欢迎来到博主的专栏——c++编程
博主ID:代码小豪
前言
受限于博主当前的技术水平,暂时还不能模拟实现出STL当中用到的allocator,所以在这片博客当中,博主更想表达的是list的数据结构,以及list的各个操作涉及的算法,还有list的迭代器是怎样的工作原理。
博主参考的是SGI版本的STL源码,如果你对源码非常感兴趣,可以私聊博主获取源码。
在《vectoe的模拟实现》这一博客当中,我是按照c++在线文档的接口顺序来模拟实现的,但是list的结构要比vector复杂,所以博主选择跳跃式的方法来模拟实现list。
list的数据结构
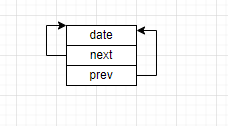
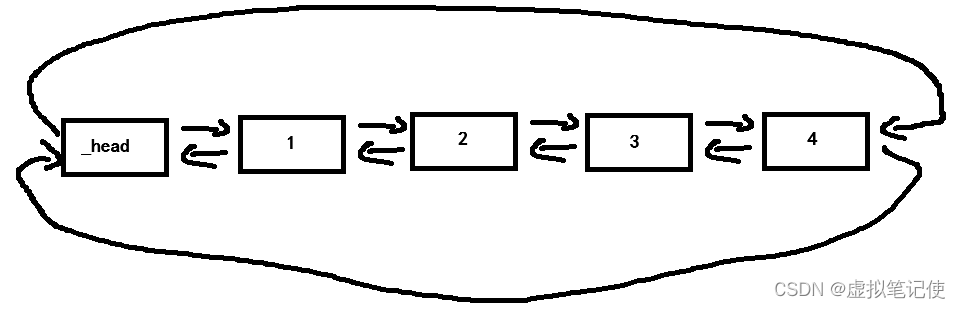
list是一个带头双向循环链表的数据结构,其结点具有以下结构
- 存储数据的val
- 指向上一个节点的指针prev
- 指向下一个节点的指针next

而链表的结构则需要将表头节点和尾结点链接起来,头结点不存储有效数据,只记录前驱节点和后继节点。

那么我们需要定义两个类,一个类是节点,另外一个类是管理头结点的链表。链表中的成员只需要一个,那就是指向头结点的指针。
template<class T>
struct ListNode//结点
{
T _data;//数据
ListNode* _next;//指向下一个节点的指针
ListNode* _prev;//指向上一个节点的指针
};
template<class T>
class list
{
typedef ListNode<T> Node;
Node* _head;//指向链表头结点
};
list的默认构造
我们先来为链表和节点设计一个默认构造吧、还有其他的构造等我们实现了list的插入和删除再来实现。
先来想想怎么默认构造链表,根据c++标准,list的默认构造是实例化出一个空表,由于list是一个带头双向循环链表,因此即使list是一个空表,我们也需要生成这个链表的头结点(带头链表的头结点是不计入有效节点的)。
由于头结点不设置有效数据,那么在构造头结点的时候,我们只需要调用节点的默认构造就行。
list()
{
_head = new Node;//_head指向头结点,头结点是默认构造的Node
_head->next=_head;
_head->prev=_head;
}
那么问题就来了,list的默认构造会调用Node的默认构造,可是Node的默认构造还没有生成呢!
节点的默认构造则是这样,我们允许节点传入一个T类型的参数val,这个val是传递给data的值。但是有参数的构造不属于默认构造,那么我们就为这个val设置一个缺省值吧,由于ListNode是一个模板类,那么data的值可能是各种各样的类,我们应该为这个val设置什么缺省值呢?
