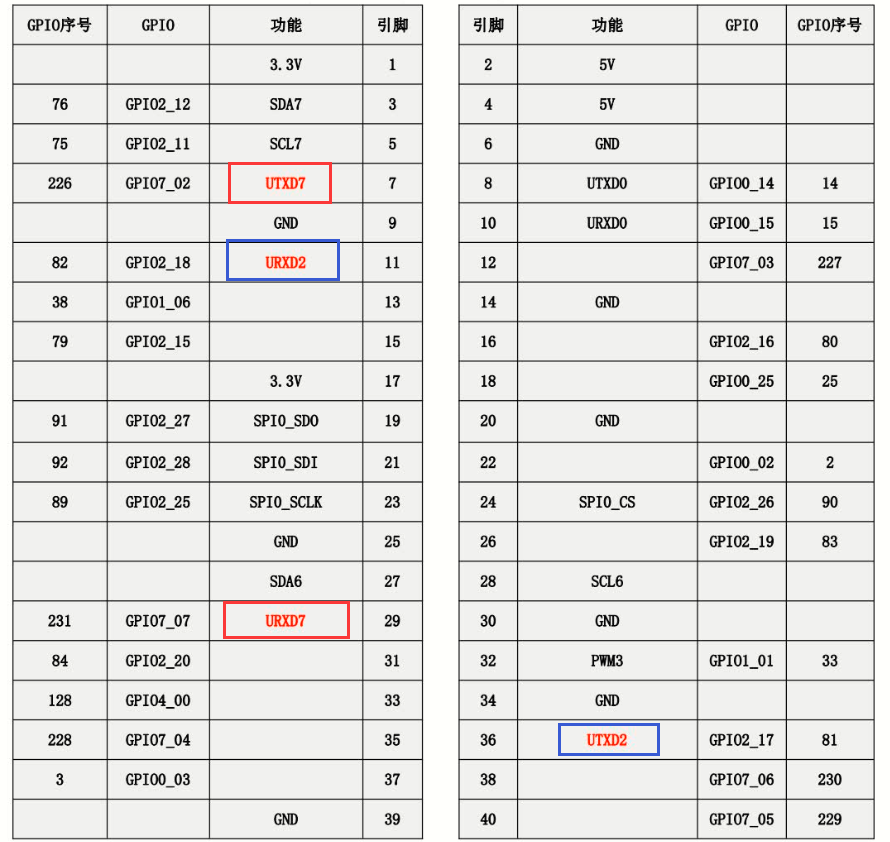
上一篇我们讲了使用CNN进行分类的python代码:
Mr.看海:【深度学习-第5篇】使用Python快速实现CNN分类(模式识别)任务,含一维、二维、三维数据演示案例(使用pytorch框架)
这一篇我们讲CNN的多变量回归预测。
是的,同样是傻瓜式的快速实现。
本篇是之前MATLAB快速实现CNN多变量回归预测的姊妹篇。
一、环境搭建
本篇使用的是Win10系统搭建VSCode+Anaconda+Pytorch+CUDA环境,当然如果你是用的是其他编辑器,没有使用anaconda,或者没有独立显卡,本文的程序也都是可以实现的(不过也需要正确配置好了相关环境)。
如果你还没有配置环境,或者配置的环境运行后边的代码有错误,那么推荐大家按照我之前的这篇文章操作来重新进行配置:
Mr.看海:【深度学习-番外1】Win10系统搭建VSCode+Anaconda+Pytorch+CUDA深度学习环境和框架全过程
环境搭建中遇到的问题,大家可以集中在上边这篇文章中留言反映。
二、什么是多变量回归预测
多变量回归预测则是指同时考虑多个输入特征进行回归预测。举几个例子:
- 房价预测:给定一组房产的特征,如面积、卧室数量、浴室数量、地理位置等,预测房产的销售价格。
- 股票价格预测:使用历史股票价格、交易量、财务指标等信息,预测未来某个时间点的股票价格。
- 销售预测:基于历史销售数据、季节性、促销活动等信息,预测未来某个时间段的销售额。
- 能源需求预测:考虑天气条件、时间(如一天中的时间、一周中的哪一天、一年中的哪个月份等)、历史能源需求等因素,预测未来的能源需求。
- 疾病风险预测:根据患者的年龄、性别、生活习惯、基因信息等,预测患者罹患某种疾病的风险。
在许多实际问题中,我们通常需要考虑多个输入特征。虽然 CNN 最初是为图像分类问题设计的,但它也可以应用于回归预测问题。在这种情况下,CNN 的目标不再是预测输入图像的类别,而是预测一个连续的目标值。为此,我们可以将 CNN 的最后一层全连接层修改为输出一个单一的连续值,然后使用一个回归损失函数(如均方误差)来训练网络。
CNN 由于其强大的特征提取能力,特别适合处理这种多变量的回归预测问题。

这篇文章我们就以房价预测为例吧
三、一个简单的案例——波士顿房价预测
下面我们将演示如何使用pytorch实现一个卷积神经网络(CNN)来进行波士顿房价的多变量回归预测。我们将使用波士顿房价数据集来训练我们的模型,该数据集包含波士顿城郊区域的房屋的多个特性(如犯罪率、房间数量、教师学生比例等)和房价。如下图每组房价数据由13个相关属性(即13个指标变量),1个目标变量(房价)组成,总共有506组数据,即为506*14的数组。

房价数据
下边代码我将详细讲解逐行写到注释当中,为了增加可读性,正文文字仅做流程讲解。
0. 安装必要的库并导入
如果大家使用上述环境搭建方法,使用了conda的环境,则不需要再额外安装库。如果不是的话,你可能会需要安装numpy,torch和sklearn等。
安装好之后,代码中导入必要的库:
import numpy as np
# 导入NumPy库,用于数组操作和数值计算
import torch
# 导入PyTorch库,用于构建和训练神经网络模型
import torch.nn as nn
# 导入torch.nn模块,其中包含了各种神经网络层和损失函数
import torch.optim as optim
# 导入torch.optim模块,其中包含了各种优化算法
from torch.utils.data import DataLoader, TensorDataset
# 从torch.utils.data模块中导入DataLoader和TensorDataset类
# DataLoader用于创建数据加载器,实现批量读取和数据打乱等功能
# TensorDataset用于将数据封装成数据集对象,便于传递给DataLoader
import matplotlib.pyplot as plt
# 导入Matplotlib的pyplot模块,用于绘制图形和可视化结果
from sklearn.preprocessing import MinMaxScaler
# 从scikit-learn库的preprocessing模块中导入MinMaxScaler类
# MinMaxScaler用于对数据进行最小-最大归一化,将数据缩放到[0, 1]的范围内1. 数据预处理
首先,我们从 'housing.txt' 中读取数据。
# 读取数据
data = np.loadtxt('housing.txt')
