通过上一节中的知识,可以知道使用分页作为核心机制来实现虚拟内存是比较不错的,但是因为复杂的查询和转换逻辑,导致性能开销比较大。这里就要使用硬件来提升了,便出现了地址转换旁路缓冲存储器(TLB),可以频繁地发生虚拟到物理地址转换的硬件缓存,每次内存访问的时候,首先检查TLV,如果其中有映射,那就实现很快,如果没有,那就要去访问页表。从而获取页表项。
TLB的基本算法
现在就基本的说明一下过程,假设使用简单的线性页表(数组)和硬件管理的TLB。
从虚拟地址中获取页号,然后再TLB中查看有没有这个VPN的转换映射。如果查找到的话,就从TLB中取出物理页帧,再结合虚拟地址中的偏移量行程物理地址,进而访问内存
如果没有查找到,硬件访问页表来查询转换映射,然后更新到TLB中。这个操作开销比较大,因为访问页表需要额外的内存引用。当TLB更新后,在尝试获取,然后就很快的可以处理。
因为在TLB处理器核心附近,访问的速度很快,所以在查找的时候尽可能的去命中TLB,如果没有的话,那将消耗大量的资源,程序的运行也就会变的很慢。
示例:访问数组
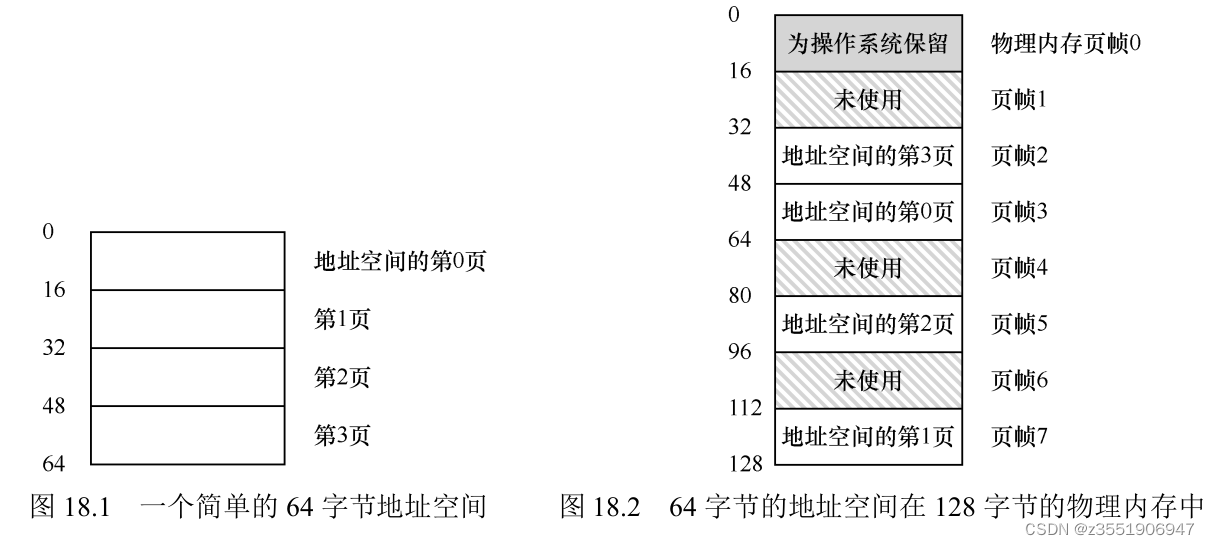
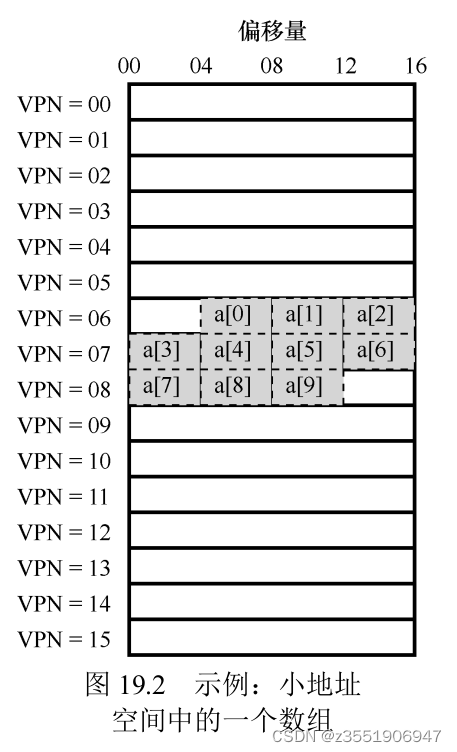 为了搞清楚具体的流程,做了一个示例,图中展示偏移量和VPN,可以看出这是一个有16个虚拟内存也和4位的偏移量。在这里存在了10个数组,假设其实地址为100。可以看到这个数组具体的布局。接下来就来模拟查询。
为了搞清楚具体的流程,做了一个示例,图中展示偏移量和VPN,可以看出这是一个有16个虚拟内存也和4位的偏移量。在这里存在了10个数组,假设其实地址为100。可以看到这个数组具体的布局。接下来就来模拟查询。
在查询中,肯定使用的是for循环,做一个简单的代码书写:
int sun = 0;
for (int i = 0; i < 10; i++) {
sum += a[i];
}当访问a[1]的时候,cpu会看到虚拟地址100,这个时候提出VPN=06,用来检查TLB,没有命中,然后去页表中查,将拿到的有效的转换映射放回到TLB,接下来在查 a[1] a[2]的时候,就全部都是命中的。接着往后的逻辑都是一样的。查找两次没有命中。其他的都是命中,这确实大大的提高了性能,你想想,现在知识一个16字节的,实际情况下是32字节,并且页的大小是4KB,这种情况下,密集型,基于数组的访问会有很好的性能。
并且基于时间局部性原理,在很短的时间中,再次访问的概率非常的大,所以命中的概率非常高。
提示:尽可能利用缓存
缓存是计算机系统中最基本的性能改进技术之一,一次又一次地用于让“常见的情况更快”[HP06]。硬件缓存背后的思想是利用指令和数据引用的局部性(locality)。通常有两种局部性:时间局部性(temporal locality)和空间局部性(spatial locality)。时间局部性是指,最近访问过的指令或数据项可能很快会再次访问。想想循环中的循环变量或指令,它们被多次反复访问。空间局部性是指,当程序访问内存地址 x 时,可能很快会访问邻近 x 的内存。想想遍历某种数组,访问一个接一个的元素。当然,这些性质取决于程序的特点,并不是绝对的定律,而更像是一种经验法则。
