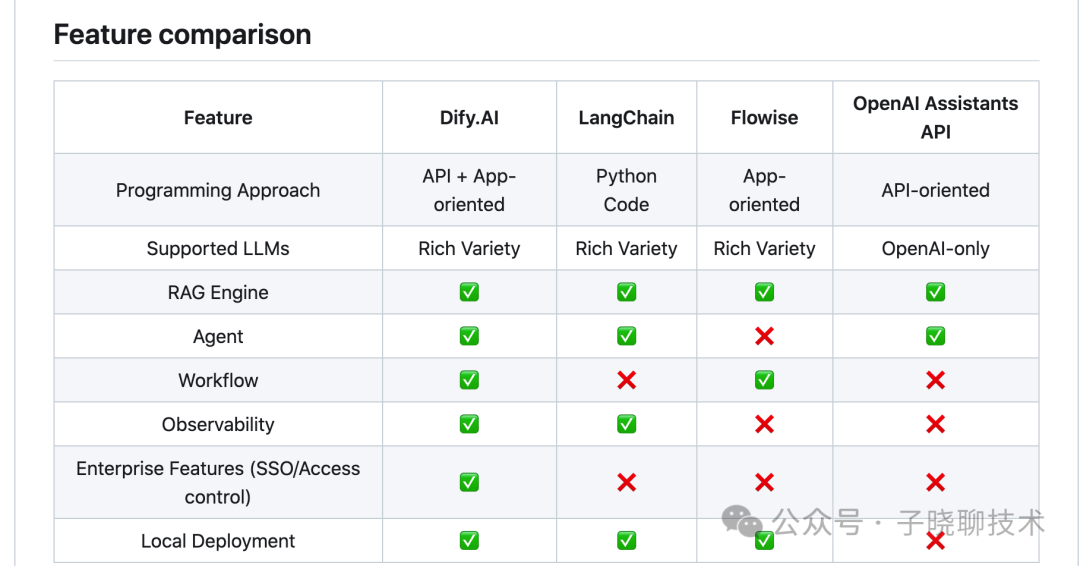
场景:由于系统函数无法满足实际开发需求,需要通过自定义函数来实现
示例:
package spark
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, LongType, StructField, StructType}
object TestSparkUdf {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("student")
.master("local[2]")
.getOrCreate()
import spark.implicits._
val rdd2 = spark.sparkContext.makeRDD(Array(Student2(18, "one"), Student2(20, "two")))
rdd2.toDF().registerTempTable("student")
spark.udf.register("myupper", myUpper _)
val df = spark.sql("select myupper(name) from student")
df.show()
// +-----------------+
// |UDF:myupper(name)|
// +-----------------+
// | ONE|
// | TWO|
// +-----------------+
spark.udf.register("myavg", new myAvg())
val df2 = spark.sql("select myavg(age) from student")
df2.show()
// +----------+
// |myavg(age)|
// +----------+
// | 19|
// +----------+
spark.stop()
}
//udf函数 一对一
def myUpper(str: String): String = str.toUpperCase()
}
//case class Student(id: String, name:String)
class myAvg extends UserDefinedAggregateFunction {
//输入数据的结构
override def inputSchema: StructType = StructType(Array(StructField("age", LongType)))
//缓冲区的数据结构
override def bufferSchema: StructType = StructType(Array(StructField("total", LongType), StructField("count", LongType)))
//函数计算结果的数据类型
override def dataType: DataType = LongType
//函数的稳定性
override def deterministic: Boolean = true
//缓冲区的初始化
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0L;
buffer(1) = 0L;
}
//新数据过来,如何更新缓冲区
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer.update(0, buffer.getLong(0) + input.getLong(0))
buffer.update(1, buffer.getLong(1) + 1)
}
//多个缓冲区数据合并
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1.update(0, buffer1.getLong(0) + buffer2.getLong(0))
buffer1.update(1, buffer1.getLong(1) + buffer2.getLong(1))
}
//计算操作结果
override def evaluate(buffer: Row): Any = {
buffer.getLong(0) / buffer.getLong(1)
}
}
case class Student2(age: Long, name: String)