OceanBase 提供了一套参数,实现对并行执行功能的初始化和调优。
在OceanBase 的启动过程中,系统会根据租户的 CPU 数量和特定的配置项 px_workers_per_cpu_quota 来自动计算出默认的并行执行控制参数。当然,用户也可以选择不采用这些默认值,而是在启动时手动指定所需的参数值,也根据实际场景的调整,在后续阶段手动调整这些参数值。并行执行在 OceanBase 中是默认启用的。
这篇博客会从并行执行默认参数和相关参数调优这两个方面,来讲解并行执行参数控制的技巧。
并行执行系列的内容分为七篇博客,本篇是其中的第五篇。
| 一 | 并行执行概念 |
| 二 | 如何手动设置并行度 |
| 三 | 并行执行线程资源管理方式 |
| 四 | 并行执行的4种类别 |
5.1 并行执行默认参数
并行执行的参数能够控制并行线程数、并行执行排队等行为。具体总结为下表:
| 参数名称 | 默认值 | 级别 | 说明 |
| px_workers_per_cpu_quota | 10 | 租户级配置项 | 每个 CPU 上可以分配的并行执行线程数,取值范围 [1,20] |
| parallel_servers_target | MIN CPU * px_workers_per_cpu_quota | 租户级变量 | 表示租户在每个节点上可申请的并行执行线程数量。 |
| parallel_degree_policy | MANUAL | 租户级/Session级变量 | 自动 DOP 开启开关,当设置为 AUTO 时,会开启自动 DOP,优化器根据统计信息自动计算 Query 的并行度。当设置为 MANUAL 时,根据 HINT、TABLE PARALLEL 属性、SESSION 级 DOP 等控制并行度。 |
| _parallel_max_active_sessions | 0 | 租户级配置项 | TPCH 测试中,Power Run 需要的并行度比较高, Throughput Run 需要的并行度比较低。但是,TPCH 测试规范不允许通过 SQL 来动态更改并行度。为了达到动态更改并行度的目的,增加一个配置项 _parallel_max_active_sessions (pmas)当 pmas 等于 0 时,并行执行的活跃 session 数不受限制;当 pmas 大于 0 时,当前并行执行最大活跃 session 数会限制在 pmas 值以下,其它并行执行 session 线程会被挂起,等待被唤醒。某个 query 执行成功后,会唤醒它们尝试继续执行。 |
OceanBase 为了降低用户使用并行执行的门槛,将并行执行参数个数降到了最低,使用默认参数即可实现开箱即用。在特殊场景下,用户可以通过改变默认参数实现应用调优。
px_workers_per_cpu_quota
这个参数表示在每个 CPU 上可以分配的并行执行线程数。当分配给租户的 MIN CPU 为 N 时,如果并行负载均匀,那么每个节点上可以分配的线程数为 N * px_workers_per_cpu_quota。如果并行负载访问的数据分布不均匀,那么某些节点上实际分配的线程数会短时间大于 N * px_workers_per_cpu_quota,当负载结束后,这些多分配出来的线程会被自动回收。
