在计算机科学中,树是一种抽象数据类型(ADT)或是实现这种抽象数据类型的数据结构,用来模拟具有树状结构性质的数据集合。这种数据结构以一系列连接的节点来形成树形结构。在C++中,树的概念和存储结构是实现各种复杂算法和数据操作的基础。
树是由节点和边组成的图,其中每个节点有零个或多个子节点,但只有一个父节点(除了根节点,它没有父节点)。树的顶部节点称为根节点。如果一个节点没有子节点,那么它被称为叶子节点。除了根节点和叶子节点之外的其他节点称为内部节点。由树的根节点和若干棵子树所构成的树称为森林。如下图所示。
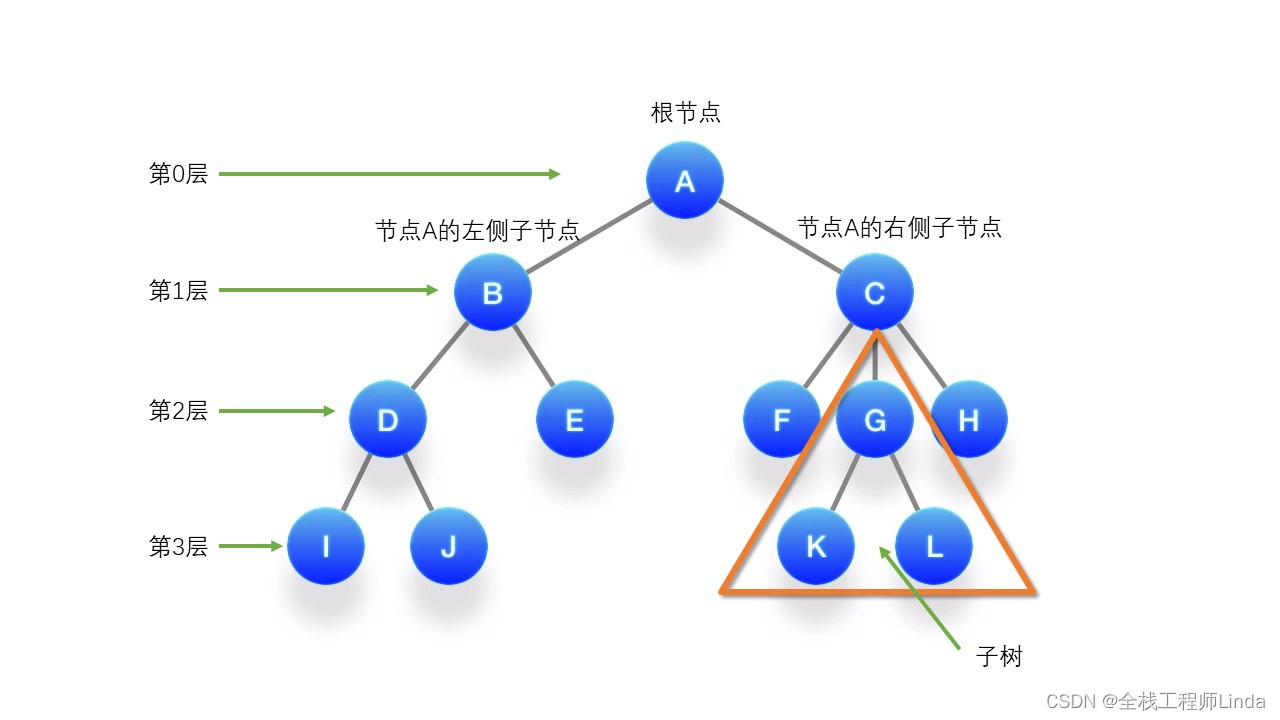
树的术语:
(1)路径:在两个节点之间,一系列的边和节点的组合。路径的长度是组成路径的边数。
(2)深度:一个节点的深度是指从根节点到该节点的最长路径上的边数。根节点的深度为0。
(3)层次:树的层次从根开始定义,根为第一层,根的子节点为第二层,以此类推。
(4)高度:树的高度是从叶子节点开始自底向上逐层累加的路径上边的数量。根节点的高度就是树的高度。
在C++中,树的存储结构主要有两种:顺序存储和链式存储。不同的存储结构对应着不同的表示方法,如孩子表示法、双亲表示法、孩子兄弟表示法等。
1. 顺序存储:顺序存储通常用于完全二叉树。在完全二叉树中,除了最后一层外,其他层的节点数是满的,并且最后一层的节点都靠左排列。这种特性使得完全二叉树可以使用数组进行顺序存储,其中每个节点的索引与其在树中的位置相关。
示例:创建一棵简单的完全二叉树,代码如下。
#include <iostream>
#include <vector>
using namespace std;
class TreeNode {
public:
int value;
TreeNode* left;
TreeNode* right;
TreeNode(int x) : value(x), left(nullptr), right(nullptr) {}
};
class BinaryTree {
private:
vector<TreeNode*> nodes;
public:
// 初始化树的根节点
void initRoot(int value) {
nodes.push_back(new TreeNode(value));
}
// 添加子节点
void addChild(int parentIndex, int leftChildValue, int rightChildValue) {
int nextEmptyIndex = nodes.size();
if (leftChildValue != -1) {
nodes.push_back(new TreeNode(leftChildValue));
nodes[parentIndex]->left = nodes[nextEmptyIndex];
}
if (rightChildValue != -1) {
nodes.push_back(new TreeNode(rightChildValue));
nodes[parentIndex]->right = nodes[nextEmptyIndex + (leftChildValue != -1)];
}
}
// 示例:创建一棵简单的完全二叉树
void createExampleTree() {
initRoot(1);
addChild(0, 2, 3);
addChild(1, 4, 5);
addChild(2, 6, -1);
addChild(3, 7, 8);
}
// 其他操作,如遍历、查找等...
