
复制配置文件:
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
#重启kubelet,docker(master与node都要重启)
systemctl restart docker systemctl restart kubelet
9、时间不一致
master与worker时间差8小时,需要同步下时间。
ntpdate ntp.ubuntu.com

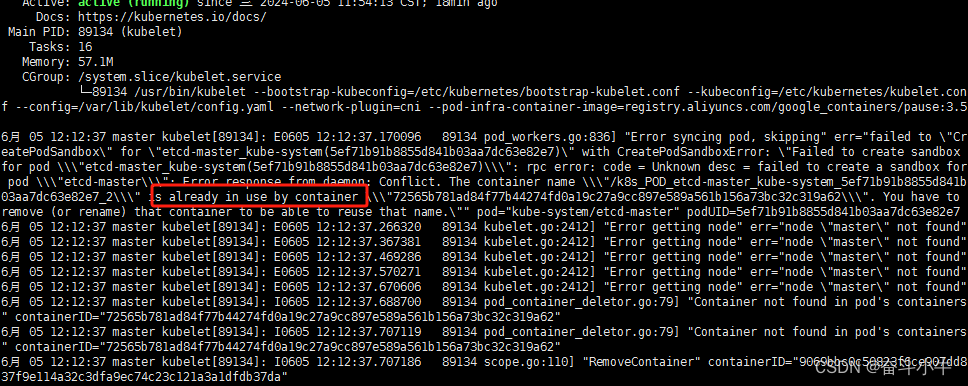
10、is already in use by container
注意,线上使用etcd一定要做高可用和定期备份,否则就悲催了。
使用docker rm 删除镜像未成功,最后还是进行了 重置。kubeadm reset
11、卸载flannel网络:
kubectl delete -f kube-flannel.yml
操作步骤:
| 1 | 停止Kubelet服务 |
| 2 | 删除Flannel插件 |
| 3 | 删除Flannel配置文件 |
| 4 | 重启Kubelet服务 |
1、停止Kubelet服务:
sudo systemctl stop kubelet
这条命令用于停止Kubelet服务,确保在卸载Flannel插件的过程中不会出现冲突。
步骤 2:删除Flannel插件
kubectl delete -f
https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
该命令用于从Kubernetes集群中删除Flannel插件。它会使用Flannel插件的YAML文件来执行删除操作。
步骤 3:删除Flannel配置文件
