【学习AI-相关路程-工具使用-自我学习-cuda&visco-开发工具尝试-基础样例 (2)】
1、前言
我们之前安装了cuda,但是我们其实是无法直接使用cuda的,还需要编译器,类似前端,供我们输入代码,好让我们可以将思想延伸。
同时也本篇,也是续写上一篇,我们将在本篇安装开发工具,来写一个简单dome,调用cuda平台相关套件,相当hello world。
前文链接:【学习AI-相关路程-工具使用-自我学习-NVIDIA-cuda-工具安装 (1)】
2、环境说明
这里准备安装Visual Studio code 这个工具,可以看到,只用这个工具是支持不同系统的,visual studio,只是支持win下。
下载链接:https://visualstudio.microsoft.com/zh-hans/
当然如果使用运行cuda,还可以使用Python 语言,是使用另一个工具,目前自己刚学到这里,以后要是学了再写文章。
3、总结说明
(1)了解Visual Studio code
一般来说,想编写程序的话,或多或少,都会了解到这个工具,即使没用过,也会听过。更多的可以看文档。
链接文档:https://code.visualstudio.com/docs
如果因为不太好,可以选择一些翻译工具。
(2)装插件和cuda
安装好了编译工具后,就是安装插件工具,因为Visual Studio code本身支持很多,不是一起全部安装的,需要根据自己需求灵活选。
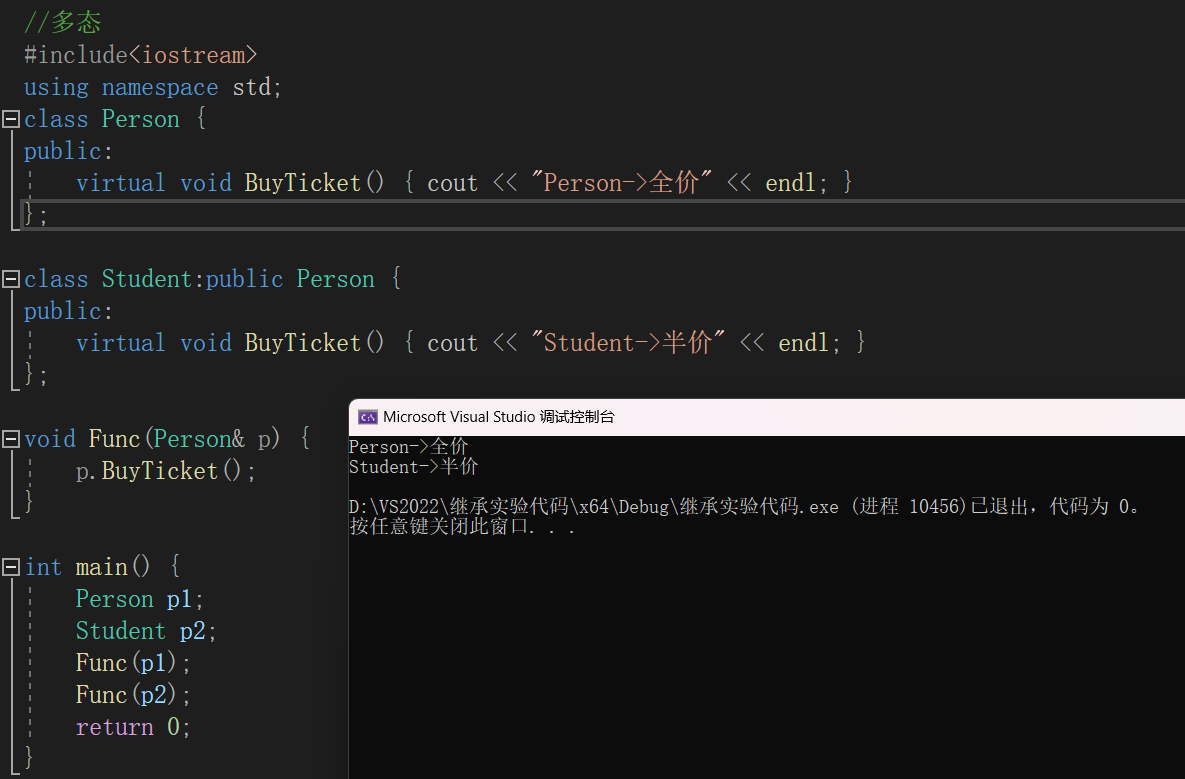
(3)练习代码
最后就是练习一下代码,调用对库,在编译好的软件,运行过程中,就是在使用GPU了。我们通过这个简单样例,来熟悉一下一些库。