# 使用NumPy的loadtxt函数从文件'housing.txt'中读取数据
# 假设数据文件的格式为每行代表一个样本,不同的特征值和目标值之间用空格或制表符分隔
# 读取的数据将被存储在NumPy数组data中
X = data[:, :13]
# 数据集中前13列是输入特征,每一行代表一个样本,每一列代表一个特征
# data[:, :13]表示选取数组的所有行和前13列
y = data[:, 13]
# 通过数组切片操作,将数据的第14列提取出来,赋值给变量y
# 这里假设数据集中第14列是目标值,即我们要预测的房价然后将输入和输出数据进行归一化处理。数据归一化的目的是将不同特征的值缩放到相似的范围,以提高模型的收敛速度和性能。这在处理具有不同量纲或范围的特征时尤为重要。
# 数据归一化处理
scaler_x = MinMaxScaler()
# 创建一个MinMaxScaler对象scaler_x,用于对输入特征X进行归一化处理
# MinMaxScaler会将数据缩放到[0, 1]的范围内
X = scaler_x.fit_transform(X)
# 使用scaler_x对输入特征X进行拟合和转换
# fit_transform方法会计算数据的最小值和最大值,并将数据缩放到[0, 1]的范围内
# 转换后的数据将覆盖原始的X
scaler_y = MinMaxScaler()
# 创建另一个MinMaxScaler对象scaler_y,用于对目标值y进行归一化处理
y = scaler_y.fit_transform(y.reshape(-1, 1)).flatten()
# 使用scaler_y对目标值y进行拟合和转换
# 由于MinMaxScaler期望输入是二维数组,因此需要使用reshape(-1, 1)将y转换为二维数组
# reshape(-1, 1)表示将y转换为一个列向量,行数自动推断
# fit_transform方法会计算数据的最小值和最大值,并将数据缩放到[0, 1]的范围内
# 最后使用flatten()将转换后的二维数组重新转换为一维数组,覆盖原始的y将数据转换为PyTorch张量是在PyTorch中进行模型训练和推理的必要步骤。PyTorch模型接受张量作为输入,并对张量进行操作和计算。
# 将数据转换为PyTorch张量
X = torch.tensor(X, dtype=torch.float32)
# 使用torch.tensor函数将NumPy数组X转换为PyTorch张量
# dtype=torch.float32指定张量的数据类型为32位浮点数
# 转换后的张量X将用于模型的输入
y = torch.tensor(y, dtype=torch.float32)
# 转换后的张量y将用于模型的训练和评估2.数据集划分
下边将数据集划分为训练集、验证集和测试集,可以全面评估模型的性能。训练集用于训练模型,验证集用于调整模型的超参数和进行模型选择,测试集用于评估模型在未见过的数据上的泛化能力。
# 数据集划分
train_ratio = 0.7
val_ratio = 0.1
# 定义训练集和验证集的比例
# train_ratio表示训练集占总数据的比例,这里设置为0.7,即70%的数据用于训练
# val_ratio表示验证集占总数据的比例,这里设置为0.1,即10%的数据用于验证
# 剩下的20%用于测试
num_samples = len(X)
# 获取数据集的样本数,即X的长度
num_train = int(num_samples * train_ratio)
num_val = int(num_samples * val_ratio)
# 计算训练集和验证集的样本数
# num_train表示训练集的样本数,通过总样本数乘以训练集比例并取整得到
# num_val表示验证集的样本数,通过总样本数乘以验证集比例并取整得到
train_data = X[:num_train]
train_labels = y[:num_train]
# 使用切片操作提取训练集数据和标签
# train_data表示训练集的输入特征,取X的前num_train个样本
# train_labels表示训练集的目标值,取y的前num_train个样本
val_data = X[num_train:num_train+num_val]
val_labels = y[num_train:num_train+num_val]
# 使用切片操作提取验证集数据和标签
# val_data表示验证集的输入特征,取X从num_train到num_train+num_val的样本
# val_labels表示验证集的目标值,取y从num_train到num_train+num_val的样本
test_data = X[num_train+num_val:]
test_labels = y[num_train+num_val:]