用匿名对象T()作为val的缺省值,如果T实例化成了内置类型,那么val的缺省值就是0,如果T实例化成了类类型,比如string。那么val的缺省值就会调用T类型的默认构造。
ListNode(T val = T())
{
date = val;
next = nullptr;
prev = nullptr;
}
尾插与尾删
实际上push_back和pop_back应该放在插入和删除那一部分的,但如果你查看一下c++手册,你会发现insert和erase都需要用到迭代器,但是如果我们要实现迭代器,又需要插入和删除数据才能验证这些迭代器是无误的,那么这就进入了死循环。
好在push_back和push_pop不需要迭代器,那么我们先来实现这两个操作吧。
void push_back(const T& val);
void push_back();
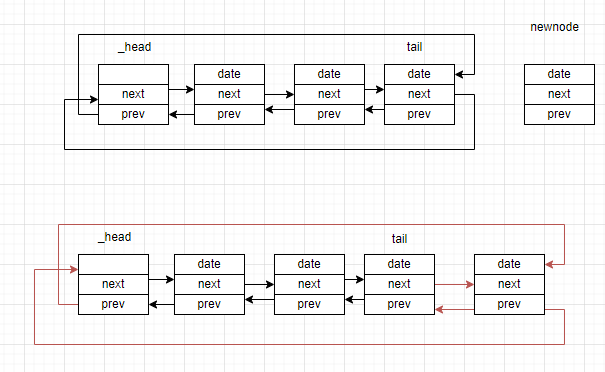
我们先找到当前链表的尾结点,双向链表的尾结点是非常好找的,_head->prev就是尾结点。尾插的操作如下:
(1)new一个新节点newnode
(2)newnode的next指向头结点
(3)newnode的prev指向尾结点
(4)让尾结点的next指向newnode
(5)头结点的prev指向newnode
void push_back(const T& val)
{
Node* tail = _head->prev;//找到尾结点
Node* newnode = new Node(val);
newnode->next = _head;
newnode->prev = tail;
tail->next = newnode;
_head->prev = newnode;
}
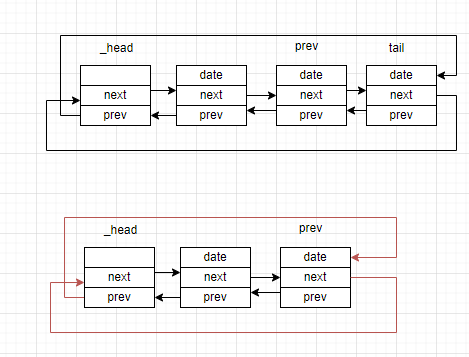
尾删法的操作如下:
(1)找到尾结点tail的前驱节点Prev。
(2)让Prev的next指向_head
(3)让_head的prev指向Prev
(4)delete掉tail节点
不过有一点要注意,那就是避免对空表进行尾删操作,这是会导致程序报错的,因此我们可以设置一个异常,也可以直接断言。这里博主为了方便就选择断言了
void push_back()
{
Node* tail = _head->prev;//找到tail节点
assert(tail != _head);//当尾结点就是头结点时,list为空表
Node* prev = tail -> prev;//找到prev节点
prev->next = _head;
_head->prev = prev;
delete tail;
}
这个断言其实不太好,等我们实现了list的迭代器后,我们可以让迭代器完成这项工作,即
assert(this->begin()!=this->!end());
iterator
好吧,最终还是来到了最让我头疼的iterator部分,我第一次尝试实现迭代器的时候是非常痛苦的。不过还是从SGI版本的list的迭代器中学到了精妙的编程方式,也深深的感叹c++封装特性的奇妙之处。
在string和vector的模拟实现当中,博主都是粗暴的将容器中的指针当成迭代器来使用,即
typedef T* iterator;
这是因为string和vector的元素的存储方式都是连续存储。这就导致指针的行为逻辑(++,–,判断)都和迭代器一致。因此我们可以直接把指针当做迭代器。
但是list可不是顺序存储的数据结构,如果我们还是让迭代器具有指针的行为逻辑,那么迭代的结果肯定是飞到姥姥家去了。原因也很简单,迭代器需要执行++操作的吧,而指针++是指向顺序存储的下一个元素空间,但是list不是顺序存储,那么迭代器指向的空间就是未使用的空间,那不成野指针了吗。