4、工具安装
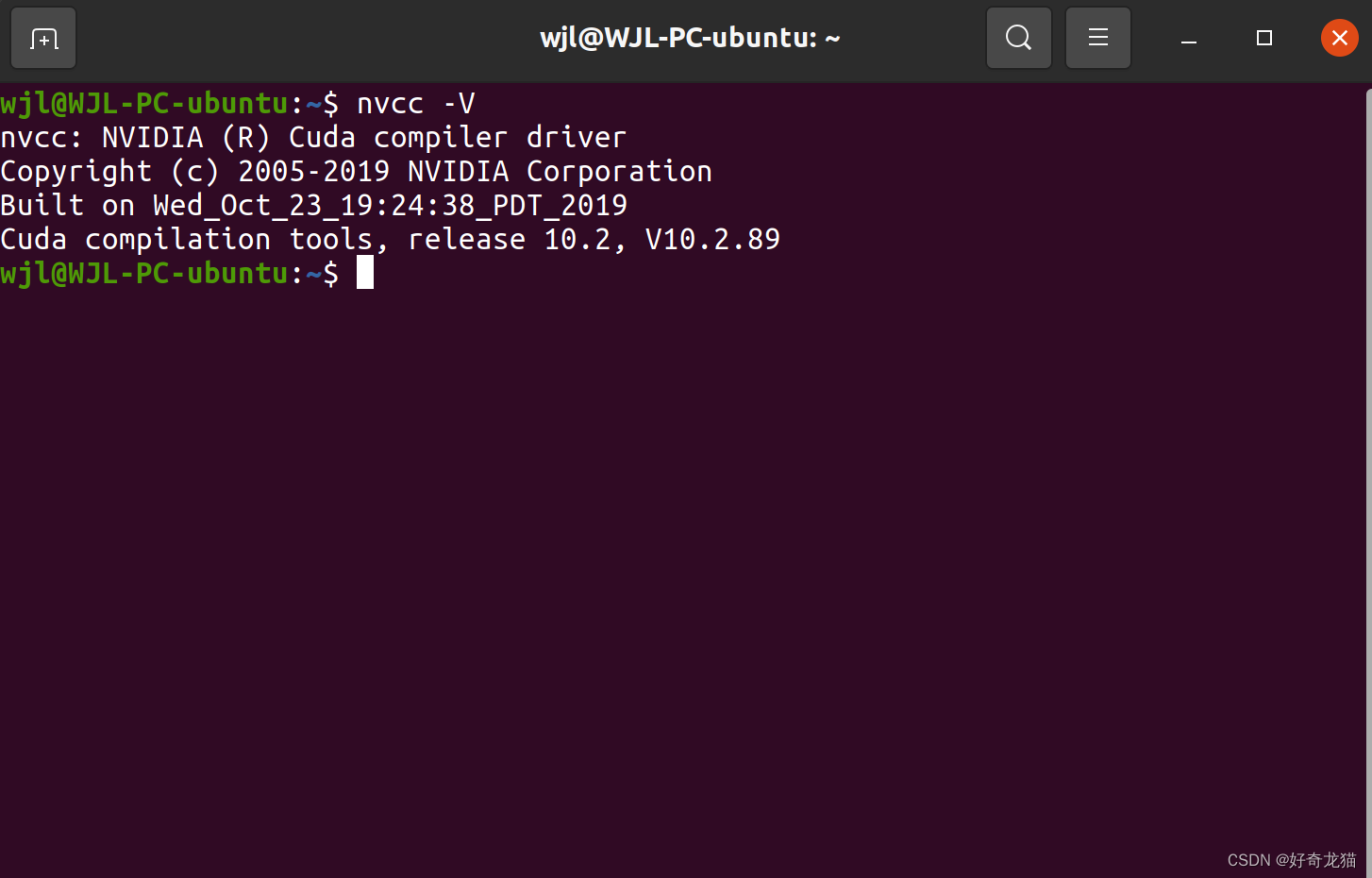
0、验证cuda
使用其他工具前,先要验证下,自己是否已经支持了cuda,或者说是否已经安装了cuda。
nvcc -V
或者
nvcc --version
一般来说安装好后,会出现如下信息。
1、软件下载
如下链接,选择一个自己合适的版本。
下载链接:https://visualstudio.microsoft.com/zh-hans/#vscode-section
安装命令:
sudo dpkg -i code_1.89.0-1714530869_amd64.deb
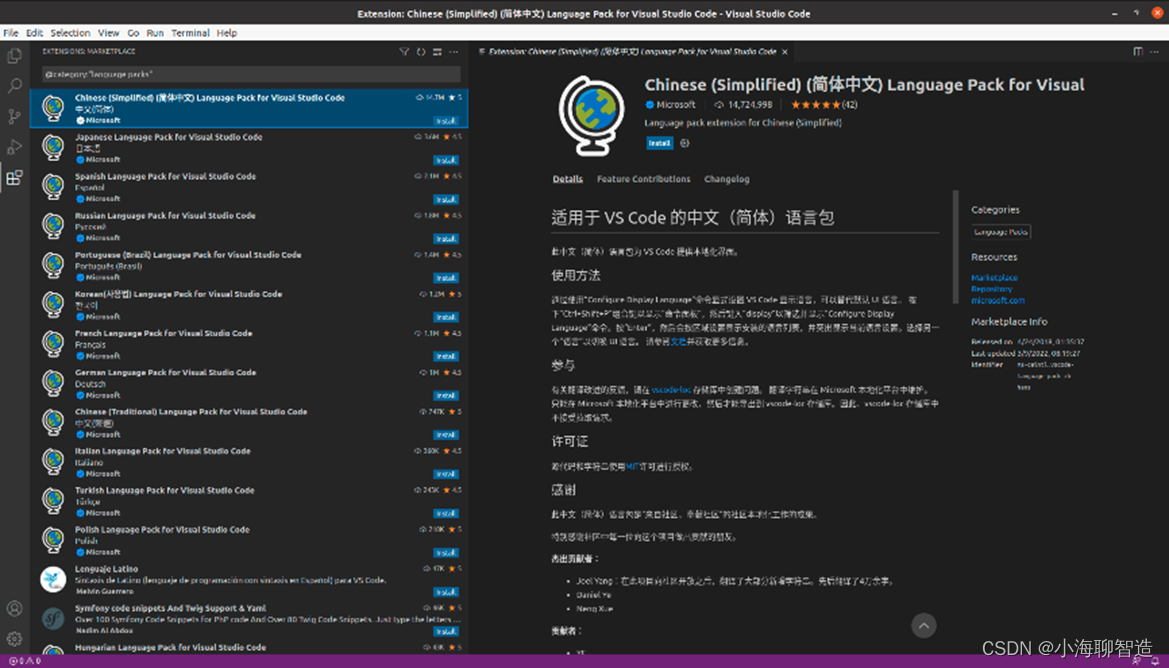
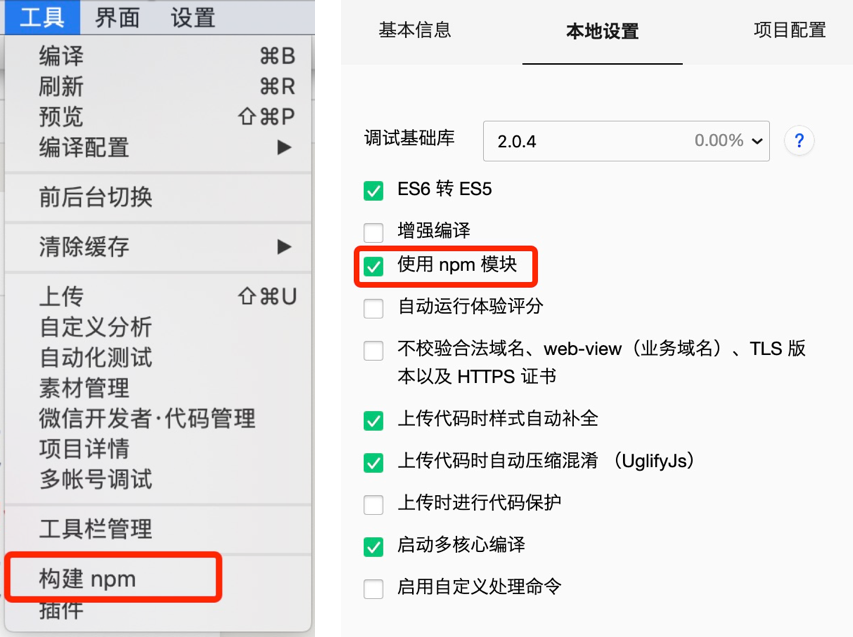
2、插件安装
如下图,我这里编写c/c++语言和cuda,一搜基本就会出来。
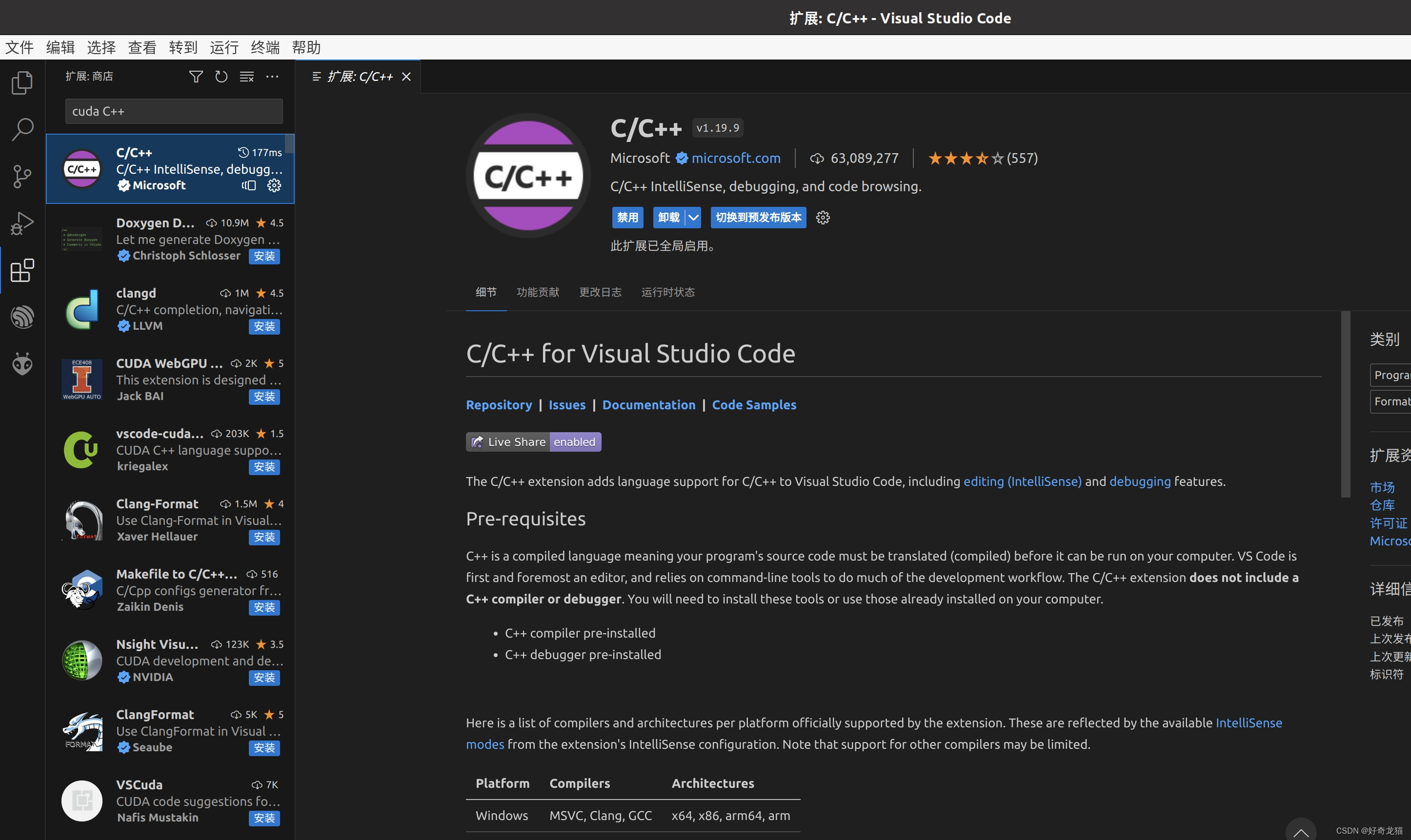
如下是我自己的选择的插件
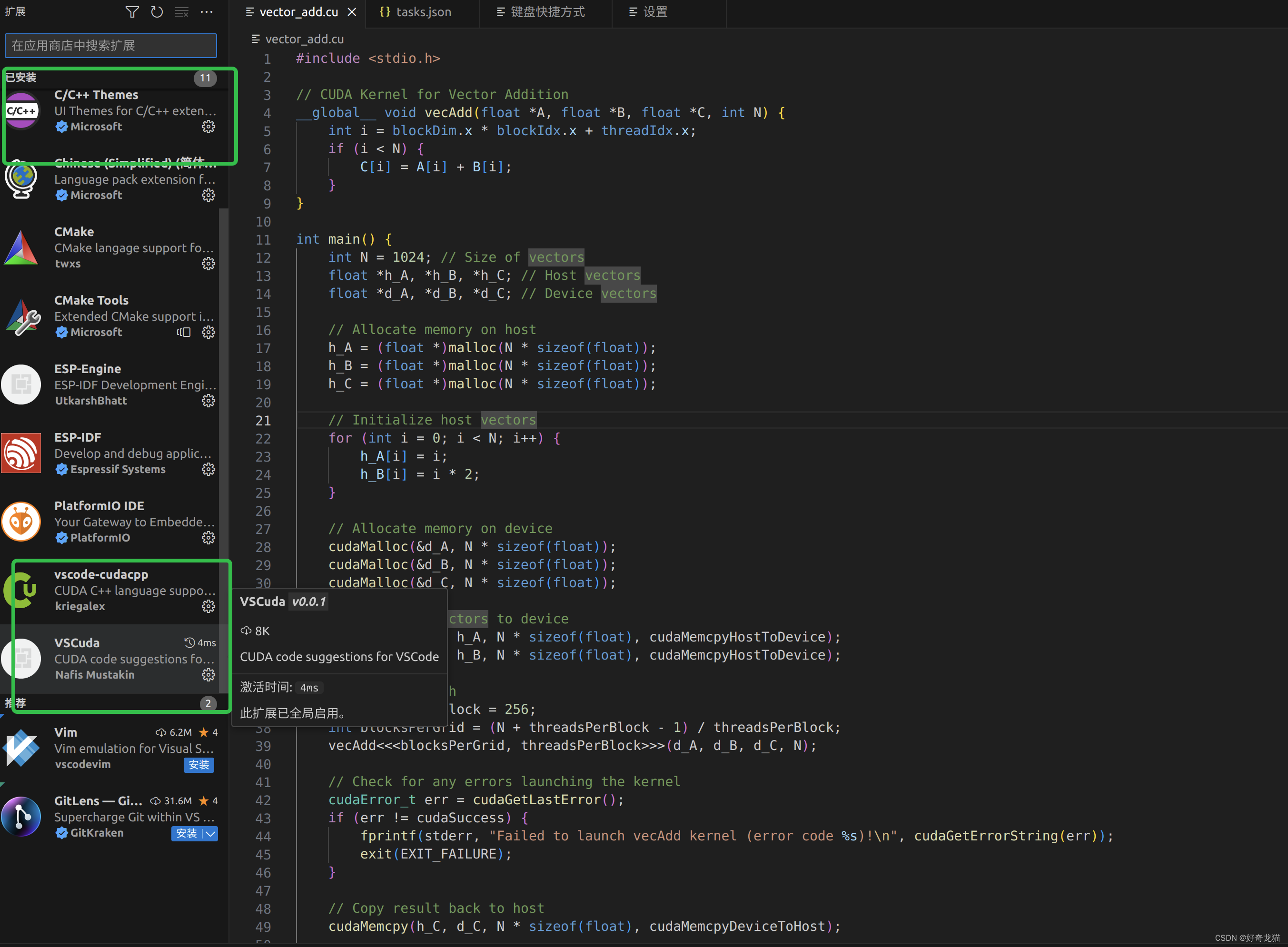
5、软件设置与编程练习
1、创建目录
我们先在桌面创建一个文件夹,自己自己定就好,不必和我一致。
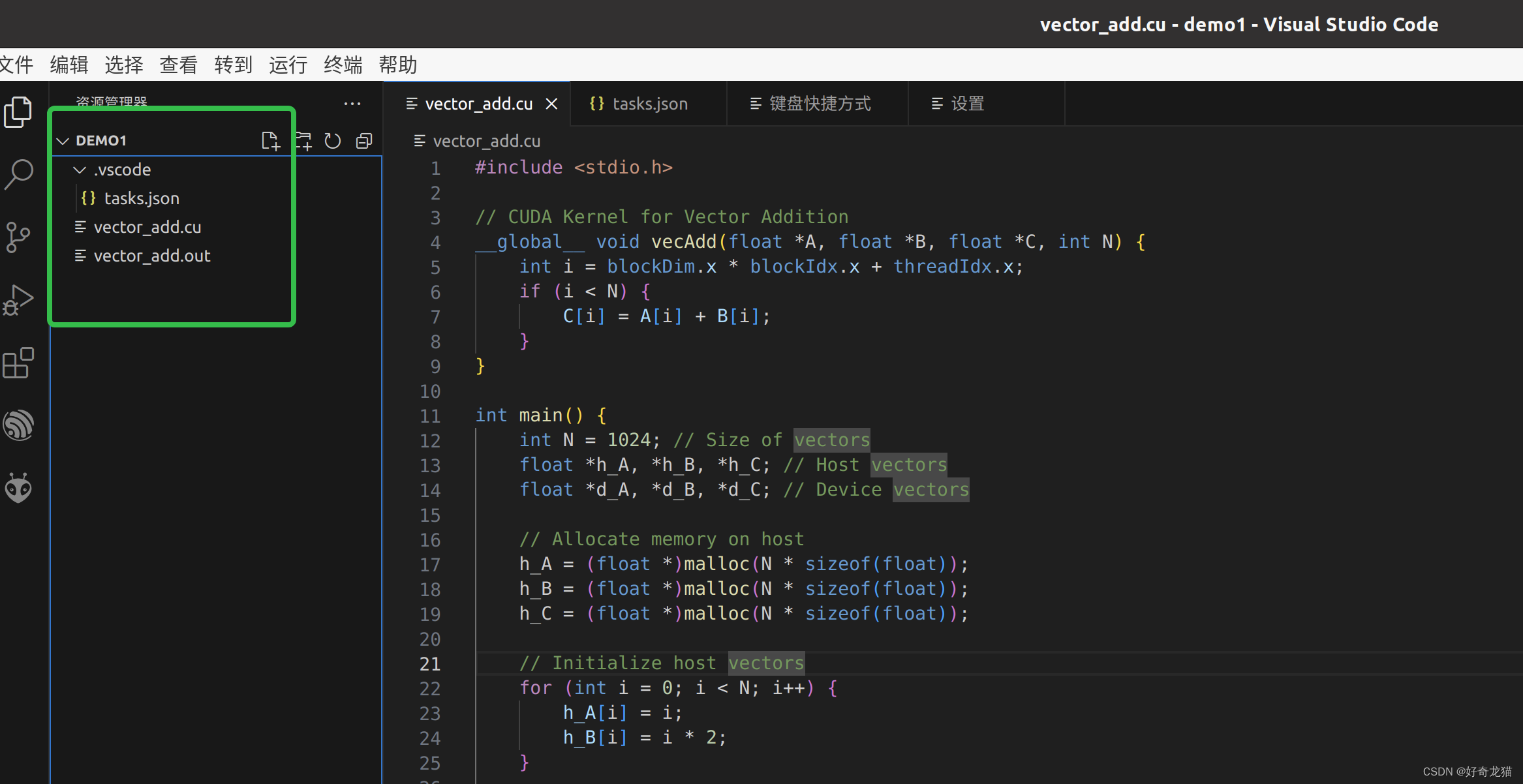
2、编译软件进入目录&创建两个文件
我们用Visual Studio code软件进入对应目录,然后创建两个文件。之后就是准备编写内容了。
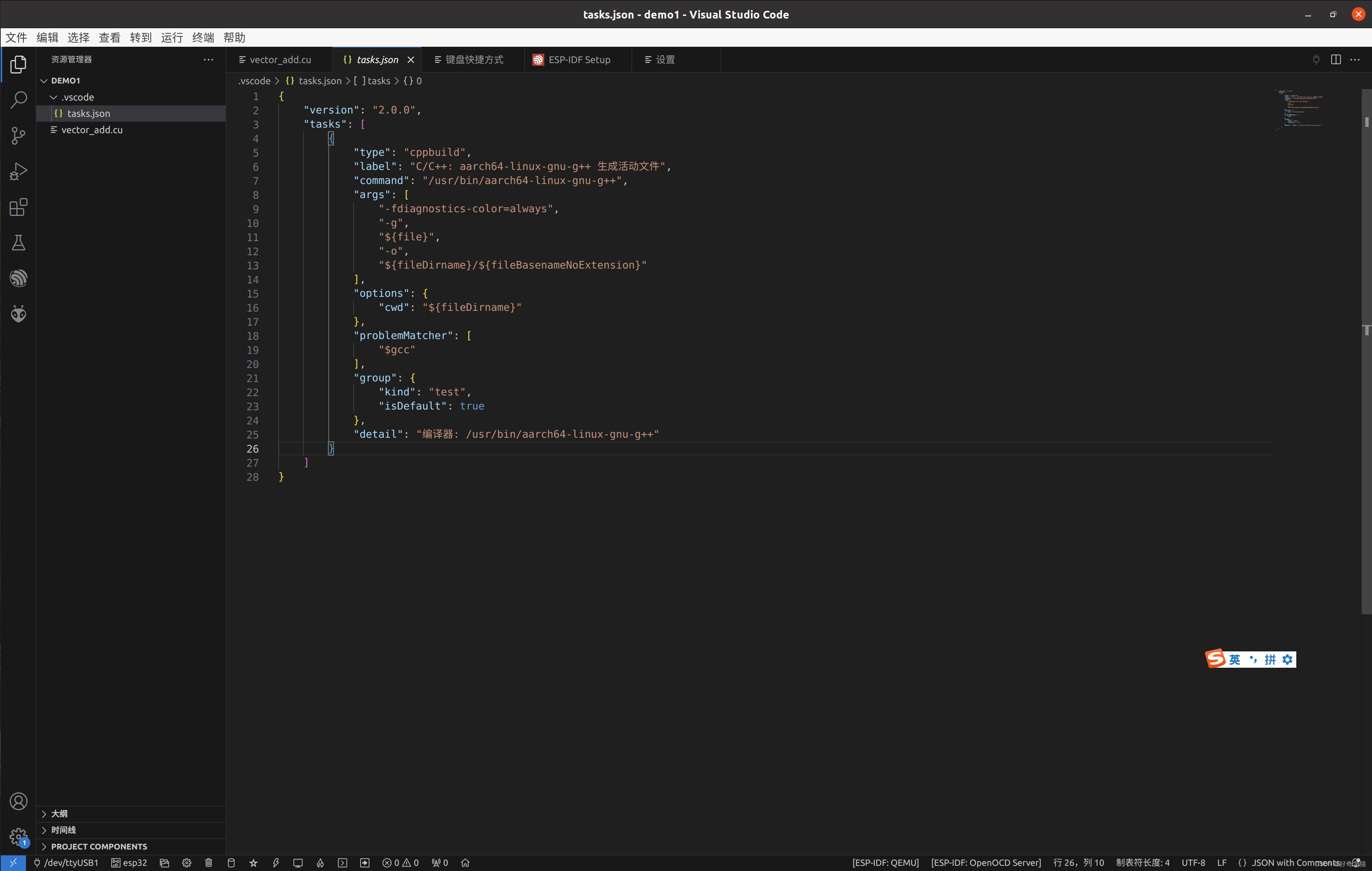
3、编写配置文件
配置文件,顾名思义,就是告诉编译器,去哪里找工具,使用什么工具编译等等配置信息的文件。