px_workers_per_cpu_quota 对 parallel_servers_target 默认值的影响仅仅发生在创建租户时,租户创建完成后,修改 px_workers_per_cpu_quota 值并不会改变 parallel_servers_target 值。
一般情况下,不需要更改 px_workers_per_cpu_quota 的默认值。当未开启资源隔离特性时,如果发生并行执行占用了全部 CPU 资源的情况,可以尝试通过降低 px_workers_per_cpu_quota 参数的值来缓解该问题。
parallel_servers_target
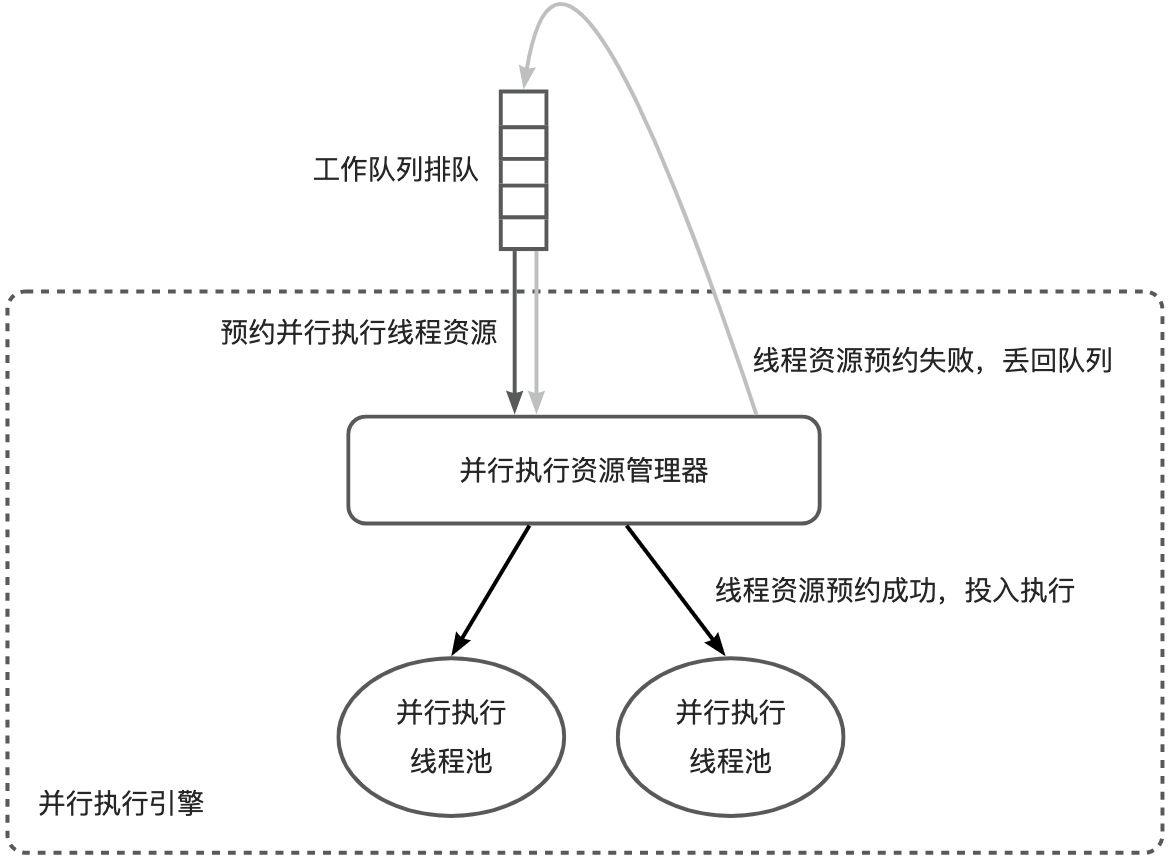
这个参数表示租户在每个节点上可申请的并行执行线程资源数量。当资源耗尽时,并行执行请求需要排队。关于排队的概念,请参考本文中《3 并发控制与排队》一节。
并行执行的 CPU 使用率非常低,可能是因为 parallel_servers_target 值太小,导致 SQL 的 DOP 被降级,实际分配的线程数小于期望的数量。OBServer v3.2.3 版本之前,parallel_servers_target 的默认值非常小,可以通过调大 parallel_servers_target 值来解决,建议设置为 MIN CPU * 10。 OBServer v3.2.3 版本起,parallel_servers_target 的默认值就是 MIN CPU * 10,一般不会遇到这个问题。
MIN CPU 表示租户的 min_cpu 值,一般在创建租户时指定。
设定好 parallel_servers_target 值后,重新连接,执行下面的命令查看最新值:
show variables like 'parallel_servers_target';从运维的角度,如何给 parallel_servers_target 设置一个最大值,避免以后频繁调整呢?理论上,可以将 parallel_servers_target 设置得无穷大,这时会面临一个问题:低效。所有的查询都不排队,它们都开始执行,并争抢 CPU 时间片、争抢磁盘 IO、网络 IO。
从吞吐量的角度看,这个问题不算严重。从单个 SQL 延迟的角度看,这种争抢会严重影响延迟。综合考虑 CPU 和 IO 的利用率,我们可以以租户 UNIT 的 MIN CPU 为基准,一般把 parallel_servers_target 设置为 MIN CPU * 10 即可;少数 IO 密集型场景,CPU 可能用不满,可以将 parallel_servers_target 设置为 MIN CPU * 20。
parallel_degree_policy
这个参数是自动 DOP 开启开关,当设置为 AUTO 时,会开启自动 DOP,优化器根据统计信息自动计算 Query 的并行度。当设置为 MANUAL 时,根据 HINT、TABLE PARALLEL 属性、SESSION 级 DOP 等控制并行度。
OBServer v4.2 起,如果用户不熟悉并行度的设置规则,可以设置 parallel_degree_policy 为 AUTO,让优化器帮忙自动选择并行度。关于自动并行度的计算规则,参考本文的 《2 设定并行度》一节。OBServer v4.2 之前的版本,不支持 parallel_degree_policy 开关,不支持自动 DOP 功能,需要手工设置。