硬件缓存,无论是指令、数据还是地址转换(如 TLB),都利用了局部性,在小而快的芯片内存储器中保存一份内存副本。处理器可以先检查缓存中是否存在就近的副本,而不是必须访问(缓慢的)内存来满足请求。如果存在,处理器就可以很快地访问它(例如在几个 CPU 时钟内),避免花很多时间来访问内存(好多纳秒)
谁来处理TLB未命中
在之前,因为造硬件的不放心写操作系统的人,所以硬件全权处理TLB未命中,那么硬件就必须知道页表在内存总的确切位置(通过页表基址寄存器),以及也标的确切格式,用于遍历页表,找到页表项,取出转换映射,用来更新TLB。这是之前的复杂指令集计算机。
但是在现在的精简指令集计算机中,当TLB没有命中的时候,硬件会抛出异常,暂停当前的指令流,将特权级提升到内核模式,跳转到陷阱处理程序,然后去查找页表中的转换映射,然后用特别的特权指令去更新TLB,并且从陷阱返回,再重新执行该指令,导致TLB命中。
这里描述几个细节问题,首先就是这里的陷阱返回指令和系统调用返回的指令是不一样的,系统调用返回后执行的是下一句指令,而这个是从导致出发陷阱的指令执行。所以系统在陷入陷阱的时候必须保存不同的程序计数器。
在TLB没有命中的时候,需要避免无限递归。有很多的解决方法:
把TLB未命中的陷阱处理处理程序直接放到物理地址中,因为他们没有映射过,所以不用地址转换。
在TLB中保存一些项,记录为永远有效的地址转换,并将其中一些永久地址转换槽块留给处理代码本身,这些被监听的(wired)地址转换总是会命中 TLB。
两者对比就会发现,软件管理的方法,更加灵活,操作系统可以使用任意的数据结构去实现页表,不需要硬件改变,另一个就是简单,备用件不需要很多的工作,只需抛出异常。
补充:RISC 与 CISC
在 20 世纪 80 年代,计算机体系结构领域曾发生过一场激烈的讨论。一方是 CISC 阵营,即复杂指令计算机(Complex Instruction Set Computing),另一方是 RISC,即精简指令集计算(Reduced Instruction Set Computing)[PS81]。RISC 阵营以 Berkeley 的 David Patterson 和 Stanford 的 John Hennessy 为代表(他们写
了一些非常著名的书[HP06]),尽管后来 John Cocke 凭借他在 RISC 上的早期工作 [CM00]获得了图灵奖。
CISC 指令集倾向于拥有许多指令,每条指令比较强大。例如,你可能看到一个字符串拷贝,它接受两个指针和一个长度,将一些字节从源拷贝到目标。CISC 背后的思想是,指令应该是高级原语,这让汇编语言本身更易于使用,代码更紧凑。
RISC 指令集恰恰相反。RISC 背后的关键观点是,指令集实际上是编译器的最终目标,所有编译器实际上需要少量简单的原语,可以用于生成高性能的代码。因此,RISC 倡导者们主张,尽可能从硬件中拿掉不必要的东西(尤其是微代码),让剩下的东西简单、统一、快速。
早期的 RISC 芯片产生了巨大的影响,因为它们明显更快[BC91]。人们写了很多论文,一些相关的公司相继成立(例如 MIPS 和 Sun 公司)。但随着时间的推移,像 Intel 这样的 CISC 芯片制造商采纳了许多 RISC 芯片的优点,例如添加了早期流水线阶段,将复杂的指令转换为一些微指令,于是它们可以像 RISC 的方式运行。这些创新,加上每个芯片中晶体管数量的增长,让 CISC 保持了竞争力。争论最后平息了,现在两种类型的处理器都可以跑得很快。