# 使用切片操作提取测试集数据和标签
# test_data表示测试集的输入特征,取X从num_train+num_val到最后的样本
# test_labels表示测试集的目标值,取y从num_train+num_val到最后的样本3.创建数据加载器
下面我们来创建用于训练、验证和测试的数据加载器。使用PyTorch的TensorDataset类将数据和标签打包成数据集对象。然后通过DataLoader类创建数据加载器,指定批次大小和数据打乱选项。
# 创建数据加载器
train_dataset = TensorDataset(train_data, train_labels)
val_dataset = TensorDataset(val_data, val_labels)
test_dataset = TensorDataset(test_data, test_labels)
# 使用TensorDataset将训练集、验证集和测试集的数据和标签打包成数据集对象
# TensorDataset接受多个张量作为参数,将它们组合成一个数据集
# train_dataset表示训练集的数据集对象,包含训练数据和标签
# val_dataset表示验证集的数据集对象,包含验证数据和标签
# test_dataset表示测试集的数据集对象,包含测试数据和标签
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=64)
test_loader = DataLoader(test_dataset, batch_size=64)
# 使用DataLoader创建数据加载器,用于批次读取数据
# train_loader表示训练集的数据加载器,batch_size=64表示每个批次包含64个样本,shuffle=True表示在每个epoch开始时打乱数据顺序
# val_loader表示验证集的数据加载器,batch_size=64表示每个批次包含64个样本
# test_loader表示测试集的数据加载器,batch_size=64表示每个批次包含64个样本4.定义CNN模型
下边这段代码定义了一个卷积神经网络(CNN)模型。
模型结构包括一个卷积层(conv1)和一个全连接层(fc1)。卷积层使用32个大小为(3, 1)的卷积核,并在输入周围进行零填充。卷积层的输出经过ReLU激活函数进行非线性变换。
这里只是演示了一种最简单的CNN网络结构,在实际应用中,大家可以根据实际做更复杂的修改。如果你还不太懂CNN的网络结构,可以看我之前的这篇图解文章:关于CNN网络结构的图解入门。

# 定义CNN模型
class CNN(nn.Module):
def __init__(self, input_dim):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=(3, 1), padding=(2, 2))
# 定义一个二维卷积层,输入通道为1,输出通道为32,卷积核大小为(3, 1),padding为(2, 2)
self.relu1 = nn.ReLU()
# 定义一个ReLU激活函数
# 计算卷积层输出的维度
conv_output_dim = self.conv1(torch.zeros(1, 1, input_dim, 1)).view(-1).shape[0]
# 通过将全零张量传递给卷积层并展平输出,计算卷积层输出的维度
self.fc1 = nn.Linear(conv_output_dim, 1)
# 定义一个全连接层,输入维度为卷积层输出的维度,输出维度为1
def forward(self, x):
x = x.unsqueeze(1).unsqueeze(3) # 增加通道维度和高度维度
# 在输入张量x上增加通道维度和高度维度,以满足卷积层的输入要求
x = self.conv1(x)
# 将输入张量x传递给卷积层
x = self.relu1(x)
# 对卷积层的输出应用ReLU激活函数
x = x.view(x.size(0), -1)
# 将卷积层的输出展平为二维张量,第一维为批次大小,第二维为特征维度
x = self.fc1(x)
# 将展平后的张量传递给全连接层,得到最终的输出
return x
model = CNN(input_dim=X.shape[1])
# 创建CNN模型的实例,输入维度为X的特征数
模型使用均方误差(MSE)作为损失函数,并使用Adam优化器对模型参数进行优化,学习率设置为0.01。
# 设置损失函数和优化器
criterion = nn.MSELoss()
# 定义均方误差损失函数
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 定义Adam优化器,学习率为0.01,优化对象为模型的参数5.训练模型