sudo rm -rf /etc/cni/net.d/10-flannel.conf
这条命令用于删除Flannel插件的配置文件,确保在之后重新安装Flannel插件时不会出现冲突。
步骤 4:重启Kubelet服务
sudo systemctl start kubelet
最后一步是重新启动Kubelet服务,确保Kubernetes集群正常运行。
经过以上步骤操作,你就成功地卸载了Kubernetes中的Flannel插件。
除了以上步骤外,你还可以通过以下命令验证Flannel插件是否已经被成功卸载:
kubectl get pods --all-namespaces
如果你看不到与Flannel相关的Pod,则表示Flannel插件已经成功卸载。
12、network: loadFlannelSubnetEnv failed: open /run/flannel/subnet.env: no such file or directory
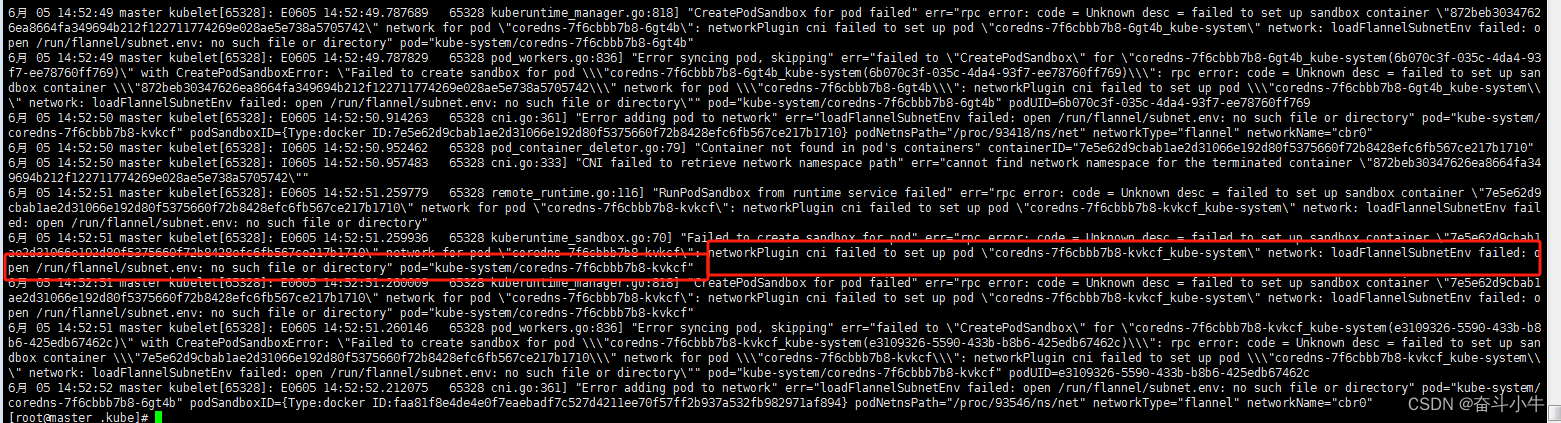
master节点:
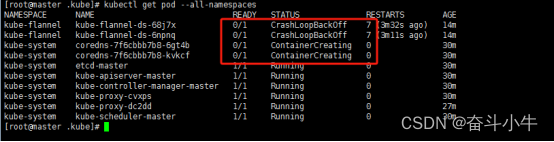
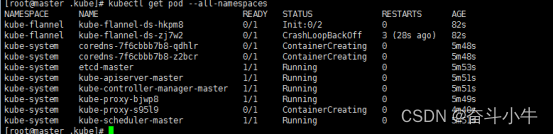
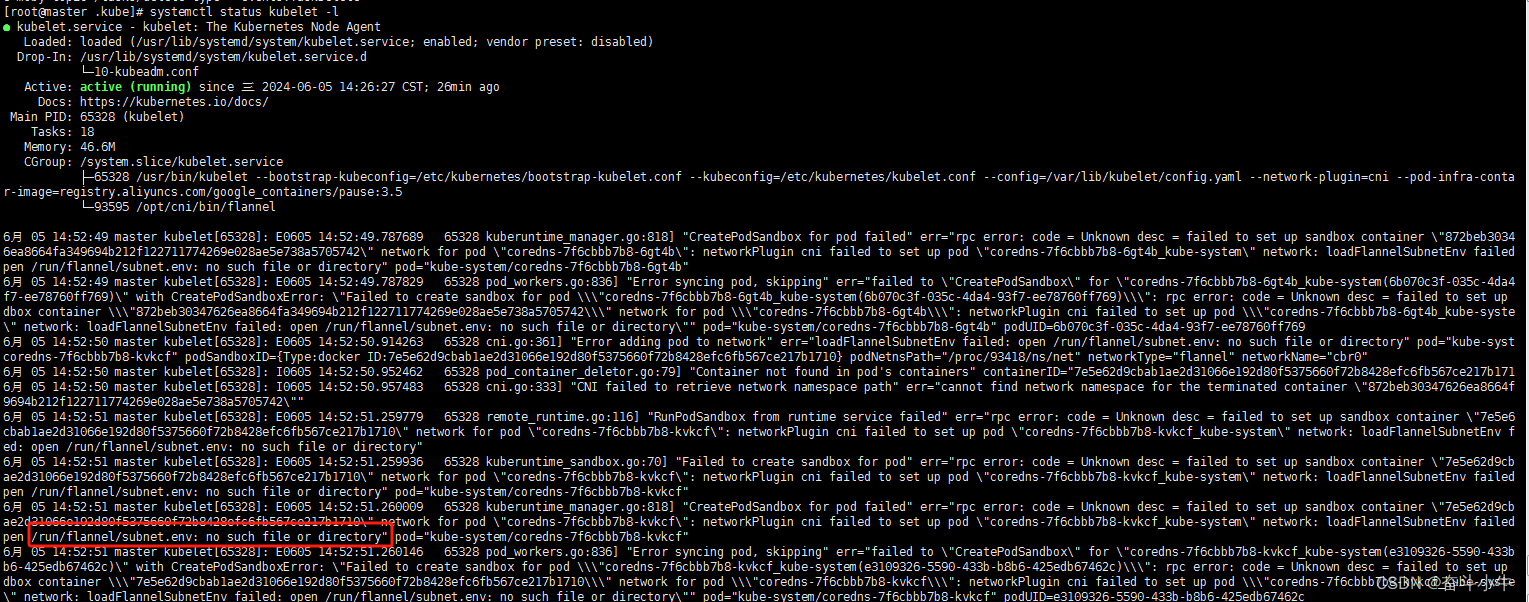
大部分都是直接创建提示不存在的文件/run/flannel/subnet.env在每个节点上(master跟node)创建上面文件后,确实能够解决问题。注意上面指定的网段不要跟自己真实的内网网段产生冲突,否则会造成机器之间无法ping通的问题。
