python爬虫(五)之新出行汽车爬虫
接完最后一单,终于肝完了最后一个python爬虫——新出行爬虫,将https://www.xchuxing.com网站上所有的汽车爬虫全部抓取下来。
import requests
import json
import csv
from lxml import etree
import time
class Xchuxing:
def __init__(self):
self.article_list_pre_url = "https://www.xchuxing.com/official?category=1&page="
self.start_page = 1
self.end_page = 1000
self.payload = {}
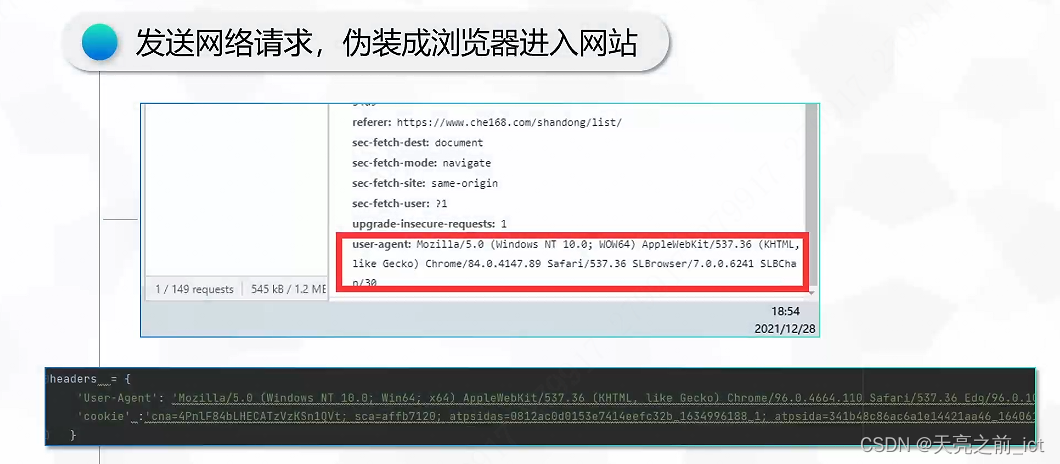
self.article_list_headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Cookie': 'community_new_sort=22af645d1859cb5ca6da0c484f1f37ea; Hm_lvt_55f107d825a4c4e989d543a8bf935508=1710252997; Hm_lpvt_55f107d825a4c4e989d543a8bf935508=1710253296',
'Referer': 'https://www.xchuxing.com/official',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24", "Google Chrome";v="122"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"'
}
self.article_detail_headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': 'community_new_sort=22af645d1859cb5ca6da0c484f1f37ea; Hm_lvt_55f107d825a4c4e989d543a8bf935508=1710252997; Hm_lpvt_55f107d825a4c4e989d543a8bf935508=1710255840',
'Referer': 'https://www.xchuxing.com/official',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36',
'sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24", "Google Chrome";v="122"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"'
}
def get_request(self, url, headers):
response = requests.request("GET", url, headers=headers, data=self.payload)
return response.text
def do_work(self):