下边这段代码实现了卷积神经网络(CNN)模型的训练过程。
训练过程分为多个epoch,,每个epoch中模型在训练集上进行训练,并在验证集上进行评估。
在每个epoch结束时,打印当前的epoch数、平均训练损失和平均验证损失,以监控模型的训练进度和性能。这个训练过程重复进行指定的epoch数,以优化模型参数并提高模型的性能。
# 训练模型
num_epochs = 20
# 设置训练的轮数为20
train_losses = []
val_losses = []
# 定义用于存储训练损失和验证损失的列表
for epoch in range(num_epochs):
model.train()
# 将模型设置为训练模式
train_loss = 0.0
# 初始化训练损失为0.0
for data, labels in train_loader:
# 遍历训练数据加载器,获取每个批次的数据和标签
optimizer.zero_grad()
# 将优化器的梯度置零
outputs = model(data)
# 将数据输入模型,得到预测输出
loss = criterion(outputs, labels.unsqueeze(1))
# 计算预测输出和真实标签之间的损失,需要将标签增加一个维度以匹配输出的形状
loss.backward()
# 反向传播计算梯度
optimizer.step()
# 更新模型参数
train_loss += loss.item() * data.size(0)
# 累加训练损失,乘以批次大小以得到总损失
train_loss /= len(train_loader.dataset)
# 计算平均训练损失,除以训练集的样本数
train_losses.append(train_loss)
# 将平均训练损失添加到训练损失列表中
model.eval()
# 将模型设置为评估模式
val_loss = 0.0
# 初始化验证损失为0.0
with torch.no_grad():
# 禁用梯度计算,以减少内存占用和加速计算
for data, labels in val_loader:
# 遍历验证数据加载器,获取每个批次的数据和标签
outputs = model(data)
# 将数据输入模型,得到预测输出
loss = criterion(outputs, labels.unsqueeze(1))
# 计算预测输出和真实标签之间的损失,需要将标签增加一个维度以匹配输出的形状
val_loss += loss.item() * data.size(0)
# 累加验证损失,乘以批次大小以得到总损失
val_loss /= len(val_loader.dataset)
# 计算平均验证损失,除以验证集的样本数
val_losses.append(val_loss)
# 将平均验证损失添加到验证损失列表中
print(f"Epoch [{epoch+1}/{num_epochs}], Train Loss: {train_loss:.4f}, Val Loss: {val_loss:.4f}")
# 打印当前轮数、训练损失和验证损失程序执行到此处,将会得到训练过程中训练集和验证集的Loss值。

6.在测试集上评估模型
最后我们将训练好的模型应用在测试集当中,记得要应用之前归一化的影射规则,将预测数据反归一化处理。
# 在测试集上评估模型
model.eval()
# 将模型设置为评估模式
test_preds = []
# 定义用于存储测试集预测值的列表
with torch.no_grad():
# 禁用梯度计算,以减少内存占用和加速计算
for data, _ in test_loader:
# 遍历测试数据加载器,获取每个批次的数据
outputs = model(data)
# 将数据输入模型,得到预测输出
test_preds.extend(outputs.numpy())
# 将预测输出转换为NumPy数组并添加到测试集预测值列表中
test_preds = scaler_y.inverse_transform(np.array(test_preds).reshape(-1, 1)).flatten()
# 对测试集预测值进行反归一化,将其转换为原始尺度
test_labels = scaler_y.inverse_transform(test_labels.numpy().reshape(-1, 1)).flatten()
# 对测试集真实标签进行反归一化,将其转换为原始尺度然后对预测结果进行可视化处理:
# 绘制测试集的真实值和预测值
plt.figure(figsize=(8, 6))
