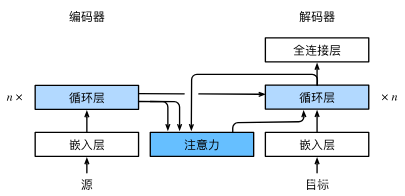
python-pytorch 实现seq2seq+luong general concat attention笔记1.0.10
上篇文章是使用luong的dot计算分数方法实现seq2seq attention简单对话,这篇文件使用general记分方法
只需要替换Attention类
- general注意力
就是在dot方法基础上,对hidden做一个线性变换
class Attention(nn.Module):
def __init__(self):
super(Attention, self).__init__()
self.va=nn.Linear(hidden_size,hidden_size,bias=False)
def forward(self, hidden, encoder_outputs):
"""
hidden:[layer_num,batch_size,hidden_size]
encoder_outputs:[seq_len,batch_size,hidden_size]
"""
score=encoder_outputs.permute(1,0,2).bmm(self.va(hidden).permute(1,2,0))# [batch_size,seq_len,layer_num]
attr=nn.functional.softmax(score,dim=1)# [batch_size,seq_len,layer_num]
context=attr.permute(0,2,1).bmm(encoder_outputs.permute(1,0,2))
return context,attr
- concat注意力
这里需要注意的是,在计算出tanh后,需要自定义个va的矩阵相乘,大小是当前的[batch_size,hidden_size*2]
class Attention(nn.Module):
def __init__(self):
super(Attention, self).__init__()
self.wa=nn.Linear(hidden_size*2,hidden_size*2,bias=False)
self.wa1=nn.Linear(hidden_size*2,hidden_size,bias=False)
def forward(self, hidden, encoder_outputs):
"""
hidden:[layer_num,batch_size,hidden_size]
encoder_outputs:[seq_len,batch_size,hidden_size]
"""
hiddenchange=hidden.repeat(encoder_outputs.size(0),1,1)#[seq_len,batch_size,hidden_size]
concated=torch.cat([hiddenchange.permute(1,0,2),encoder_outputs.permute(1,0,2)],dim=-1)# [batch_size,seq_len,hidden_size*2]
waed=self.wa(concated)# [batch_size,seq_len,hidden_size*2]
tanhed=torch.tanh(waed)# [batch_size,seq_len,hidden_size*2]
self.va=nn.Parameter(torch.FloatTensor(encoder_outputs.size(1),hidden_size*2))#[batch_size,hidden_size*2]
# print("tanhed size",tanhed.size(),self.va.unsqueeze(2).size())
attr=tanhed.bmm(self.va.unsqueeze(2))# [batch_size,seq_len,1]
context=attr.permute(0,2,1).bmm(encoder_outputs.permute(1,0,2))# [batch_size,1,seq_len]
return context,attr
三者训练结果对比
文字太多存不下,放到另外一篇文章了,链接是:https://mp.csdn.net/mp_blog/creation/success/139053790
总结
- 将线性变换设置bias为True的时候,收敛会变快
- 之前学习率设置是0.001,然后改为0.05后,起始loss变为1.xxxx,4000次迭代loss就达到了0.00x
完整代码
参见链接https://blog.csdn.net/m0_60688978/article/details/139053661
参考
https://blog.csdn.net/m0_60688978/article/details/139044526