一、说明
以下是本文重要观点的摘要。阅读它以获取更多详细信息/获取原始源链接。很多 AI 人都想构建像 GPT 4 这样的大型 AI 模型。让我们来谈谈一些技术,这些技术可以让您在不崩溃的情况下扩展您的模型。这些技术将使您能够扩展 AI 模型,在不显着增加成本的情况下提高系统的表达能力

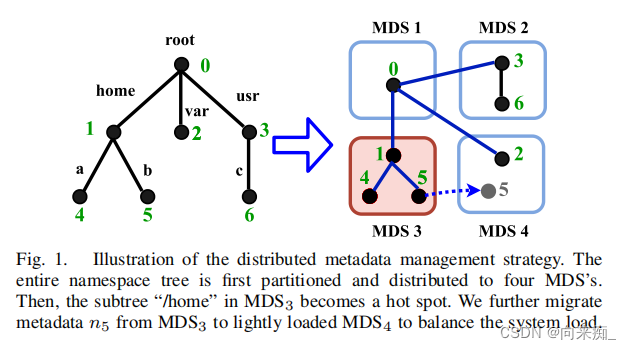
这张图片由我在这里介绍的 Pathways 系统提供
二、第一种:批量大小
增加批处理大小可以减少训练时间和成本,但可能会影响泛化。人工智能研究人员已经清楚地注意到,增加批量大小会扰乱你的准确性和泛化。对于大批量训练的低泛化,甚至有一个众所周知的术语——泛化差距。关于那个——这是一个神话。 它确实存在,如果你增加批处理大小而不做其他可以补偿的事情。
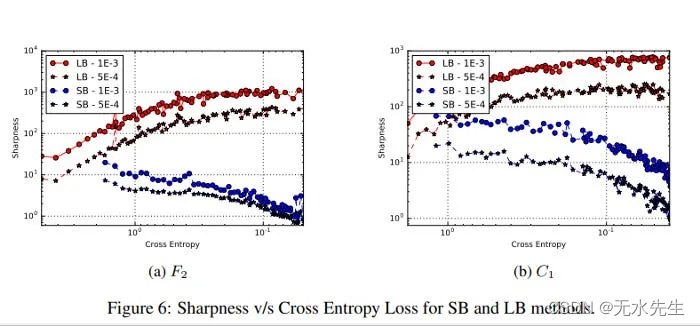
如果您只是增加批量大小而不更改任何其他内容,您的模型将卡在更尖锐的最小值中。这就是泛化差距背后的原因,这在论文《深度学习的大批量训练:泛化差距和尖锐最小值》中得到了证明。
这种权衡可以通过“幽灵批量归一化”等技术来缓解,正如论文“训练时间更长,泛化更好:缩小神经网络大批量训练中的泛化差距”中所建议的那样。

