在前几篇教程中,我们探讨了 sklearn 的基础、高级功能,异常检测与降维,时间序列分析与自然语言处理,模型部署与优化,以及集成学习与模型解释。本篇教程将专注于无监督学习和聚类分析,这在探索性数据分析和数据挖掘中非常重要。
无监督学习
无监督学习是一种无需预先标记数据的学习方法,主要用于发现数据的内在结构和模式。常见的无监督学习任务包括聚类分析、降维和异常检测。
聚类分析
聚类分析是将数据集划分为若干组(簇)的过程,使得同一簇中的数据点彼此相似,而不同簇中的数据点差异较大。常见的聚类算法包括 k 均值(K-Means)、层次聚类(Hierarchical Clustering)和 DBSCAN。
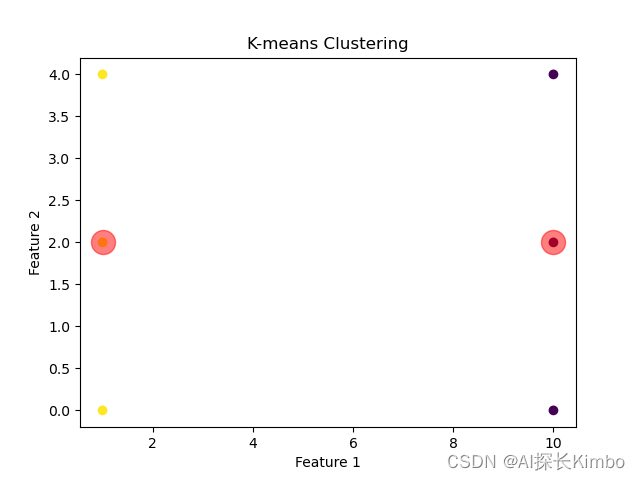
k 均值(K-Means)
k 均值是一种迭代聚类算法,通过最小化簇内数据点到簇中心的距离来划分数据。
import numpy as np
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 加载数据集
iris = load_iris()
X = iris.data
# 训练 k 均值模型
kmeans = KMeans(n_clusters=3, random_state=42)
kmeans.fit(X)
# 聚类结果
labels = kmeans.labels_
centers = kmeans.cluster_centers_
# 可视化聚类结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.scatter(centers[:, 0], centers[:, 1], c='red', marker='X', s=200)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.title('K-Means Clustering')
plt.show()
层次聚类(Hierarchical Clustering)
层次聚类通过构建树状结构(树状图)来进行聚类,常用的方法包括凝聚聚类(Agglomerative Clustering)。
from sklearn.cluster import AgglomerativeClustering
import scipy.cluster.hierarchy as sch
# 训练层次聚类模型
hc = AgglomerativeClustering(n_clusters=3, affinity='euclidean', linkage='ward')
labels = hc.fit_predict(X)
# 绘制树状图
dendrogram = sch.dendrogram(sch.linkage(X, method='ward'))
plt.title('Dendrogram')
plt.xlabel('Samples')
plt.ylabel('Euclidean distances')
plt.show()
# 可视化聚类结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.title('Hierarchical Clustering')
plt.show()
DBSCAN
DBSCAN 是一种基于密度的聚类算法,适用于发现任意形状的簇。
from sklearn.cluster import DBSCAN
# 训练 DBSCAN 模型
dbscan = DBSCAN(eps=0.5, min_samples=5)
labels = dbscan.fit_predict(X)
# 可视化聚类结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.title('DBSCAN Clustering')
plt.show()
降维
降维是通过减少数据的特征数量来简化数据,同时保留数据的重要结构和模式。常见的降维方法包括主成分分析(PCA)和 t-SNE。
主成分分析(PCA)
PCA 通过线性变换将数据投影到低维空间,同时尽量保留数据的方差。
from sklearn.decomposition import PCA
# 训练 PCA 模型
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# 可视化降维结果
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=iris.target, cmap='viridis')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA of IRIS dataset')
plt.show()
t-SNE
t-SNE 是一种非线性降维方法,适用于高维数据的可视化。
from sklearn.manifold import TSNE
# 训练 t-SNE 模型
tsne = TSNE(n_components=2, random_state=42)
X_tsne = tsne.fit_transform(X)
# 可视化降维结果
plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=iris.target, cmap='viridis')
plt.xlabel('t-SNE Component 1')
plt.ylabel('t-SNE Component 2')
plt.title('t-SNE of IRIS dataset')
plt.show()
异常检测
异常检测是识别数据集中异常或不正常数据点的过程。常用的异常检测方法包括孤立森林(Isolation Forest)和局部异常因子(Local Outlier Factor, LOF)。
孤立森林(Isolation Forest)
孤立森林通过构建随机树来隔离数据点,计算其异常分数。
from sklearn.ensemble import IsolationForest
# 训练孤立森林模型
iso_forest = IsolationForest(contamination=0.1, random_state=42)
labels = iso_forest.fit_predict(X)
# 可视化异常检测结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.title('Isolation Forest Anomaly Detection')
plt.show()
局部异常因子(LOF)
LOF 通过计算局部密度偏差来识别异常点。
from sklearn.neighbors import LocalOutlierFactor
# 训练 LOF 模型
lof = LocalOutlierFactor(n_neighbors=20, contamination=0.1)
labels = lof.fit_predict(X)
# 可视化异常检测结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.title('Local Outlier Factor Anomaly Detection')
plt.show()
综合示例项目:无监督学习与聚类分析
步骤1:数据预处理与聚类分析
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans, DBSCAN
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# 生成数据集
X, y = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# 标准化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# K-Means 聚类
kmeans = KMeans(n_clusters=4)
kmeans_labels = kmeans.fit_predict(X_scaled)
# DBSCAN 聚类
dbscan = DBSCAN(eps=0.3, min_samples=10)
dbscan_labels = dbscan.fit_predict(X_scaled)
# PCA 降维
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
# 可视化 K-Means 聚类结果
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=kmeans_labels, cmap='viridis')
plt.title('K-Means Clustering')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.show()
# 可视化 DBSCAN 聚类结果
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=dbscan_labels, cmap='viridis')
plt.title('DBSCAN Clustering')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.show()
步骤2:异常检测
from sklearn.ensemble import IsolationForest
from sklearn.neighbors import LocalOutlierFactor
# 孤立森林异常检测
iso_forest = IsolationForest(contamination=0.1, random_state=42)
iso_forest_labels = iso_forest.fit_predict(X_scaled)
# 局部异常因子异常检测
lof = LocalOutlierFactor(n_neighbors=20, contamination=0.1)
lof_labels = lof.fit_predict(X_scaled)
# 可视化孤立森林异常检测结果
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=iso_forest_labels, cmap='viridis')
plt.title('Isolation Forest Anomaly Detection')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.show()
# 可视化局部异常因子异常检测结果
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=lof_labels, cmap='viridis')
plt.title('Local Outlier Factor Anomaly Detection')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.show()
总结
通过本篇专题教程,我们学习了 sklearn 中的无监督学习和聚类分析。无监督学习包括聚类分析、降维和异常检测。聚类分析方法包括 k 均值、层次聚类和