1 nn.functional.one_hot
torch.nn.functional.one_hot(tensor, num_classes=-1) 接收一个包含索引值的 LongTensor,形状为(),并返回一个形状为(, num_classes)的张量,该张量在所有位置都是零,除了在输入张量对应值的索引位置处为1。
| tensor | (LongTensor) – 任何形状的类别值 |
| num_classes | (int) – 总类别数。如果设置为-1,则类别数将被推断为输入张量中最大类别值加一。 num_classes必须比tensor中出现的数字多,否则会报错
|
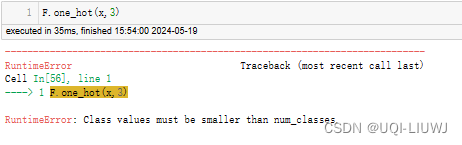
import torch.nn.functional as F
x=torch.arange(5)
F.one_hot(x)
'''
tensor([[1, 0, 0, 0, 0],
[0, 1, 0, 0, 0],
[0, 0, 1, 0, 0],
[0, 0, 0, 1, 0],
[0, 0, 0, 0, 1]])
'''2 扩展
以上面的张量为例,现在我希望0~4中,0~4还是one-hot,5是全0。
def custom_one_hot(indices, num_classes):
one_hot = torch.zeros(indices.size() + torch.Size([num_classes - 1]), dtype=torch.int32)
#这一步创建一个全零的张量,其形状是输入indices的形状加上一个额外的维度
#这个额外维度的大小是num_classes - 1
# 将对应位置设置为1
mask = indices < (num_classes - 1)
#创建一个掩码(mask),这个掩码表示所有indices中的值小于num_classes - 1的位置'
#False的位置即padding的位置,也即全0
one_hot[mask, indices[mask]] = 1
#每一个非padding的元素(值为indices[mask]),对应的indices[mask]位为1,其他位为0
return one_hotcustom_one_hot(x,4)
'''
tensor([[1, 0, 0],
[0, 1, 0],
[0, 0, 1],
[0, 0, 0],
[0, 0, 0]], dtype=torch.int32)
'''