{
"version": "2.0.0",
"tasks": [
{
"label": "Build CUDA project",
"type": "shell",
"command": "/usr/local/cuda/bin/nvcc",
"args": [
"-arch=sm_35", // 根据你的GPU架构适当修改
"${file}",
"-o",
"${fileDirname}/${fileBasenameNoExtension}.out"
],
"group": {
"kind": "build",
"isDefault": true
},
"problemMatcher": "$gcc"
}
]
}
如下为截图。
5、编写代码文件
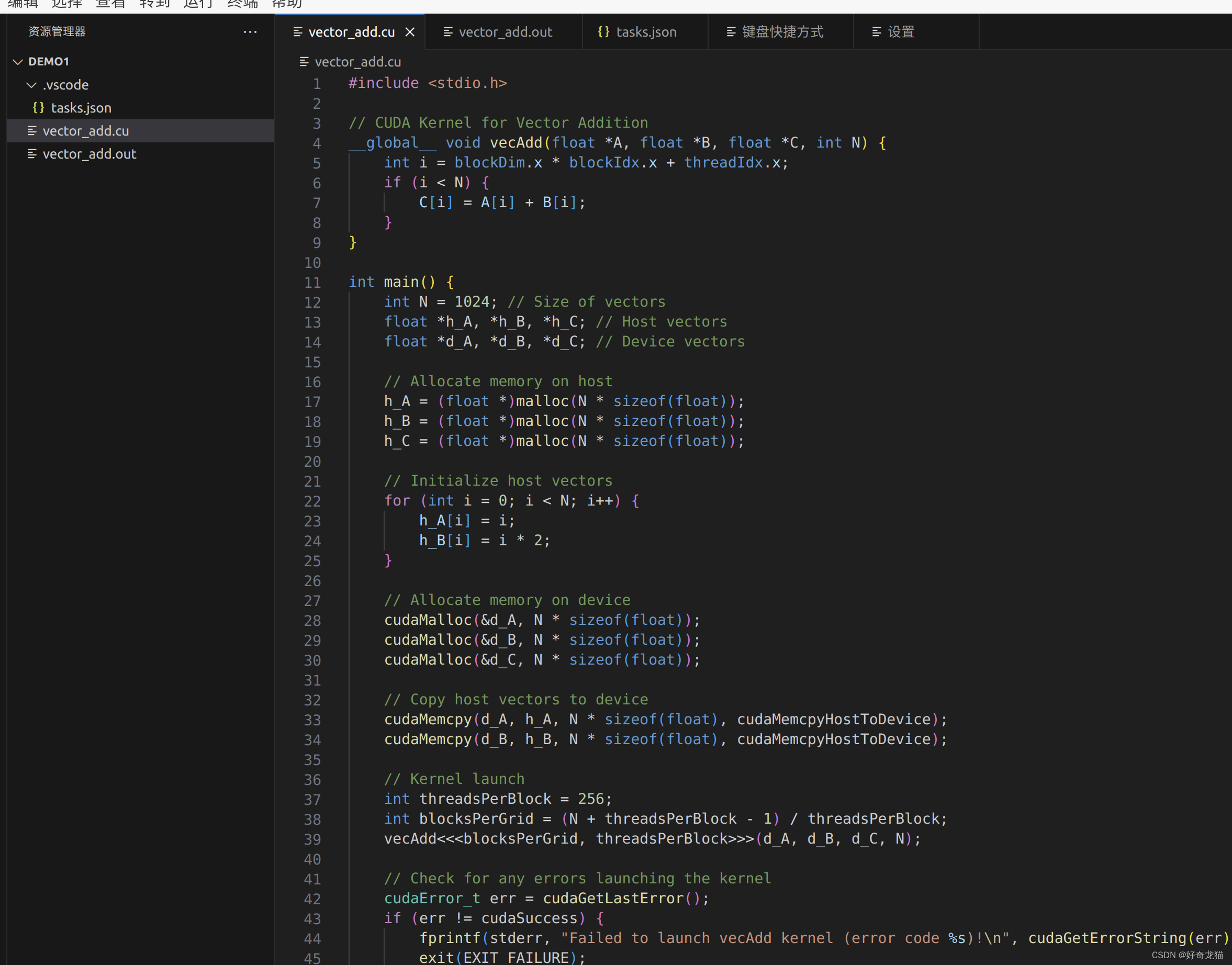
代码文件,就是我们实际要编写代码的文件,也是我们想法延伸。
#include <stdio.h>
// CUDA Kernel for Vector Addition
__global__ void vecAdd(float *A, float *B, float *C, int N) {
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < N) {
C[i] = A[i] + B[i];
}
}
int main() {
int N = 1024; // Size of vectors
float *h_A, *h_B, *h_C; // Host vectors
float *d_A, *d_B, *d_C; // Device vectors
