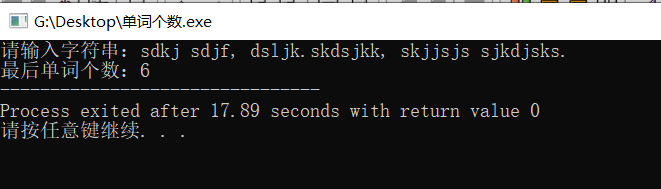
在 MySQL 的 utf8 字符集中(也被称为 utf8mb3),中文字符实际上并不是用2个字节来表示的,而是使用3个字节。这是 UTF-8 编码的一个特性,它使用1到4个字节来表示一个字符,具体取决于字符的 Unicode 码点。
对于中文字符,大部分位于 Unicode 的基本多文种平面(BMP)内,这些字符在 UTF-8 编码中通常使用3个字节。
如果你想要统计某个字段中中文字符的数量,但希望按照每个中文字符占用2个字节来计算(尽管这在 utf8 字符集中是不准确的),你将需要使用一些特殊的 SQL 函数和逻辑。但是,由于 SQL 本身并不直接支持这样的统计,你可能需要编写一些额外的代码或逻辑来实现这一点。
然而,如果你只是想要计算字符串的长度(以字符为单位,而不是字节),你可以使用 CHAR_LENGTH() 或 LENGTH(column_name) COLLATE utf8_general_ci(对于区分大小写的比较)函数。这些函数会返回字符串中的字符数,而不是字节数。
如果你确实需要按照每个中文字符占用2个字节的假设来进行统计(尽管这不准确),你可能需要在应用层面进行这样的计算,而不是在 SQL 查询中。例如,你可以使用某种编程语言来读取数据库中的字符串,然后遍历每个字符,检查它是否是一个中文字符,并根据你的假设来计算总字节数
但请注意,这种方法并不准确,因为它没有考虑到 UTF-8 编码的实际字节使用情况。在大多数情况下,最好直接使用 UTF-8 编码的实际字节长度,或者使用 utf8mb4 字符集来支持所有 Unicode 字符。
在MySQL中,直接使用SQL语句来按照“中文两个字节”的假设来计算字符串长度是不可能的,因为MySQL的内置函数如LENGTH()和CHAR_LENGTH()都是基于实际的字节长度和字符数量来计算的。但是,你可以使用存储过程或自定义函数来模拟这个逻辑。
不过,由于MySQL本身不支持在SQL层面直接处理字符的Unicode范围来区分中文字符和其他字符,所以我们需要一种近似的方法。以下是一个简化的方法,它使用MySQL的字符串函数来尝试区分中文字符(注意这种方法并不完美,因为中文字符的范围在Unicode中更为复杂):
使用REGEXP_REPLACE函数(在MySQL 8.0及以上版本中可用)来替换所有中文字符为一个占位符(比如#),每个中文字符替换为一个占位符。
计算替换后的字符串长度,并减去原始字符串中非中文字符的长度,得到的中文字符数量乘以2(按照你的假设)。
将上一步得到的结果加上原始字符串中非中文字符的长度(每个字符按1个字节计算)。
但是,由于MySQL的REGEXP_REPLACE函数不支持直接计算替换的次数,我们需要一种变通的方法。以下是一个简化的示例,它可能无法完全准确地按照你的假设来计算长度,但可以作为一个起点:
sql
DELIMITER //
CREATE FUNCTION CalculateLengthAssumingChinese2Bytes(input_str VARCHAR(255))
RETURNS INT
BEGIN
DECLARE chinese_chars_replaced INT DEFAULT 0;
DECLARE non_chinese_length INT;
DECLARE result_length INT;
-- 假设这里我们只替换常见的中文字符范围(并不完整)
SET @replaced_str = REGEXP_REPLACE(input_str, '[\x{4e00}-\x{9fa5}]', '#', 1, 0, 'c');
-- 这里我们只是简单地通过比较长度来估算被替换的中文字符数量
-- 注意:这并不准确,因为有些非中文字符也可能被意外替换
SET chinese_chars_replaced = CHAR_LENGTH(input_str) - CHAR_LENGTH(@replaced_str);
-- 计算非中文字符的长度(按1个字节计算)
SET non_chinese_length = LENGTH(input_str) - (chinese_chars_replaced * 3); -- 假设中文字符原本占3个字节
-- 计算结果长度(按照中文两个字节的假设)
SET result_length = (chinese_chars_replaced * 2) + non_chinese_length;
RETURN result_length;
END //
DELIMITER ;
注意:
这个函数只是一个简化的示例,它可能无法准确地处理所有情况。
中文字符的Unicode范围比[\x{4e00}-\x{9fa5}]要广泛得多,这个范围只包含了常用的中文字符。
在实际应用中,你可能需要根据你的具体需求来调整这个函数。
如果你的MySQL版本不支持REGEXP_REPLACE函数,你将需要使用其他方法或升级到支持该函数的版本。
![<span style='color:red;'>字符</span><span style='color:red;'>统计</span>[c]](https://img-blog.csdnimg.cn/direct/1f73b4af769f462a860f4ab23023f0be.png)