那么我们该怎么实现list的迭代器呢?SGI板的STL是这么解决的,list的迭代器的主要问题是由于指针的行为不符合list的迭代要求,那么我们将指针封装起来,成为一个类,那么我们不就可以定义operator++,operator–,使得这个指针符合list迭代的需求。简直是一个奇妙的想法。
博主这里直接将这个类模拟实现出来,源码之下没有秘密,千言万语不如让大家亲身感受。
template<class T,class ref,class ptr>
struct listiterator
{
typedef ListNode<T> Node;
typedef listiterator self;
listiterator(Node* listnode=nullptr)
{
linkptr = listnode;
}
self operator++()//前置++
{
linkptr = linkptr->next;
return linkptr;
}
self operator++(int)//后置++
{
listiterator tmp = linkptr;
linkptr = linkptr->next;
return tmp;
}
self operator--()//前置--
{
linkptr = linkptr->prev;
return linkptr;
}
self operator--(int)//后置--
{
listiterator tmp = linkptr;
linkptr = linkptr->next;
return tmp;
}
ref operator*()//解引用
{
return linkptr->data;
}
ptr operator->()//成员访问
{
return &(linkptr->data);
}
bool operator!=(listiterator it)//判等
{
return linkptr != it.linkptr;
}
bool operator==(listiterator it)//判等
{
return linkptr == it.linkptr;
}
Node* linkptr;
};
list的迭代器的设计思路是这样的:由于Node*的指针的行为不符合list对迭代器的需求。那么就把指针封装起来,设计成一个类,这样我们就能在类中重载各种操作符的函数,使这个类符合迭代器的行为。
比如,listiterator的迭代器进行++操作,linkptr并不会指向顺序结构的下一个元素的位置,而是指向节点的后继节点,这就使listiertaor符合list的迭代器行为,然后在list当中将listiterator实例化成iterator。这样就能用迭代器完成迭代操作了。
既然写好了迭代器的类,现在就将迭代器放进list类中吧,顺便再把begin和end实现出来
template<class T>
class list
{
public:
typedef ListNode<T> Node;
typedef listiterator<T, T&, T*> iterator;
typedef listiterator<T, const T&, const T*> const_iterator;
iterator begin()
{
return _head->next;//begin返回第一个有效节点
//即_head的下一个节点
}
const_iterator begin()const
{
return _head->next;
}
iterator end()
{
return _head;
//头节点是无效节点,当链表遍历到这里时,即为遍历成功
}
const_iterator end() const
{
return _head;
}
private:
Node* _head;//指向链表头结点
};
}
begin()指向list中的第一个有效数据,因此我们返回_head->next.