还有其他技术可以克服这一限制。所有这些都将使您能够最大限度地节省大批量产品的成本,而不会错过性能。
三、第二种:主动学习
这里有一个非常简单的想法 - 如果你有一个预训练的模型,那么有些数据点更容易建模,而另一些数据点则更难建模。较难处理的数据点为您的模型提供了更多潜在信息。因此,将训练重点放在忽略模型认为容易的数据点上是有意义的。如果埃尔林·哈兰德(Erling Haaland)想从“联赛2”球员毕业,那么他最好与困难的对手一起训练,而不是我。
一个很好的实现是 Meta 的“超越神经缩放定律:通过数据修剪击败幂律缩放”。
广泛观察到的神经缩放定律,其中误差会随着训练集大小、模型大小或两者的幂而下降,这推动了深度学习的性能大幅提高。然而,仅通过扩展进行这些改进就需要相当大的计算和能源成本。在这里,我们重点关注误差随数据集大小的缩放,并展示了在理论和实践中,如果我们能够访问高质量的数据修剪指标,我们可以如何突破幂律缩放并将其简化为指数缩放,该指标对应丢弃训练示例的顺序进行排序,以实现任何修剪后的数据集大小。然后,我们用修剪后的数据集大小实证测试了这种新的指数缩放预测,并且确实在 CIFAR-10、SVHN 和 ImageNet 上训练的 ResNets 上观察到比幂律缩放性能更好的结果。鉴于寻找高质量修剪指标的重要性,我们在 ImageNet 上对 10 种不同的数据修剪指标进行了首次大规模基准测试研究。我们发现大多数现有的高性能指标都无法扩展到 ImageNet,而最好的指标是计算密集型的,并且需要为每张图像添加标签。因此,我们开发了一种新的简单、廉价且可扩展的自监督修剪指标,该指标的性能与最佳监督指标相当。总的来说,我们的研究表明,发现良好的数据修剪指标可能会为大幅改进神经缩放定律提供一条可行的途径,从而降低现代深度学习的资源成本。
四、第三种:增加代币数量
Deepmind 的论文“训练计算-最优大型语言模型”的研究强调了平衡语言模型中参数数量和训练令牌数量的重要性,以更低的成本实现更好的性能。如果你喜欢LLM,强烈建议你阅读这篇论文,因为它是世代相传的。

五、第四种: 稀疏激活
稀疏权重激活训练 (SWAT) 等算法可以通过仅激活神经网络的一部分来显着减少训练和推理期间的计算开销。5/7 必须知道想法。让我们来谈谈它。
回想一下神经网络的工作原理。当我们训练它们时,输入流经所有神经元,包括向前和向后传递。这就是为什么向神经网络添加更多参数会成倍增加成本的原因。
在我们的网络中添加更多的神经元允许我们的模型从更复杂的数据(如来自多个任务的数据和来自多个感官的数据)中学习。但是,这会增加大量计算开销。
对于 ImageNet 上的 ResNet-50,SWAT 将训练期间的总浮点运算 (FLOPS) 减少了 80%,从而在代表新兴平台的模拟稀疏学习加速器上运行时,训练速度提高了 3.3×而验证精度仅降低 1.63%。此外,SWAT 在向后传递期间将内存占用量减少了 23% 到 50%,对于权重减少了 50% 到 90%。
稀疏激活允许两全其美的方案。添加大量参数可以让我们的模型有效地学习更多任务(并建立更深层次的联系)。稀疏激活允许您仅使用网络的一部分,从而减少推理。这使得网络可以学习并擅长多项任务,而不会花费太高的成本。
六、第五种:过滤器和更简单的模型
与其仅仅依赖大型模型,不如使用更简单的模型或过滤器来处理大多数任务,将大型模型保留给复杂的边缘情况。你会惊讶于你可以用正则表达式、规则和一些数学完成多少。
通过结合这些策略,我们可以释放大型人工智能模型的潜力,同时最大限度地降低其对环境的影响和计算成本。正如亚马逊云科技所指出的,“在深度学习应用程序中,推理占总运营成本的 90%”,这使得这些优化对于广泛采用至关重要。
再一次,要了解有关这些技术的更多信息,请阅读以下内容-
如何高效构建 ChatGPT 等大型 AI 模型
可用于在系统中使用大型数据模型而不会破坏系统的技术
后记
感谢您抽出宝贵时间。与往常一样,如果您有兴趣与我合作或查看我的其他作品,我的链接将位于此电子邮件/帖子的末尾。如果你在这篇文章中发现了价值,我将不胜感激你与更多的人分享。正是像您这样的口碑推荐帮助我成长。
我花了很多精力来创作信息丰富、有用且不受不当影响的作品。如果您想支持我的写作,请考虑成为本通讯的付费订阅者。这样做可以帮助我投入更多的精力进行写作/研究,接触更多的人,并支持我严重的巧克力牛奶成瘾。帮助我每周向超过 100K 读者宣传 AI 研究和工程中最重要的思想。