但是这样解决会出现重启机器后,又无法部署到pod的问题。因为重启后这个文件就丢失了。并未彻底解决问题。
实际上,这个问题是因为没有给集群的pod指定内网网段的缘故。最彻底的解决办法是将这个集群所有节点重新kubeadm reset,重新初始化,并在初始化时指定内网网段:
非master节点:
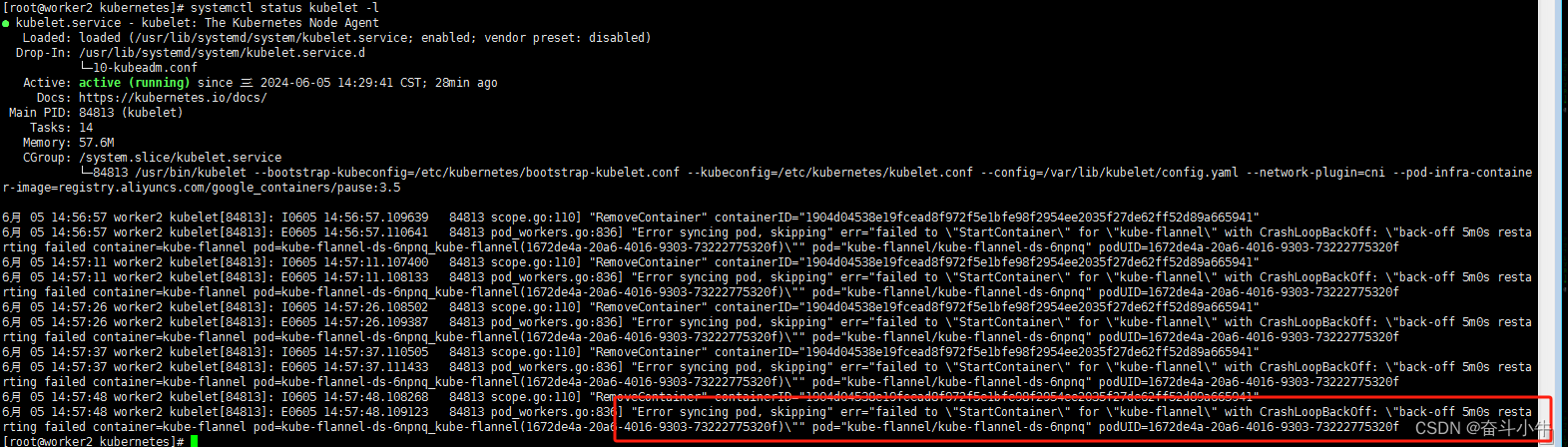
13、解决 node 节点 NotReady 状态
解决 node 节点 NotReady 状态
1、从 master 节点拷贝 ca.crt 到 node 节点对应的目录
scp /etc/kubernetes/pki/ca.crt local-168-182-111:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/ca.crt local-168-182-112:/etc/kubernetes/pki/
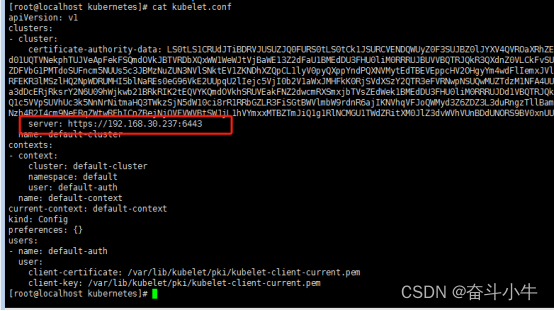
2、修改 node 节点的 kubelet.conf
把server: https://local-168-182-110:6443修改为现在 master 节点的地址server: https://cluster-endpoint:6443
sed -i 's/local-168-182-110/cluster-endpoint/g' /etc/kubernetes/kubelet.conf
确认文件:
14、kubelet版本1.28.2过高:
“Error getting node” err="node “master” not found"后面日志一直提示这个,需要根据个人情况判断,此处是