而end()指向list的无效数据(因为STL规定begin到end的区间是左闭右开[begin,end),这意味着end()返回无效的位置),而头结点保存的是无效数据,因此end()返回头结点_head
我们用范围for测试一下,如果成功,就代表迭代器实现完成了。
void TestMylist1()
{
list<int> list1;
list1.push_back(1);
list1.push_back(2);
list1.push_back(3);
list1.push_back(4);
for (auto& e : list1)
{
cout << e << ' ';
}
}
插入和删除
我们先来写写单元素的insert和erase。来看看c标准定义的函数原型吧。
iterator insert (iterator position, const value_type& val);
iterator erase (iterator position);
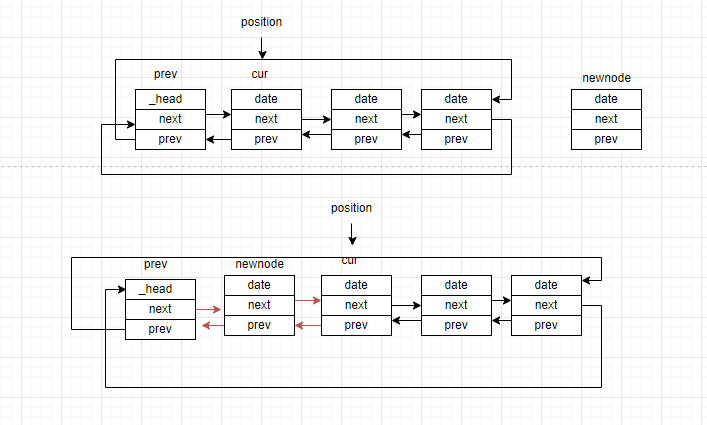
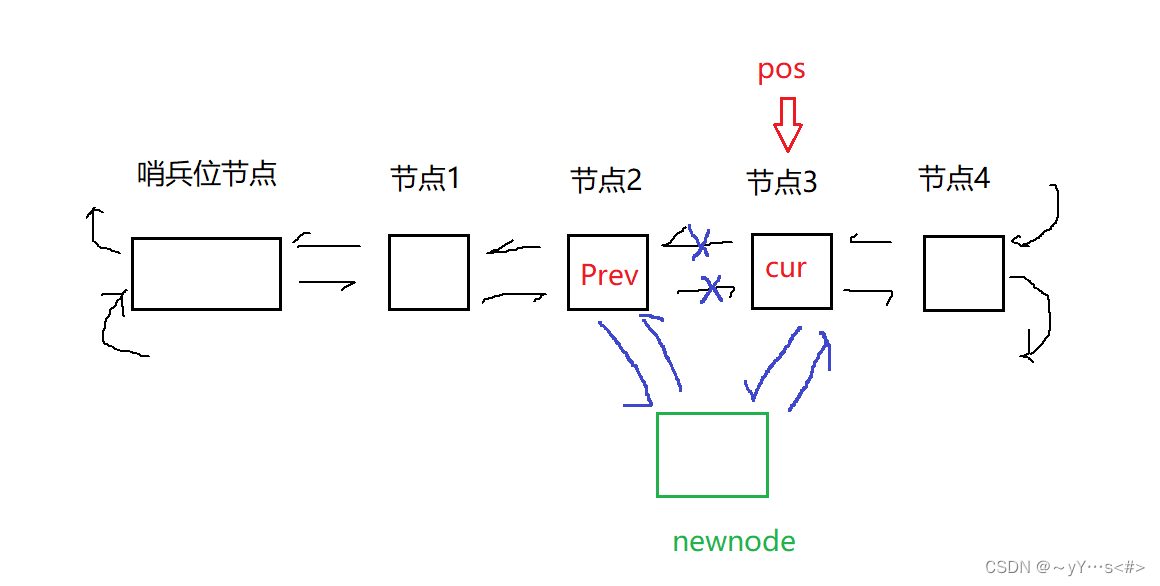
insert需要传入迭代器position,在position位置处插入新的节点。具体操作如下:
(1)构造一个值为val的新节点newnode
(2)令position位置的节点为cur,cur的前驱节点为prev
(3)让newnode的next指向cur
(4)让newnode的prev指向prev。
(5)让prev的next指向newnode
(6)让cur的prev指向newnode
这个position可以是任意位置,包括头结点和尾结点。我们注意insert是存在返回值的,而且返回值是一个迭代器。我们查看c++文档的叙述。这个返回值是指向新插入的节点的迭代器。
iterator insert(iterator position, const T& val)
{
Node* newnode = new Node(val);
Node* cur = position.linkptr;
Node* prev = cur->prev;
newnode->next = cur;
newnode -> prev = prev;
prev->next = newnode;
cur->prev = newnode;
return iterator(newnode);
}
erase也是通过迭代器position确定删除的节点位置,具体操作如下:
(1)让position位置的节点为cur
(2)让cur的前驱节点为prev,让position的后继节点为next
(3)让prev的next指向next
(4)让next的prev指向prev
(5)delete掉cur
要注意erase操作不能删除头结点(STL中的list也是这么做的),即pos位置不能是list.end()因此我们在函数的前面加上一句断言。
c++标准当中规定,erase返回被删除节点的下一个节点。因此erase应该实现成这样。
iterator erase(iterator position)
{
assert(position != end());
Node* cur = position.linkptr;
Node* prev = cur->prev;
Node* next = cur->next;
next->prev = prev;
prev->next = next;
return iterator(next);
}
insert和erase其实是很万能的,如果我们想要头插,可以调用erase(list.begin(),val),如果想要头删,可以调用erase(list.begin())。包括尾插和尾删,我们都可以通过insert和erase实现操作。因此push_back,push_fornt,pop_back,pop_front,都可以复用insert和erase.