};链式存储:链式存储通过节点和指针来表示树中的关系。每个节点包含数据域和指向其子节点的指针域。链式存储方式更加灵活,适用于各种类型的树。
示例一:使用孩子表示法创建树,代码如下。
class TreeNode {
public:
int value;
vector<TreeNode*> children;
TreeNode(int x) : value(x) {}
};
// 使用孩子表示法创建树
TreeNode* createTree() {
TreeNode* root = new TreeNode(1);
TreeNode* node2 = new TreeNode(2);
TreeNode* node3 = new TreeNode(3);
TreeNode* node4 = new TreeNode(4);
TreeNode* node5 = new TreeNode(5);
root->children.push_back(node2);
root->children.push_back(node3);
node2->children.push_back(node4);
node2->children.push_back(node5);
return root;
}上述代码展示了如何使用孩子表示法来创建一个树,其中每个节点都有一个指向其子节点的指针列表。这种方式可以很直观地表示一个节点的所有子节点,但是在查找父节点时不够高效,因为父节点的信息并未存储在当前节点中。
在双亲表示法中,每个节点不仅包含数据域和指向其子节点的指针,还包含一个指向其父节点的指针。这使得我们可以方便地访问一个节点的父节点,但可能需要额外的空间来存储父节点的指针。
示例二:使用双亲表示法创建树,代码如下:
class TreeNode {
public:
int value;
TreeNode* parent; // 指向父节点的指针
vector<TreeNode*> children; // 子节点列表
TreeNode(int x) : value(x), parent(nullptr) {}
};
// 使用双亲表示法创建树
void createTreeWithParent(TreeNode*& root) {
root = new TreeNode(1); // 根节点的父节点为null
TreeNode* node2 = new TreeNode(2);
TreeNode* node3 = new TreeNode(3);
TreeNode* node4 = new TreeNode(4);
TreeNode* node5 = new TreeNode(5);
node2->parent = root;
node3->parent = root;
node4->parent = node2;
node5->parent = node2;
root->children.push_back(node2);
root->children.push_back(node3);
node2->children.push_back(node4);
node2->children.push_back(node5);
}在双亲表示法中,我们可以沿着父节点的指针向上遍历树,直到找到根节点或者到达一个父节点为空的节点。这种表示法在需要频繁进行父子节点关系查询时比较有用。
孩子兄弟表示法是一种结合了孩子表示法和双亲表示法的思想的方法。在这种表示法中,每个节点包含指向其第一个孩子节点的指针和指向其下一个兄弟节点的指针。这种表示法对于二叉树非常自然,并且可以很方便地表示任何类型的树。
示例三: 使用孩子兄弟表示法创建树,代码如下:
class TreeNode {
public:
int value;
TreeNode* firstChild; // 指向第一个孩子节点
TreeNode* nextSibling; // 指向下一个兄弟节点
TreeNode(int x) : value(x), firstChild(nullptr), nextSibling(nullptr) {}
};
// 使用孩子兄弟表示法创建树
void createTreeWithChildSibling(TreeNode*& root) {
root = new TreeNode(1);
TreeNode* node2 = new TreeNode(2);
TreeNode* node3 = new TreeNode(3);
TreeNode* node4 = new TreeNode(4);
TreeNode* node5 = new TreeNode(5);
root->firstChild = node2;
node2->nextSibling = node3;
node3->firstChild = node4;
node3->nextSibling = node5;
}在这种表示法中,通过firstChild可以访问到该节点的所有子节点,而通过nextSibling可以遍历该节点的所有兄弟节点。这种方法特别适合处理那些子节点之间没有顺序要求的树结构。
每种存储结构都有其适用的场景和优缺点,例如顺序存储适合表示完全二叉树,而链式存储则更加灵活,能够表示任意结构的树。在实际应用中,需要根据具体需求和树的特点来选择适当的存储结构。
























![[附源码]传世手游_玲珑传世_GM_安卓搭建教程](https://img-blog.csdnimg.cn/img_convert/92b50728b247277e44cf91266788e610.webp?x-oss-process=image/format,png)





![[Linux][网络][高级IO][一][五种IO模型][同步通信][异步通信][非阻塞IO]详细讲解](https://img-blog.csdnimg.cn/direct/99b758c8e1824f2cb48c15575be10424.png)