问题原因:kubelet版本过高,v1.24版本后kubernetes放弃docker了。
https://cloud.it168.com/a2022/0426/6661/000006661320.shtml
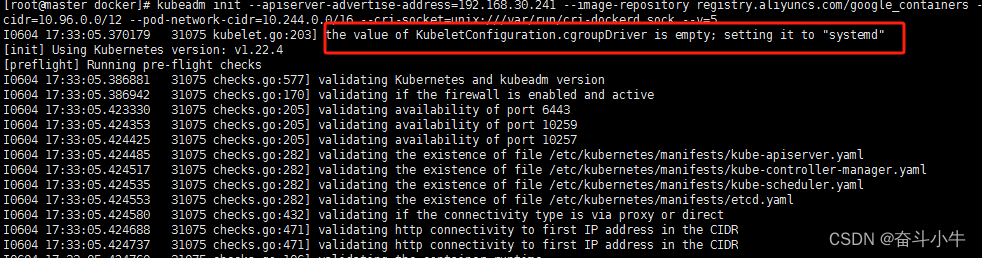
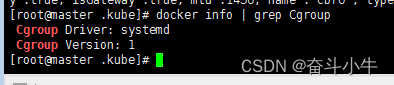
15、docker info | grep Cgroup
修改kubelet的配置文件(通常是/var/lib/kubelet/config.yaml),设置cgroupDriver字段
cgroupDriver: “systemd”
重启kubelet服务以应用更改:
sudo systemctl daemon-reload
sudo systemctl restart kubelet
16、后期加入节点:Unable to update cni config" err="no networks found in /etc/cni/net.d
工作节点报错:
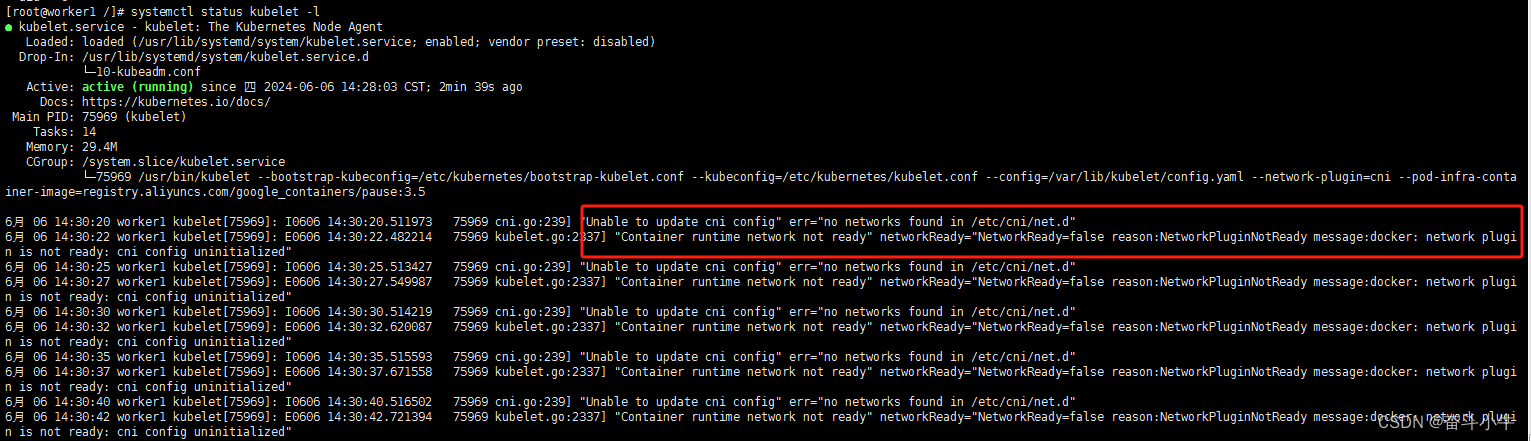
因为此节点是在flannel网络插件安装之后才加入的集群的。将master中网络镜像复制到工作节点。
1、master节点:查看主控节点的网络组建是什么:10-flannel.conflist
cd /etc/cni/net.d

2、在镜像列表中查看,并save成tar包:
docker images|grep flannel

[root@master net.d]# docker save /flannel/flannel:v0.25.3 -o flannel.tar