TLB的内容
典型的TLB有32项,64项,128项。并且都是全相连的。注意VPN和PFN同时存在于TLB中,因为一条地址映射可能出现在任意位置。
这里需要注意的是,不要混淆TLB的有效位和页表的有效位,当页表中的一个页表项标记的是无效,那就会被杀死该进程,因为这个页表项没有被申请使用。TLB的则不是,因为它表示的是这个是不是有效的地址映射,当系统刚刚启动的时候,所有的都是无效的,然后当程序慢慢的运行。最后填满整个TLB。
在TLB中还有一些其他位,比如保护位,用来判断该页为可读还是可执行。
上下文切换时对TLB的处理
TLB只对当前进程是有效的,当进行切换的时候,需要确保运行的进程不要读取了之前进程的地址映射。那怎么做到让硬件去分清那个进程和那个项是有关联的呢?
在进行上下文切换的时候,简单清空TLB。但是有开销,因为每次运行的时候都会访问代码页和数据,都会触发未命中,然后性能比较差了。
在TLB中添加一个ASIN地址空间标识符,用来表示是哪个进程,比PID(32)少,是8位,然后在上下文切换的时候,将某个特权寄存器设置为当前进程的ASID。
这里也就出现了一个问题,可能会发现两个进程的VPN指向相同的物理页。这种事共享代码页,非常有用,减少了物理页的使用,也就减少了内存开销。
TLB替换策略
当TLB满的时候,再插入一个新项的时候,就需要替换旧的,那这个缓存替换用哪种算法比较好呢?
最近最少使用的项(LRU),利用内存引用流中的局部性。
随机策略(random),比较简单,也可以避免极端情况。例如:一个程序循环访问 n+1 个页,但 TLB 大小只能存放 n 个页
实际系统的TLB表项
 上面这个是稍微简化的
上面这个是稍微简化的
基本的信息可以看到,需要注意的就是,VPN只有19位,因为另一半需要留给内核,转换为最大24位的物理帧号,也就是64GB物理内存。
然后其中有一些标识位,比如全局位(G)用来指示这个页是不是所有的进程全局共享得。如果共享就忽略ASID,一致性位:决定硬件如何缓存该页。脏位:表示这个页是否被写入新数据。有效位:映射地址是否有效。
操作系统可以设置备件听的寄存器,告诉硬件自己需要多少的TLB槽,这些保留的转换映射,是为了保存操作系统在关键时候需要用的代码和数据。
然后因为MIPS的TLB是有软件管理的,所以也有些指令去管理TLB,如果有兴趣的话,可以去了解一下。
提示:RAM 不总是 RAM(Culler 定律)
随机存取存储器(Random-Access Memory,RAM)暗示你访问 RAM 的任意部分都一样快。虽然一般这样想 RAM 没错,但因为 TLB 这样的硬件/操作系统功能,访问某些内存页的开销较大,尤其是没有被 TLB 缓存的页。因此,最好记住这个实现的窍门:RAM 不总是 RAM。有时候随机访问地址空间,尤其是 TLB 没有缓存的页,可能导致严重的性能损失。
总结
通过了解TLB的知识,做出了可以让地址转换的更快。但是有些时候会超会TLB的范围,这样就需要一个更大的页,去解决这个问题了。然后就是TLB很容易成为CPU流水线的瓶颈,然后人民用虚拟地址直接访问缓存,避免昂贵的地址转换的步骤。