with open('新出行.csv', 'w', newline='', encoding='utf-8-sig') as file:
writer = csv.writer(file)
csv_title = ["标题", "作者", "发布时间", "正文"]
writer.writerow(csv_title)
for current_page in range(self.start_page, self.end_page):
print("================> 当前第" + str(current_page) + "页,共" + str(self.end_page) + "页 ============")
article_list_url = self.article_list_pre_url + str(current_page)
text = self.get_request(article_list_url, headers=self.article_list_headers)
data = json.loads(text)["data"]
self.write_page(writer, data)
def write_page(self, writer, data):
for item in data:
# print(item["title"])
# print(item["author"]["username"])
# print(item["created_at"])
# 获取文章详情内容
# https://www.xchuxing.com/article/116378
article_url = "https://www.xchuxing.com/article/" + str(item["object_id"])
text = self.get_request(article_url, headers=self.article_detail_headers)
html = etree.HTML(text)
result = html.xpath("normalize-space(//div[@class='content-main']/div[5])")
# print(result)
time_struct = time.localtime(item["created_at"])
date = time.strftime("%Y-%m-%d %H:%M:%S", time_struct)
row = [item["title"], item["author"]["username"], date, result]
writer.writerow(row)
print("===========> 当前文章 " + article_url + " 写入完毕", )
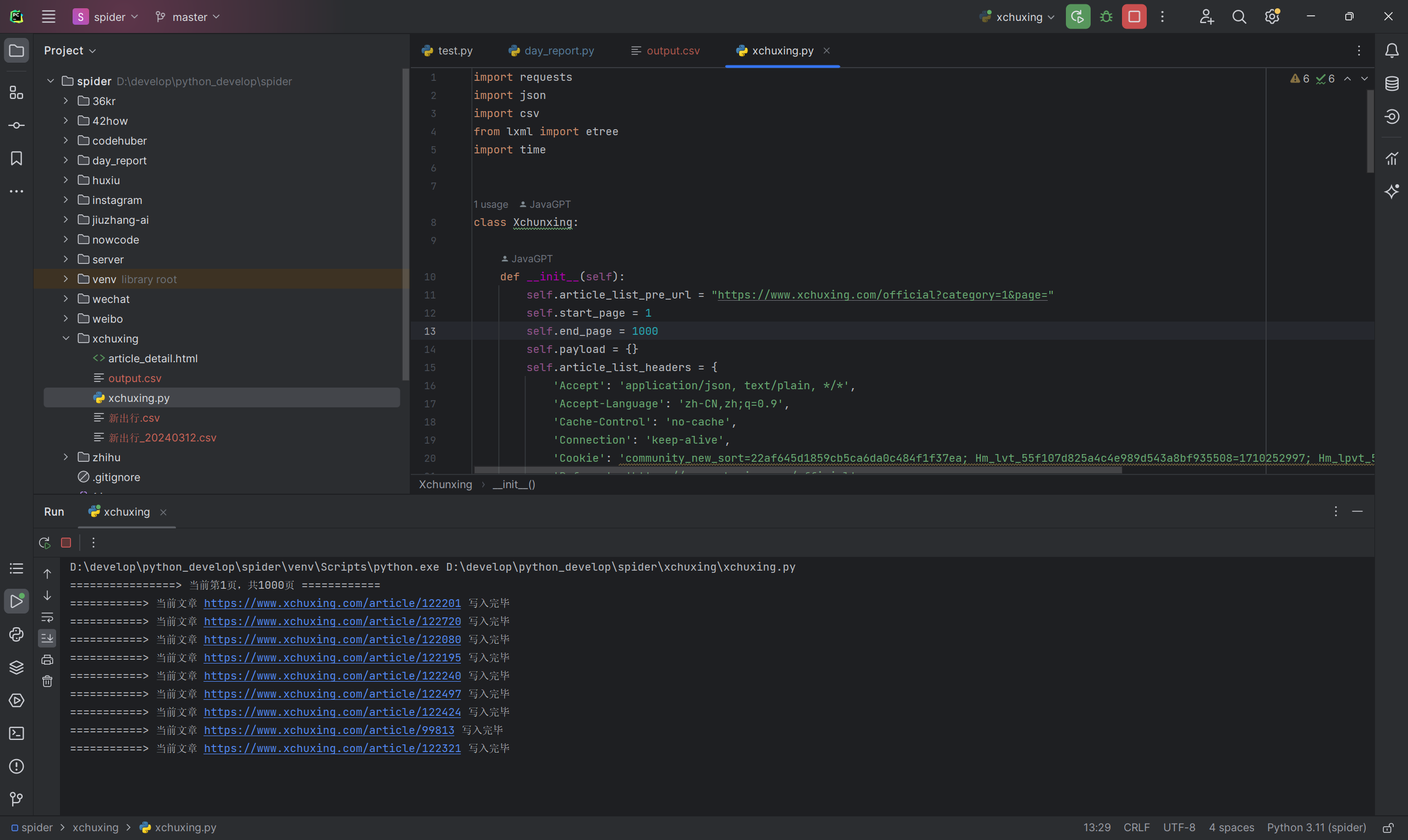
if __name__ == '__main__':
xchuxing = Xchuxing()
xchuxing.do_work()
运行结果:
写在最后
代码精选(www.codehuber.com),程序员的终身学习网站已上线!
如果这篇【文章】有帮助到你,希望可以给【JavaGPT】点个赞👍,创作不易,如果有对【后端技术】、【前端领域】感兴趣的小可爱,也欢迎关注❤️❤️❤️ 【JavaGPT】❤️❤️❤️,我将会给你带来巨大的【收获与惊喜】💝💝💝!