[root@master net.d]# docker save /flannel/flannel-cni-plugin:v1.4.1-flannel1 -o flannel-cni-plugin.tar

3、将tar包依次传给报错的worker1节点上:
scp flannel-cni-plugin.tar worker1:
scp flannel.tar worker1:
在根目录下:

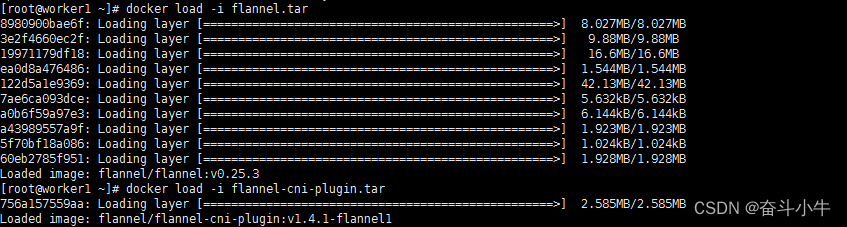
4、导入:
docker load -i flannel.tar
docker load -i flannel-cni-plugin.tar
5、重新执行 kubeadm join 命令即可。
17、查看有哪些服务:
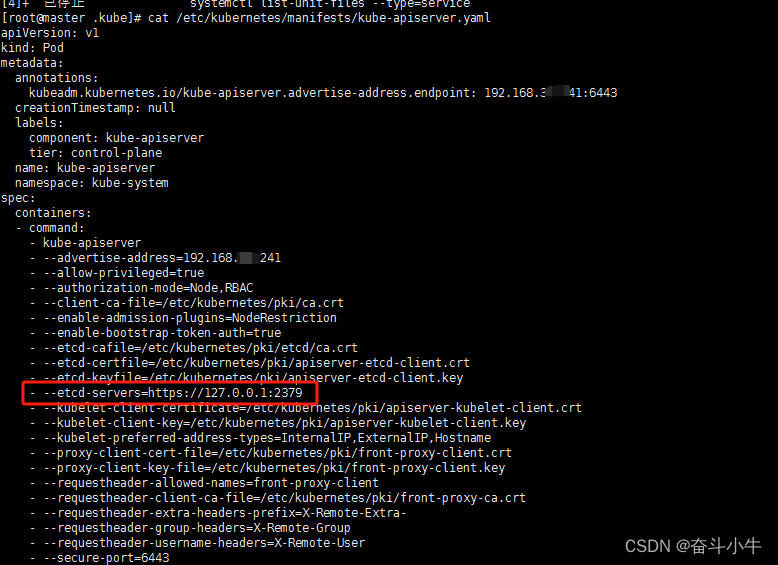
kube-apiserver 是 Kubernetes 控制平面的枢纽,负责处理所有的 API 调用,包括集群管理、应用部署和维护、用户交互等,并且它是集群中的其他组件与集群数据交互的中介。由于其至关重要的作用,kube-apiserver 必须保持高可用性,通常在生产环境中会以多副本的方式部署。
systemctl list-unit-files --type=service
kube-apiserver --insecure-port=8080 --service-cluster-ip-range=10.0.0.0/24 --advertise-address=192.168.1.100 --etcd-servers=http://127.0.0.1:2379
cat /etc/kubernetes/manifests/kube-apiserver.yaml