# 创建一个大小为(8, 6)的图形
plt.plot(test_labels, label='True Values (Testing Set)')
# 绘制测试集的真实标签,并添加标签
plt.plot(test_preds, label='Predicted Values (Testing Set)')
# 绘制测试集的预测值,并添加标签
plt.xlabel('Sample')
# 设置x轴标签为"Sample"
plt.ylabel('House Price')
# 设置y轴标签为"House Price"
plt.title('True vs. Predicted Values (Testing Set)')
# 设置图形标题为"True vs. Predicted Values (Testing Set)"
plt.legend()
# 添加图例
plt.tight_layout()
# 调整子图参数,使之填充整个图像区域
plt.show()
# 显示图形
测试集预测结果,由于训练具有一定随机性,所以每次运行结果会有一定差别
三、“一行代码”实现CNN回归预测任务(pytorch框架)
上边章节演示了使用MATLAB实现CNN回归预测的基础代码演示,不过我们在实际研究中可能会面临更为复杂的困境:
- 导入自己的数据后,网络结构一改就频频报错
- 代码被改得乱七八糟,看的头大
- 不知道该画哪些图、怎么画图
- 想要学习更规范的代码编程
- ……
按照本专栏的惯例,笔者封装了快速实现CNN回归预测的函数,在设定好相关参数后,只需要一行代码,就可以实现数据集训练集/验证集/测试集快速划分、快速绘制训练集/测试集预测结果对比图、绘制预测误差图,导出训练过程数据、计算MAE/MSE/MAPE/RMSE/R等指标等等常用功能,这个函数的介绍如下:
def FunRegCNNs(dataX, dataY, divideR, cLayer, poolingLayer, fcLayer, options, setting):
"""
使用CNN进行回归预测的快速实现函数
参数:
- dataX: 输入数据,形状为(num_samples, num_channels, height, width)的numpy数组
- dataY: 输出结果,考虑可以为多维的numpy数组
- divideR: 数据集划分比例,形如[train_ratio, val_ratio, test_ratio]的列表
- cLayer: 卷积层结构,形状为(num_conv_layers, 5)的numpy数组,每一行代表一个卷积层的参数[filter_height, filter_width, num_filters, stride, padding]
- poolingLayer: 池化层结构,形状为(num_conv_layers, 5)的列表,每一行代表一个池化层的参数['pool_type', pool_height, pool_width, stride, padding],其中pool_type可以是'maxPooling2dLayer'或'averagePooling2dLayer'或'none'
- fcLayer: 全连接层结构,形状为(num_fc_layers,)的列表,每一个元素代表一个全连接层的输出维度,如果为空列表则只有一个输出维度等于1的全连接层
- options: 网络训练相关的选项,字典类型,包含以下键值对:
- 'solverName': 优化器类型,可以是'sgdm'或'rmsprop'或'adam',默认为'adam'
- 'MaxEpochs': 最大迭代次数,默认为30
- 'MiniBatchSize': 批量大小,默认为128
- 'InitialLearnRate': 初始学习率,默认为0.005
- 'ValidationFrequency': 验证频率,即每多少次迭代进行一次验证,默认为50
- 'LearnRateSchedule': 学习率调度方式,可以是'piecewise'或'none',默认为'none'
- 'LearnRateDropPeriod': 学习率下降周期,默认为10
- 'LearnRateDropFactor': 学习率下降因子,默认为0.95
- setting: 其他选项,字典类型,包含以下键值对:
- figflag: 是否绘制图像,'on'为绘制,'off'为不绘制
- deviceSel: 训练设备选择,可以是'cpu'或'gpu',默认为'gpu',当设置为'gpu'时,如果gpu硬件不可用,则会自动切换到cpu
- seed: 随机种子,整数,设置为0时不启用,设置为其他整数时启用,不同的整数为不同的种子值,变换种子值会影响结果,相同种子的计算结果是一致的,缺省时为不设置随机种子