// Allocate memory on host
h_A = (float *)malloc(N * sizeof(float));
h_B = (float *)malloc(N * sizeof(float));
h_C = (float *)malloc(N * sizeof(float));
// Initialize host vectors
for (int i = 0; i < N; i++) {
h_A[i] = i;
h_B[i] = i * 2;
}
// Allocate memory on device
cudaMalloc(&d_A, N * sizeof(float));
cudaMalloc(&d_B, N * sizeof(float));
cudaMalloc(&d_C, N * sizeof(float));
// Copy host vectors to device
cudaMemcpy(d_A, h_A, N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, N * sizeof(float), cudaMemcpyHostToDevice);
// Kernel launch
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
vecAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);
// Check for any errors launching the kernel
cudaError_t err = cudaGetLastError();
if (err != cudaSuccess) {
fprintf(stderr, "Failed to launch vecAdd kernel (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Copy result back to host
cudaMemcpy(h_C, d_C, N * sizeof(float), cudaMemcpyDeviceToHost);
// Check for any errors after the kernel launch
err = cudaGetLastError();
if (err != cudaSuccess) {
fprintf(stderr, "Failed to copy vector C from device after kernel execution (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Verify results
bool success = true;
for (int i = 0; i < N; i++) {
if (h_C[i] != h_A[i] + h_B[i]) {
printf("Error at position %d\n", i);
success = false;
break;
}
}
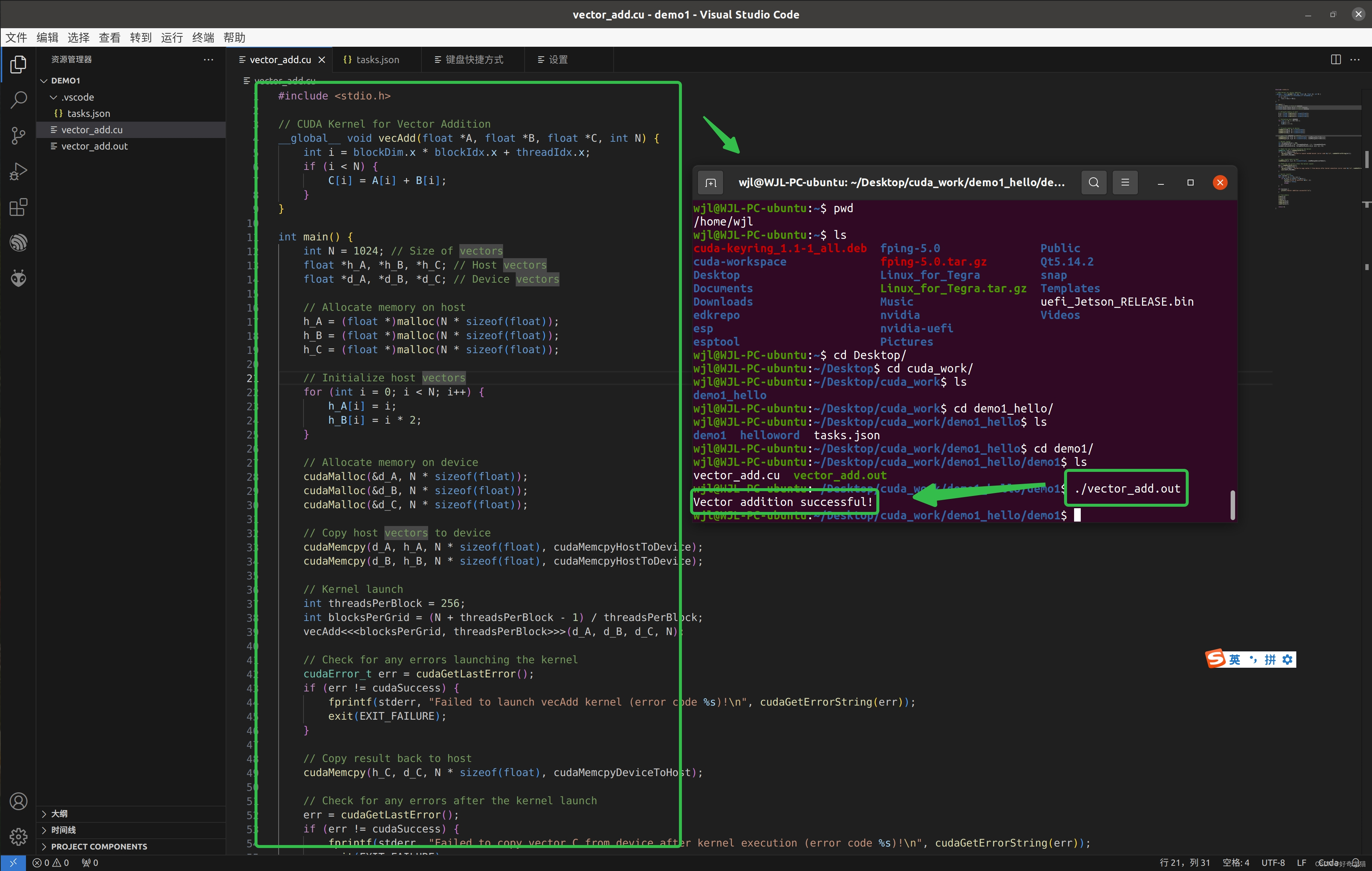
if (success) {
printf("Vector addition successful!\n");
}
// Free memory
free(h_A);
free(h_B);
