介绍
这段代码是一个基于 TensorFlow 和 Keras 的深度学习模型,用于进行数据的回归任务。让我逐步解释一下:
导入必要的库:这里导入了 NumPy 用于数值计算,Pandas 用于数据处理,Matplotlib 用于绘图,TensorFlow 用于构建和训练深度学习模型,以及一些相关的模块和函数。
读取 CSV 文件:使用 Pandas 读取名为 "data_csv.csv" 的 CSV 文件,将数据存储在 DataFrame 中。
提取 X 和 y:从 DataFrame 中提取特征变量和目标变量,并将它们转换为 NumPy 数组的形式。
调整 X 的形状:将特征变量 X 的形状重新调整为 (1000, 100, 1),这是因为该模型使用了 Conv1D 层,需要三维输入,其中 100 是时间步长,1 是特征数量。
划分数据集:将数据集划分为训练集和测试集,其中测试集占比为 20%。
构建 CNN 模型:使用 Sequential 模型构建一个卷积神经网络模型,包括两个 Conv1D 层用于特征提取和一个全连接层用于输出。这个模型的结构是:两个卷积层(每个卷积层包括 64 个滤波器和 3 的卷积核大小),然后是一个展平层,接着是一个具有 50 个神经元的隐藏层,最后是一个输出层。
编译模型:使用 Adam 优化器和均方误差损失函数编译模型。
训练模型:使用训练集进行模型训练,共训练 50 个 epochs,批量大小为 32,并在训练过程中使用了验证集来监测模型的性能。
进行预测并评估模型:使用测试集进行模型预测,并计算预测结果与真实结果之间的均方误差。
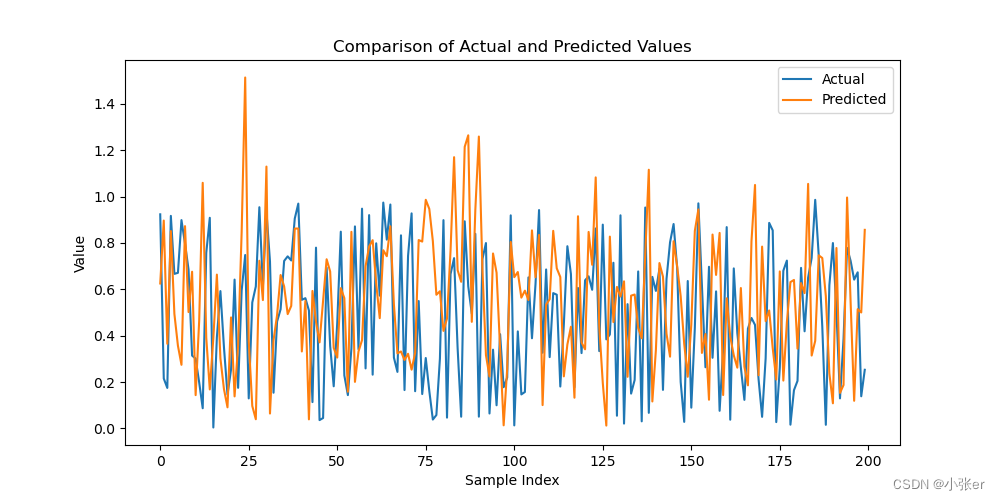
绘制实际值和预测值的比较图:使用 Matplotlib 绘制了实际值和预测值的比较图,以直观地查看模型的预测效果。
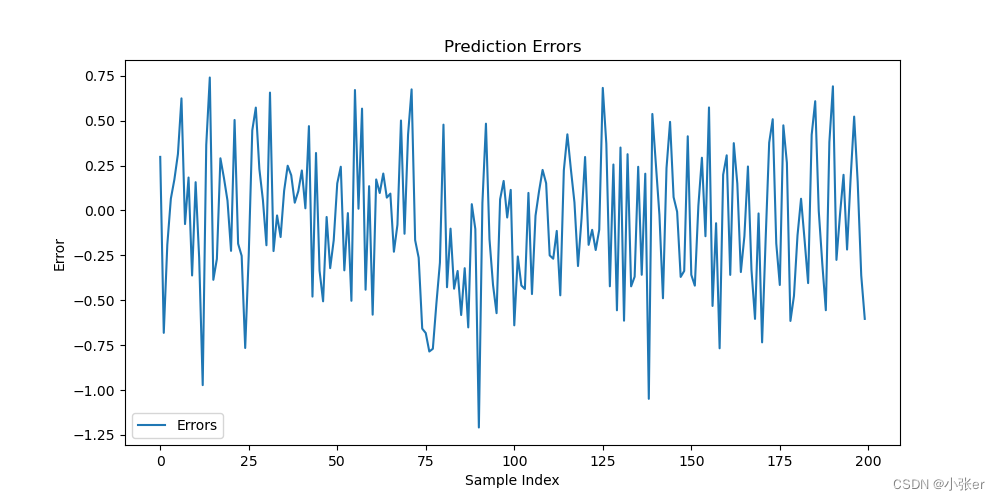
绘制预测误差图:使用 Matplotlib 绘制了预测误差图,以查看模型在不同样本上的预测误差情况。
代码
# -*- coding: utf-8 -*-
# 导入必要的库:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv1D, Flatten
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 读取 CSV 文件
file_path = "data_csv.csv"
df = pd.read_csv(file_path)
# 提取 X 和 y
X = df.iloc[:, :-1].values # 提取特征
y = df.iloc[:, -1].values # 提取目标
# 重新调整 X 的形状为 (1000, 100, 1)
X = X.reshape(1000, 100, 1) # 三维一般适用于深度学习模型
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
# 构建CNN模型:
model = Sequential()
model.add(Conv1D(filters=64, kernel_size=3, activation='relu', input_shape=(X_train.shape[1], 1)))
model.add(Conv1D(filters=64, kernel_size=3, activation='relu'))
model.add(Flatten())
model.add(Dense(50, activation='relu'))
model.add(Dense(1)) # 输出层,一个神经元用于回归任务
# 编译模型
model.compile(optimizer='adam', loss='mse')
# 训练模型:
history = model.fit(X_train, y_train, epochs=50, batch_size=32, validation_split=0.1)
# 进行预测并评估模型
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f'Test MSE: {mse}')
# 绘制实际值和预测值的比较图
plt.figure(figsize=(10, 5))
plt.plot(y_test, label='Actual')
plt.plot(y_pred.flatten(), label='Predicted')
plt.title('Comparison of Actual and Predicted Values')
plt.xlabel('Sample Index')
plt.ylabel('Value')
plt.legend()
plt.show()
errors = y_test - y_pred.flatten()
plt.figure(figsize=(10, 5))
plt.plot(errors, label='Errors')
plt.title('Prediction Errors')
plt.xlabel('Sample Index')
plt.ylabel('Error')
plt.legend()
plt.show()
结果