void push_back(const T& val)
{
insert(end(), val);
}
void pop_back()
{
erase(--end());
}
void push_front(const T&val)
{
insert(begin(), val);
}
void pop_front()
{
erase(end());
}
构造、析构、赋值
通常我们在写一个类时,都会先写类的构造、析构、赋值重载函数。但是list有点不同,因为list的大部分构造、析构都依赖迭代器的实现。因此在list的末尾,博主才对这些函数进行实现。
copy构造
copy (4)
list (const list& x);
list的拷贝构造是深拷贝,浅拷贝会导致内存错误,list深拷贝的方法如下:
我们遍历x,将x的元素按照顺序尾插到list容器中。但是光拷贝可不行啊,容器还没有生成头结点(遍历x的时候可不会遍历头结点,因为头结点被视为容器的终点end)。所以我们先创建一个头结点。
void emptynode()//创建头结点
{
_head = new Node;//_head指向头结点,头结点是默认构造的Node
_head->next = _head;
_head->prev = _head;
}
emptynode函数只用于对象构造时创建空节点,所以我们最好把它隐藏起来(protected或者private)。
list(const list& l1)
{
emptynode();
for (const auto& e : l1)
{
push_back(e);
}
}
initializer_list构造
initializer_list是c++11新增的模板类,关于initializer_list大家可以查看c++手册,或者查看博主的另一篇博客:好用的c++11语言特性
initializer list (6)
list (initializer_list<value_type> il,
const allocator_type& alloc = allocator_type());
initializer_list可以简单的认为是一个存储数据数组,那么构造的方法也很简单,遍历initializer_list的元素,将元素挨个尾插到容器当中。
list<int> list2(list1);
for (const auto& e : list2)
{
cout << e << ' ';
}
operator =
赋值操作和拷贝操作的逻辑一致,我直接套用就行。不过这种套用可是单纯的将程序代码复制粘贴过来,我们会利用到一种取巧的方法
const list& operator=(list x)
{
std::swap(_head, x._head);
return *this;
}
ok,就是这么一个简短的代码,但是其思想可一点都不简短。
首先是函数的形参,没有继续采取常用的pass by const reference(const T&)。而是选择了pass by value的形式, 这就导致调用operator=函数时,形参x会调用拷贝构造构造拷贝实参。

然后我们将容器的头结点和x的头结点进行交换,使得容器获得实参的内容。
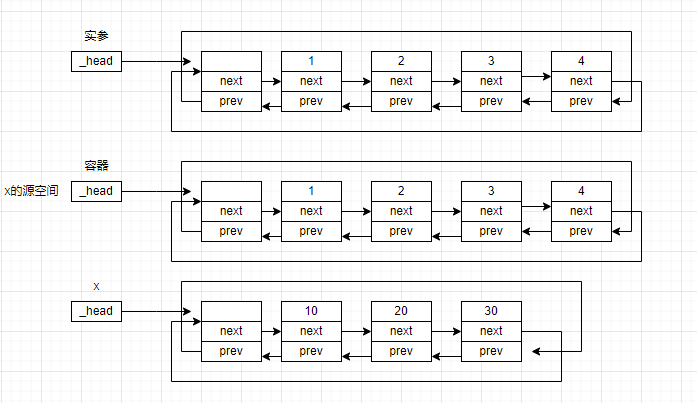
ok,我们发现了一个有趣的现象,容器现在结构、数据都和实参一致了,这难道不是完成了复制操作吗?
而且这种方法还有一个特别有意思的地方,x是一个临时变量,这就说明x中的空间是没有实际作用的,我们需要将其空间释放掉,但是x是栈帧中的参数,一旦离开了栈帧,x会调用析构函数将资源依次释放。是不是很神奇,简短的三行代码,竟然进行了这么多的操作。而且效率还不低。
析构函数
好吧,讲到最后才完成析构函数,这其实不是很好的习惯,如果你将析构函数放到最后一步,一旦程序通过了测试,你可能就认为已经完成了所有操作,便遗忘掉了析构函数,那么等到内存泄漏的时候可就麻烦了。
list的析构函数应该完成以下操作,释放所有的有效结点,最后释放头结点。额,实际上c++标准定义了list的成员函数clear,clear会释放除头结点外的所有节点。那么为什么博主没有提到呢?因为博主忘了哈哈哈哈。
我们从第一个有效节点开始遍历,每遍历一个节点就释放该节点的空间,直到我们回到头结点为止。
void clear()
{
iterator start = begin();
while (start != end())
{
start=erase(start);
}
}
erase的返回值是被删除节点的下一个节点,正好拿来用了哈哈哈。
诶,我们的析构函数是做什么来着,先释放所有的有效节点,再释放头结点,OK,clear正好是释放所有的有效节点,那我们就直接拿来复用就行了啊。
~list()
{
clear();
delete _head;
_head = nullptr;
}
![[<span style='color:red;'>C</span>++]:<span style='color:red;'>12</span>:<span style='color:red;'>模拟</span><span style='color:red;'>实现</span><span style='color:red;'>list</span>](https://img-blog.csdnimg.cn/direct/5b9d575ec6cd44dba58a257a6a20f003.png)


























![[数据集][目标检测]脑溢血检测数据集VOC+YOLO格式767张2类别](https://img-blog.csdnimg.cn/direct/979c7b004da248a0a0b847cb88ce6d40.png)



