一、问题引出
object TestRDDPersist {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("persist")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(
"hello world", "hello spark"
))
val flatRdd = rdd.flatMap(_.split(" "))
val mapRdd = flatRdd.map(word => {
println("@@@@@@@@@@")
(word, 1)
})
val reduceRdd = mapRdd.reduceByKey(_ + _)
reduceRdd.collect().foreach(println)
println("**********")
val groupRdd = mapRdd.groupByKey()
groupRdd.collect().foreach(println)
}
}
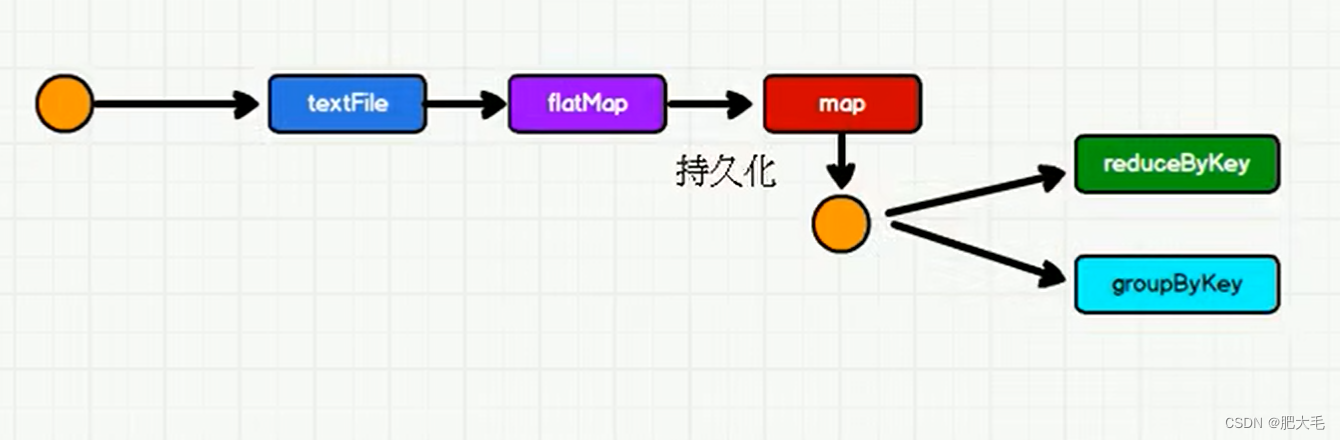
二、RDD Cache
object TestRDDPersist {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("persist")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(
"hello world", "hello spark"
))
val flatRdd = rdd.flatMap(_.split(" "))
val mapRdd = flatRdd.map(word => {
println("@@@@@@@@@@")
(word, 1)
})
mapRdd.persist()
val reduceRdd = mapRdd.reduceByKey(_ + _)
reduceRdd.collect().foreach(println)
println("**********")
val groupRdd = mapRdd.groupByKey()
groupRdd.collect().foreach(println)
}
}
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
}
三、RDD CheckPoint
object TestRDDPersist {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("persist")
val sc = new SparkContext(conf)
sc.setCheckpointDir("checkpoint")
val rdd = sc.makeRDD(List(
"hello world", "hello spark"
))
val flatRdd = rdd.flatMap(_.split(" "))
val mapRdd = flatRdd.map(word => {
println("@@@@@@@@@@")
(word, 1)
})
mapRdd.checkpoint()
val reduceRdd = mapRdd.reduceByKey(_ + _)
reduceRdd.collect().foreach(println)
println("**********")
val groupRdd = mapRdd.groupByKey()
groupRdd.collect().foreach(println)
}
}
四、缓存和检查点区别
- cache 和 persist 会在原有的血缘关系中添加新的依赖,一旦数据出错可以重头读取数据;checkpoint 检查点会切断原有的血缘关系,重新建立新的血缘关系,相当于改变数据源
- cache 是将数据临时存储在 JVM 堆内存中,性能较高,但安全性低,persist 可以指定存储级别,将数据临时存储在磁盘文件中,涉及到 IO,性能较低,作业执行完毕后临时文件会被删除;checkpoint 是将数据长久地存储分布式文件系统中,安全性较高,但涉及 IO 且会独立开启一个作业从数据源开始获取数据,所以性能较低,一般在 checkpoint 前先进行 cache,当 checkpoint 时 job 只需从缓存中读取数据即可,可以提高性能




























![mysql 8 [HY000][1114] The table ‘/tmp/#sql4c3_3e5a0_2‘ is full](https://img-blog.csdnimg.cn/direct/70ff6e8339ba425192fe99e894f3d46e.png)