5.2 并行执行相关参数调优
ob_sql_work_area_percentage
租户级变量,用于限制 SQL 模块可以使用的最大内存。它是一个百分值,表示占租户总内存的比值,默认为 5,表示占租户内存的 5%。当 SQL 使用的内存超过限制时,会触发内存落盘。sql work area 内存的实际使用量,可以在 observer.log 日志中搜索 WORK_AREA。例如:
[MEMORY] tenant_id=1001 ctx_id=WORK_AREA hold=2,097,152 used=0 limit=157,286,400读多写少场景下,如果 SQL 模块内存受限导致数据落盘,可以适当增大 ob_sql_work_area_percentage 值。
workarea_size_policy
OceanBase 实现了全局自适应的内存管理,当 workarea_size_policy 设置为 AUTO 时,执行框架会以最优的策略为各个算子(如 HashJoin、GroupBy、Sort 等)分配内存,开启自适应的数据落盘策略。如果 workarea_size_policy 设置为 MANUAL,则用户需要手工设置 _hash_area_size、_sort_area_size。
_hash_area_size
租户级配置项,用于手动指定每个算子的 Hash 算法最大可用内存,默认值为 128MB。超过指定值后,会启用内存落盘功能。对于 Hash 算法相关算子有效,如 Hash Join、Hash Groupby、Hash Distinct 等。一般情况下,不需要修改本配置项,建议 workarea_size_policy 保持为 AUTO。如果认定 Hash 算法中系统自动内存落盘功能不满足业务需要,可以先将 workarea_size_policy 设置为 MANUAL,然后手工指定 _hash_area_size值。
_sort_area_size
租户级配置项,用于手动指定每个算子的 Sort 算法最大可用内存,默认值为 128MB。超过指定值后,会启用内存落盘功能。主要在 Sort 算子中使用。一般情况下,不需要修改本配置项,建议 workarea_size_policy 保持为 AUTO。如果认定 Sort 算法中系统自动内存落盘功能不满足业务需要,可以先将 workarea_size_policy 设置为 MANUAL,然后手工指定 _sort_area_size值。
_px_shared_hash_join
SESSION 级系统变量,用于决定Hash Join 是否采用共享哈希表方式进行优化。默认值为 true,表示默认开启 shared hash join 算法。Hash Join 在并行场景下,每个并行线程都是独立计算 hash 表。考虑到左表使用 Broadcast 重分布方式时,因为所有并行工作线程计算出的哈希表是相同的,所以每台机器只需要构造一个 hash 表,由所有工作线程共享,这样可以提高 CPU Cache 友好性。一般情况下,不需要修改本配置项。
5.3 并行 DML 相关的参数调优
OBServer v4.1 起,如果没有事务要求,向表中导入数据时建议使用 INSERT INTO SELECT 加上旁路导入功能,一次性将数据插入到新表。这种方式既可以缩短导入时间,也可以避免写入太快导致内存不足的问题。