free(h_C);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
return 0;
}
以下为截图
6、调试&验证
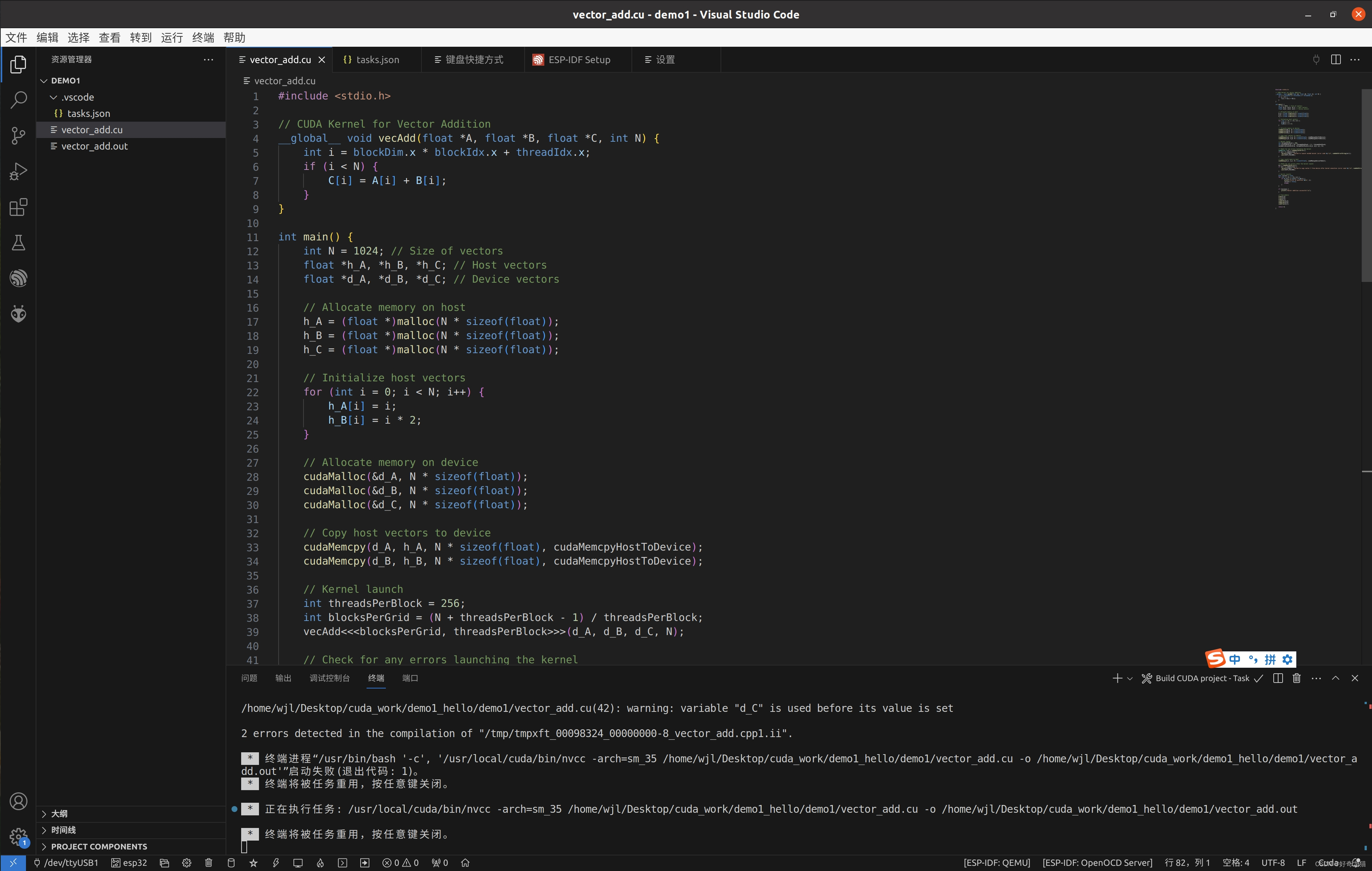
自己在调试
(1)调试
(2)成功
7、代码解读
本代码是在网上找到一个样例,是一个使用CUDA进行向量加法的简单例子。
简单理解下,以后看多了大概就明白了。
(1)包含头文件和定义CUDA内核
#include <stdio.h>
// CUDA Kernel for Vector Addition
__global__ void vecAdd(float *A, float *B, float *C, int N) {
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < N) {
C[i] = A[i] + B[i];
}
}
(2)主函数内的变量定义和内存分配
int main() {
int N = 1024; // Size of vectors
float *h_A, *h_B, *h_C; // Host vectors
float *d_A, *d_B, *d_C; // Device vectors
h_A = (float *)malloc(N * sizeof(float));
h_B = (float *)malloc(N * sizeof(float));
h_C = (float *)malloc(N * sizeof(float));
cudaMalloc(&d_A, N * sizeof(float));
