1.git
总结就一句话:相同版本的合并直接覆盖,不同版本的合并,会有冲突检测。
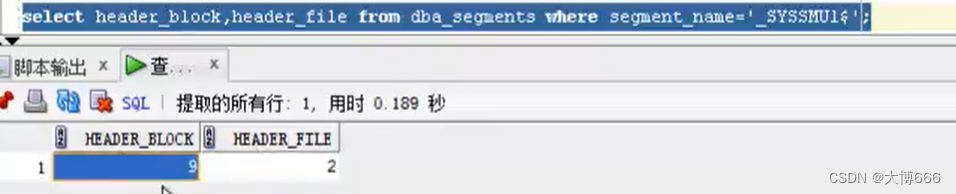
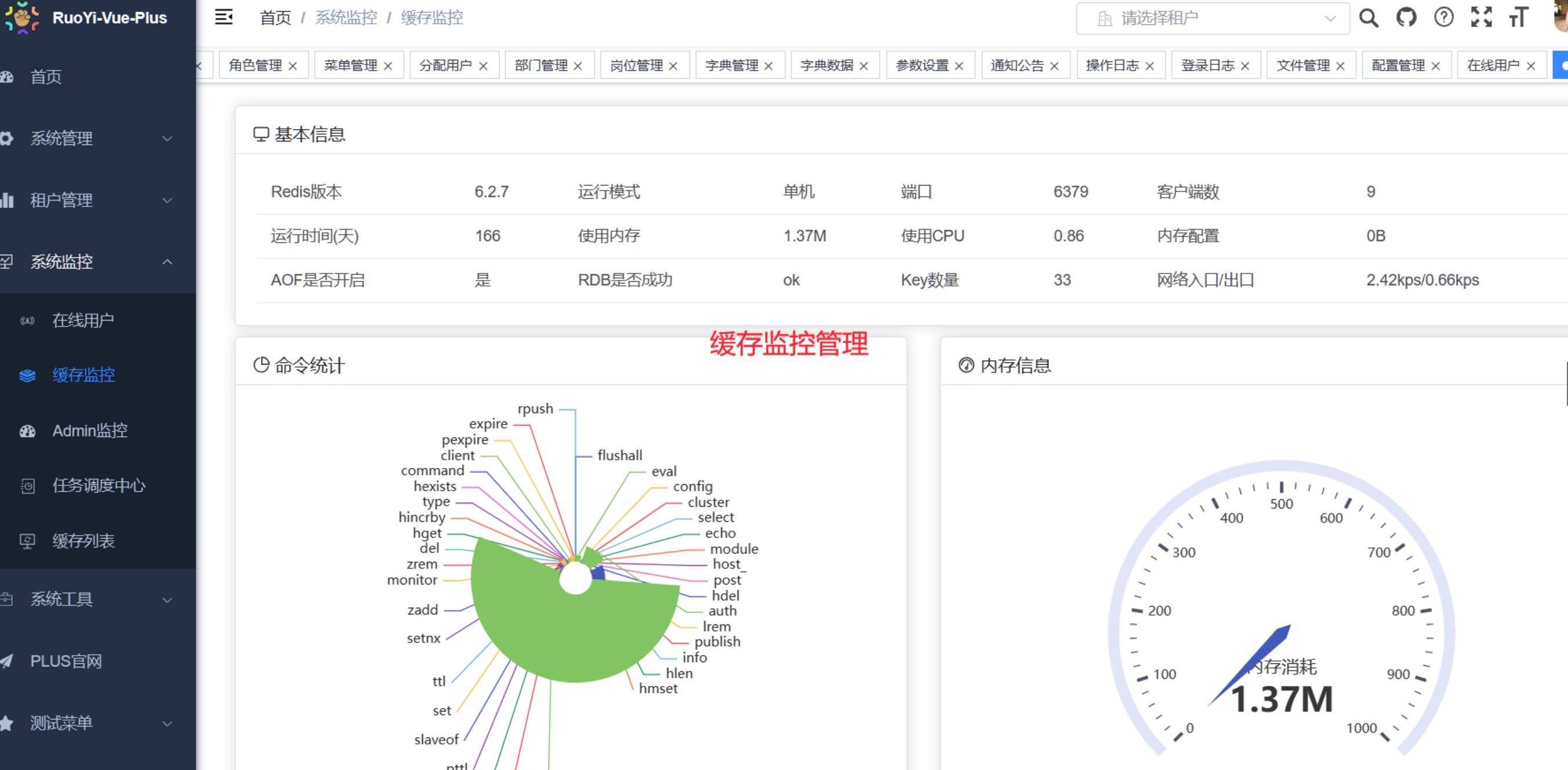
2.事务
事务的内存快照不是所有内存快照直接同步到数据库,而是你修改了哪个内存快照的那条数据,他就会同步哪一条,我的猜测实现原理,是通过版本控制,主分支的版本。首先在提交事务的时候,会先检测事务版本是否与主版本一致,不一致先拉去主版本的数据与事务同步,这时事务的版本就和主版本的一致了,其他提交的事务,也会被一同合并到这条新事务上,最后再将这个事务合并到主版本上,然后提交成一个新版本。这个机制有点像乐观锁,提交这个过程整体肯定是加了锁的,也就是说一次只会有一个事务提交,等上一个事务更新完版本,下一个事务才能拉去版本合并。这是我的理解。
3.隔离级别
读已提交和可重复读。
读已提交和可重复读都是有行锁的,为保证数据一致,只能有一个事务去修改同一行的数据。
但是,在查询方面,可重复读为了实现数据的隔离性,加了更多的锁,使它查询不到其他事务提交后的数据,所以性能方面读已提交更占优势。
如果应用程序的业务逻辑要求事务期间看到的数据保持一致性,可重复读隔离级别可能更适合,尽管可能会带来一些额外的性能开销。因此,在选择隔离级别时,需要根据具体的业务需求来权衡性能和一致性之间的关系。