- minmax: 是否进行归一化,布尔值,默认为True
返回值:
- foreData: 测试集的回归预测结果
- foreDataTrain: 训练集的回归预测结果
- model: 训练好的PyTorch模型
- info: 包含训练过程中的损失和准确率信息的字典看注释写的蛮多的似乎有点唬人,其实使用起来比较简单。
例如上边波士顿房价预测的案例,整个第二章节代码可以用下述几行轻松实现:
import numpy as np
from khCNNreg import FunRegCNNs
# 1.读取 housing.txt 文件
data = np.loadtxt('housing.txt')
# 2.提取输入变量和输出变量
X = data[:, :13] # 通过数组切片操作,将数据的前13列提取出来,赋值给变量X
y = data[:, 13] # 通过数组切片操作,将数据的第14列提取出来,赋值给变量y
X = X.reshape(X.shape[0], 1, 1, X.shape[1]) # 对输入数据进行转置
divideR = [0.7, 0.1, 0.2] # 设置数据集划分比例 训练集:验证集:测试集
# 3.设置网络结构
cLayer = np.array([[3, 1, 32, 1, 2]]) # 卷积层结构
poolingLayer = [['none', 0, 0, 2, 0]] # 设置池化层结构
fcLayer = [] # 设置全连接层结构
# 4.设置网络训练选项
options = {
'MaxEpochs': 100, # 最大训练轮数为100
'MiniBatchSize': 64, # 小批量数据大小为64
'InitialLearnRate': 0.01, # 初始学习率为0.01
'ValidationFrequency': 5, # 每5个epoch进行一次验证
'LearnRateDropPeriod': 10, # 每10个epoch学习率下降一次
'LearnRateDropFactor': 0.9 # 学习率下降因子为0.9
}
# 5.设置其他选项
setting = {
'figflag': 'on', # 显示图形
'deviceSel': 'gpu', # 使用GPU作为设备
'seed': 42, # 随机种子设置为42
'minmax': True # 进行最小最大值归一化
}
# 6.调用 FunRegCNNs 函数进行测试
foreData, foreDataTrain, model, info = FunRegCNNs(X, y, divideR, cLayer, poolingLayer, fcLayer, options, setting)上述代码中留下需要设置的,都是必要的参数,这也是为了在保证代码易用性的同时充分保证灵活性。
运行上述代码可以得到一系列图片和指标,这些在写论文过程中都是很有用的。
具体包括:






在命令行窗口还会打印出以下内容:


四、总结
使用封装函数对复杂的CNN训练和评估流程进行了高度封装,大家只需要提供数据和指定参数,就可以轻松进行模型的训练和评估,大大减轻了同学们负担;另外函数接收多个参数作为输入,包括网络结构和训练选项等,使得用户可以根据自己的需求灵活地定制和配置模型,适应各种不同的应用场景;此函数不仅实现了CNN模型的训练,还对模型的性能进行了全面评估,并返回了训练过程中的详细信息,助力用户快速理解模型的性能,并进行后续的优化调整。
需要上述案例的代码和封装函数的代码,同学们可以在公众号 khscience(看海的城堡)中回复“CNN回归预测”获取。
扩展阅读
3.2 Mr.看海:神经网络15分钟入门!——反向传播到底是怎么传播的?
3.3 Mr.看海:神经网络15分钟入门!使用python从零开始写一个两层神经网络
3.4 Mr.看海:用深度学习做了下中国股市预测,结果是...
3.5 Mr.看海:使用MATLAB快速搭建神经网络实现分类任务(模式识别)
3.6 Mr.看海:【深度学习-第1篇】深度学习是什么、能干什么、要怎样学?
3.7 Mr.看海:【深度学习-第2篇】CNN卷积神经网络30分钟入门!足够通俗易懂了吧(图解)
3.8 Mr.看海:【深度学习-第3篇】使用MATLAB快速实现CNN分类(模式识别)任务,含一维、二维、三维数据演示案例
3.9 Mr.看海:【深度学习-第4篇】使用MATLAB快速实现CNN多变量回归预测
3.10 Mr.看海:【深度学习-番外1】Win10系统搭建VSCode+Anaconda+Pytorch+CUDA深度学习环境和框架全过程
3.11 Mr.看海:【深度学习-第5篇】使用Python快速实现CNN分类(模式识别)任务,含一维、二维、三维数据演示案例(使用pytorch框架)