cudaMalloc(&d_B, N * sizeof(float));
cudaMalloc(&d_C, N * sizeof(float));
(3)初始化向量并复制到设备
for (int i = 0; i < N; i++) {
h_A[i] = i;
h_B[i] = i * 2;
}
cudaMemcpy(d_A, h_A, N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, N * sizeof(float), cudaMemcpyHostToDevice);
(4)内核调用
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
vecAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);
(5)检查错误和回复结果
cudaError_t err = cudaGetLastError();
if (err != cudaSuccess) {
fprintf(stderr, "Failed to launch vecAdd kernel (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
cudaMemcpy(h_C, d_C, N * sizeof(float), cudaMemcpyDeviceToHost);
(6)验证结果
bool success = true;
for (int i = 0; i < N; i++) {
if (h_C[i] != h_A[i] + h_B[i]) {
printf("Error at position %d\n", i);
success = false;
break;
}
}
if (success) {
printf("Vector addition successful!\n");
}
(7)清理内存
free(h_A);
free(h_B);
free(h_C);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
6、代码链接
代码链接:https://download.csdn.net/download/qq_22146161/89273073
7、细节部分
1、问题1:一个错误
具体什么错误有点记不清了,这里记录下吧。
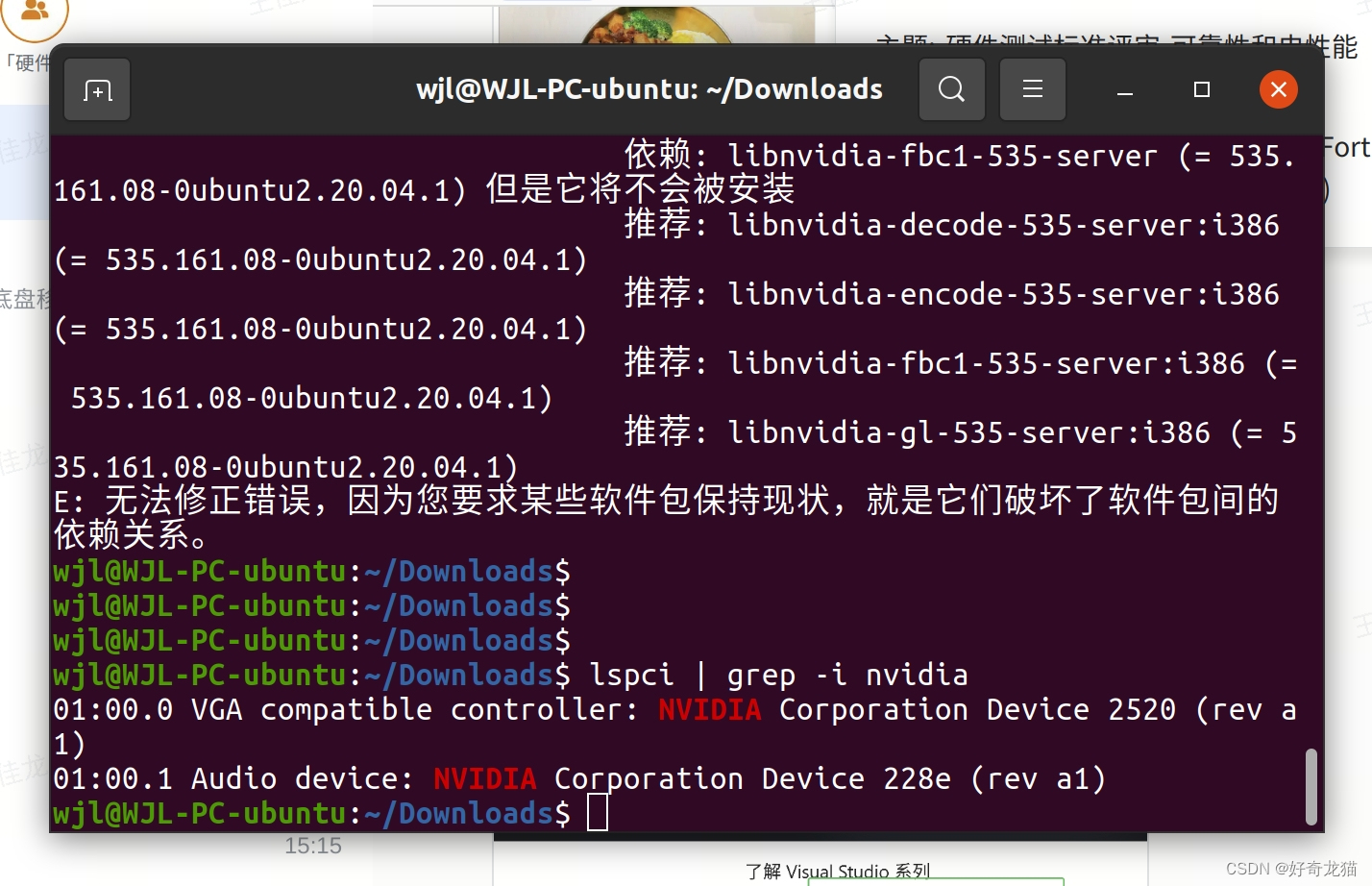
2、问题:使用命令nvidia-smi,无法调出如下信息。
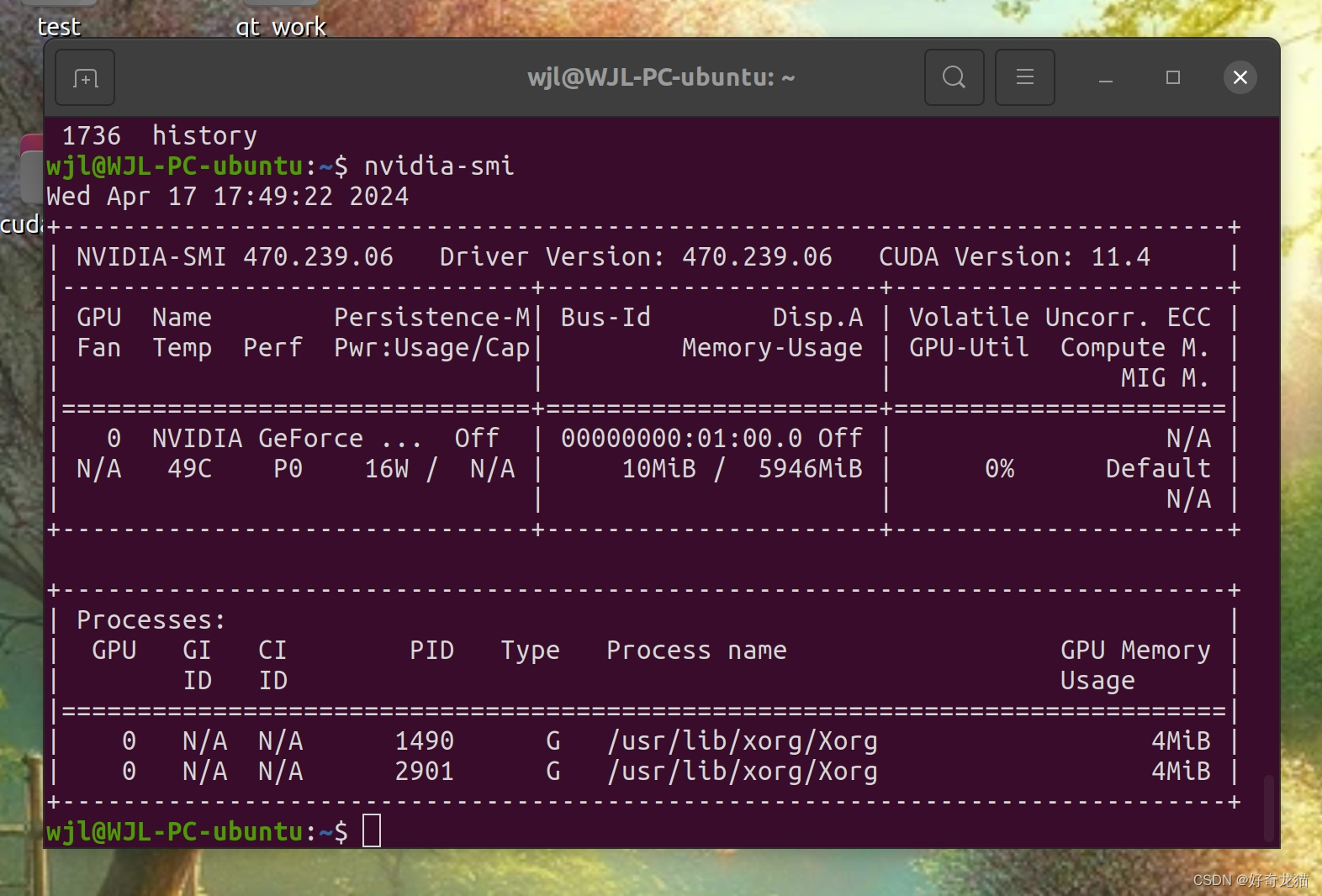
如上图,自己在安装过程中,突然发现nvidia-smi命令,因为一直安装各种东西,应该是影响到了,不反馈信息,后重启解决了。
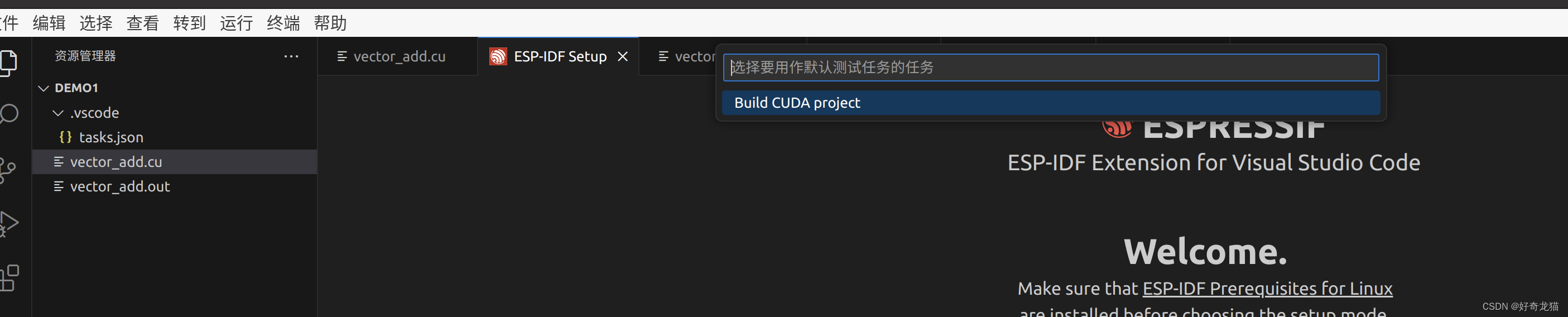
3、Tasks:configure tasks,自动创建tasks.json
稍微有点时间,不过我没记错的话,使用 查看>>命令面板,可以直接创建这个tasks.json文件。
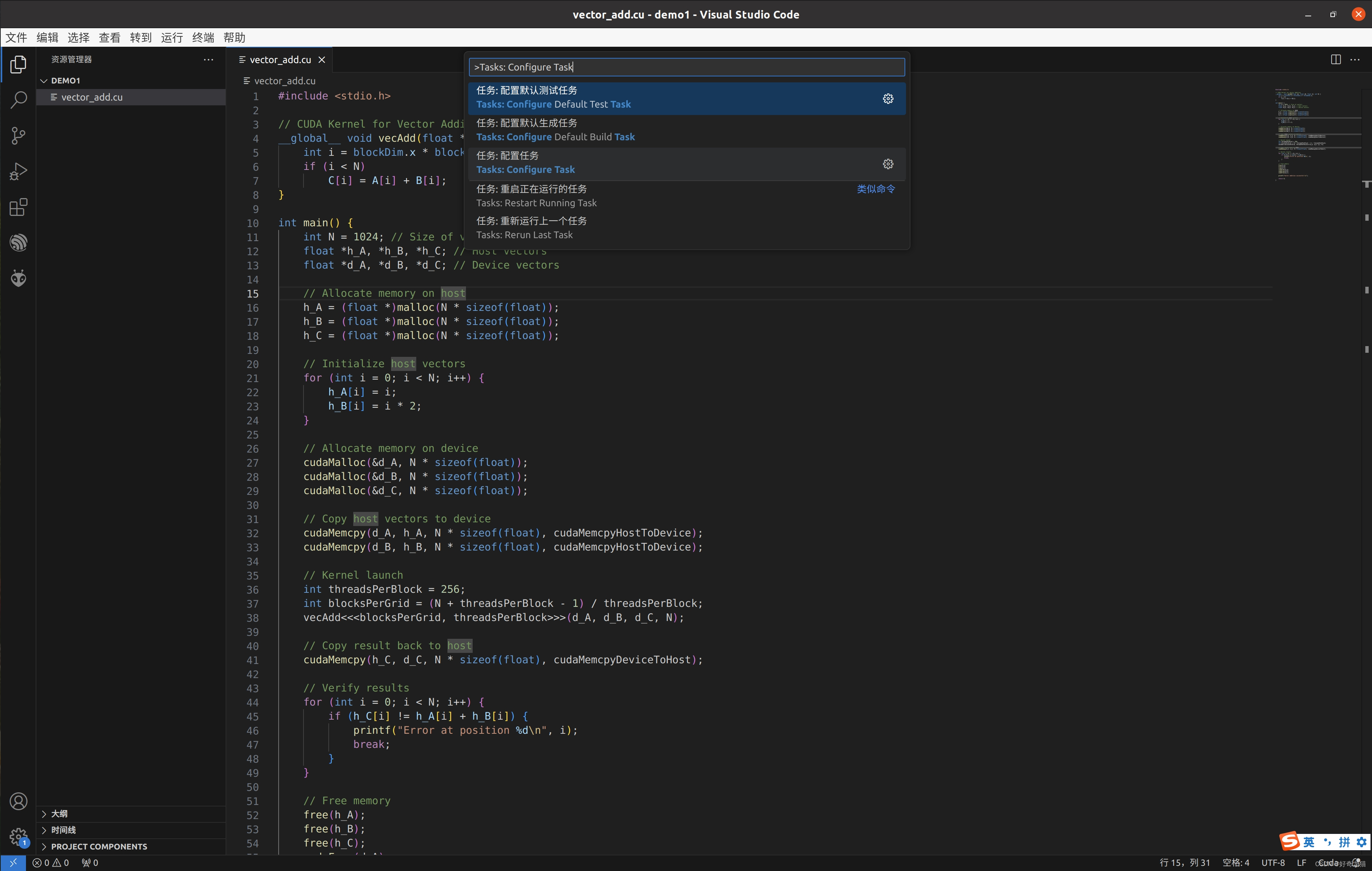
如下步骤
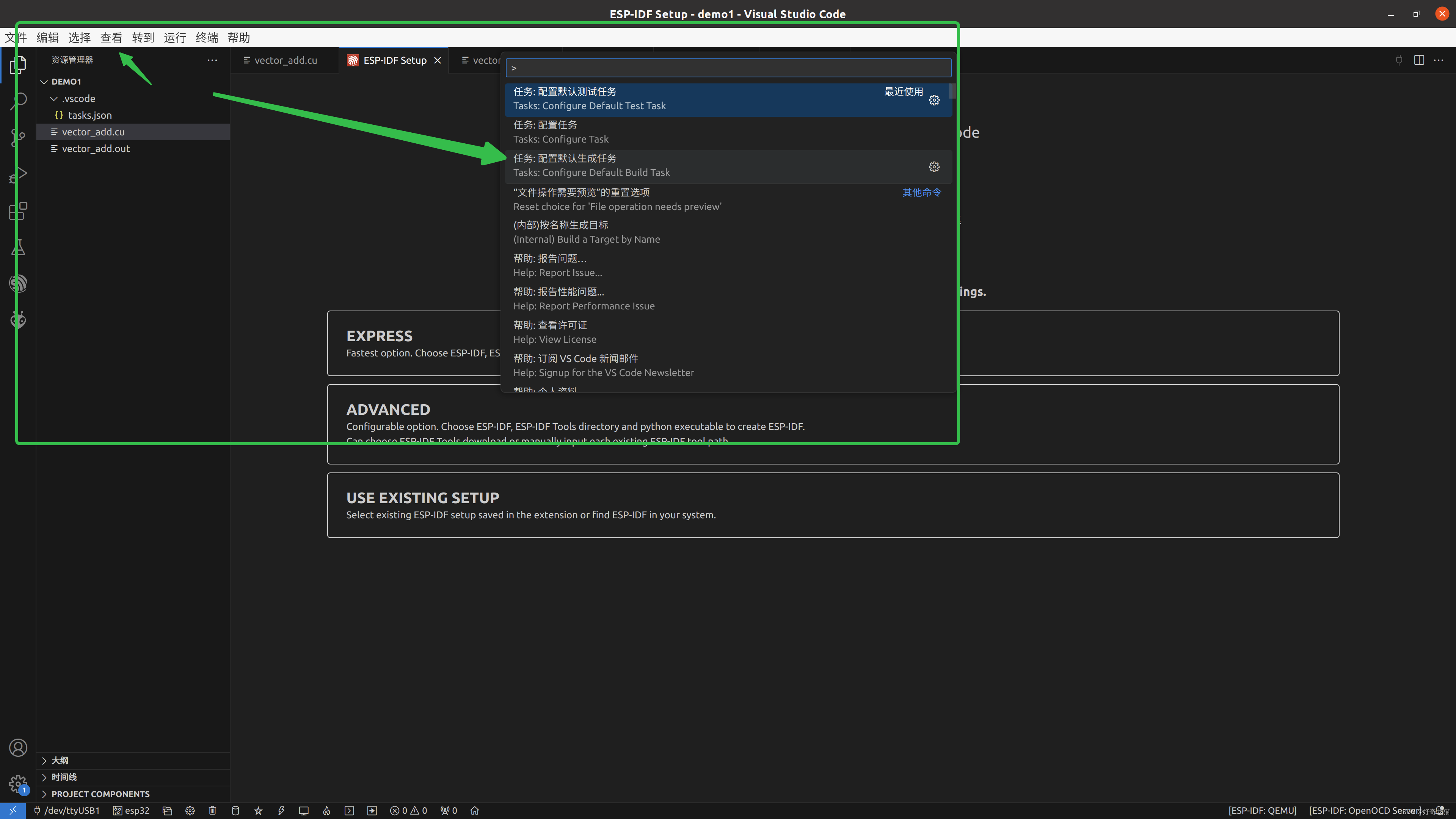
8、总结
很多时候,其实是无法理解每一步,只有常看,才能大致记住,更多调试,后续也会慢慢学习。