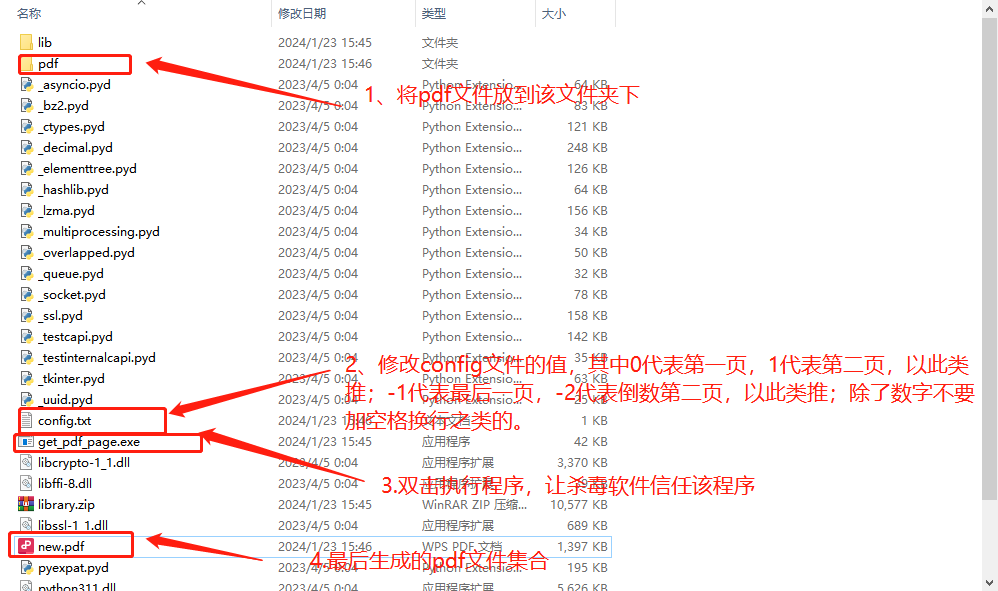
使用python将多张图片转为一个PDF
更新时间:20240418,亲测有用
用法1:传入的是图片路径列表
from PIL import Image
import os
# TODO 用法1,传入的是图片路径列表
def convert_images_to_pdf(image_paths, output_path):
images = []
for image_path in image_paths:
image = Image.open(image_path)
images.append(image.convert("RGB"))
images[0].save(output_path, save_all=True, append_images=images[1:])
# 示例用法
image_paths = ["0.png","1.png", "2.png", "3.png"]
output_path = "output.pdf"
convert_images_to_pdf(image_paths, output_path)
convert_images_to_pdf的作用是将多张图片转换为一个PDF文件。函数接受两个参数:image_paths表示图片文件的路径列表,output_path表示生成的PDF文件的路径。
首先,函数创建一个空列表images用于存储转换后的图片对象。然后,通过循环遍历image_paths列表中的每个图片路径,使用Image.open()函数打开图片,并将其转换为RGB模式后添加到images列表中。
接下来,使用images.save()方法将第一张图片保存为PDF文件。save_all=True表示保存所有的图片,append_images=images[1:]表示将剩余的图片追加到PDF文件中,[1:]指的就是从第二张图片到最后的所有图片(append的意思是追加)。
这样,当调用convert_images_to_pdf函数时,传入图片路径列表和输出路径,就可以将这些图片转换为一个PDF文件。
因此save函数的参数不可以删除。
用法2:传入的是文件夹
def convert_images_to_pdf(input_dir, output_path):
image_files = [f for f in os.listdir(input_dir) if
f.endswith('.png') or f.endswith('.jpg')] # ['0.png', '1.png', '2.png', '3.png']
print(image_files)
images = []
for image_path in image_files:
image_path = os.path.join(input_dir, image_path)
image = Image.open(image_path)
images.append(image.convert("RGB"))
images[0].save(output_path, save_all=True, append_images=images[1:])
input_dir = "你图片文件夹"
output_path = "output1.pdf"
convert_images_to_pdf(input_dir, output_path)
该函数的使用相比用法1来说,更加广泛,因为很多人都是需要将文件夹里面的图片进行转换。
用法3:解决图片乱序问题
对于图片的命名,我这里使用的是0-图片个数减一的方式命名,比如说我有60张图片,因此我的图片命名就是0.png-59.png,但是会出现一个问题,使用原始方法遍历,image_files这里顺序就乱了,比如1.png后面是11.png,其不是按照数字大小进行排序的,但是我需要用数字大小进行排序,否则文件顺序就乱了。
因此就引出了用法3。
# TODO 解决乱序,1.png后面跟2.png而不是11.png
import os
from PIL import Image
def numerical_sort(value):
try:
return int(value[:-4]) # 去掉文件后缀(比如 .png)后将剩余部分转换为整数
except ValueError:
return value
def convert_images_to_pdf(input_dir, output_path):
image_files = [f for f in os.listdir(input_dir) if
f.endswith('.png') or f.endswith('.jpg')]
# 对图像文件按数字顺序排序
sorted_image_files = sorted(image_files, key=numerical_sort)
print(sorted_image_files)
images = []
for image_path in sorted_image_files:
image_path = os.path.join(input_dir, image_path)
image = Image.open(image_path)
images.append(image.convert("RGB"))
# 将图像转换为 PDF
images[0].save(output_path, save_all=True, append_images=images[1:])
# 示例用法
input_dir = "你图片文件夹"
output_path = "output2.pdf"
convert_images_to_pdf(input_dir, output_path)
关键就是这一行代码
sorted_image_files = sorted(image_files, key=numerical_sort)
在这行代码中,sorted() 函数用于对列表 image_files 进行排序。排序时,我们使用了一个关键字参数 key,它接受一个函数作为参数,这个函数定义了排序时用于比较元素的方式。
在这里,我们将自定义的排序函数 numerical_sort 作为 key 参数传递给 sorted() 函数。这意味着在排序时,不是直接比较文件名的字符串,而是将每个文件名传递给 numerical_sort 函数,然后根据函数返回的结果进行排序。
numerical_sort 函数的作用是将文件名中的数字部分提取出来,并将其转换为整数。这样,文件名中的数字会按照数值大小进行排序,而不是按照字符串的字典顺序排序。这就确保了文件名按照数字顺序进行了排序。