一、递归函数
通过作用域的学习,知道了一个函数内部可以调用其他函数。如果在一个函数内部,调用了函数它自己,那么这个函数就叫 "递归函数" 。例如:
def num(count):
if count == 1: # 检查count是否等于1,因为1的阶乘还是1
result=1
else:
result =num(count-1)* count
# 这里进行了递归调用,计算count-1的阶乘,然后将其结果乘以count
return result
answer = int(input("请输入一个正整数:"))
print("{}!={}".format(answer, num(answer)))
# 此处字符串对象通过点号(.)来访问某函数的属性或功能。算面向对象的内容,后续再细说吧...以上代码可以看出递归函数模块主要由三部分组成:
1、递归调用,函数在内部调用自己
2、返回值,没次递归有确定的返回值
3、基线条件,为避免无限递归,确保有结束点
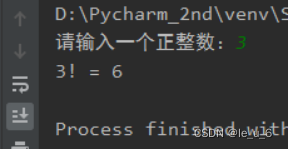
计算3阶乘的结果
二、匿名函数
Python中的匿名函数,也称为lambda函数,是一种不需要通过标准的def语句定义函数,因此它们通常用于创建小型的、一次性的函数对象,尤其是在需要提供函数作为参数传递给另一个函数时。
lambda函数语句格式:

lambda: 这是一个关键字,表示定义匿名函数。
参数列表:可以有一个或多个参数,参数之间用逗号隔开。
表达式:作为函数的返回值。
由于匿名函数的特性,定义好了的匿名函数不可以直接使用,所以最好就是将它赋给一个变量,以便之后随时可以使用这个被赋值匿名的变量函数。
举个栗子:
cube = lambda a: a**3
# 参数a代表输入的数值,返回值是a的三次方,即a*a*a
x = float(input("请输入正方体的边长:")) # 输入的内容赋值给变量x
print("该正方体的体积为:", cube(x)) # 调用之前定义的cube函数,计算正方体的体积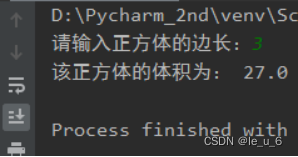
需要注意的是,使用lambda 声明的匿名函数能接收任何数量的参数,但都只能返回一个表达式的值。然后、由于匿名函数的函数模块只是一个表达式,所以它不能直接使用 print() 函数,即:lambda 函数体内直接写 print ()调用是错误的,因为print()是一个语句!不是一个表达式。
此外,在Python中,lambda表达式就是一种创建匿名函数的方式。由于lambda表达式不需要通过def 关键字定义,所以它可以作为参数直接传递给函数。例如:
numbers = [3, 6, 9]
# 将列表中的每个数字乘以2
doubled_numbers =list(map(lambda a: a*2, numbers))
# 使用map函数,依次对numbers的元素进行选代,再赋给doubled_numbers
print(doubled_numbers) # 输出doubled_numbers列表这里我们就是将 lambda 函数 作为参数传递给 map函数 ,然后在python3中要记得带上数据类型 list ,否则只会给你报出个存放地址。
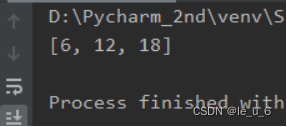
得到依次迭代2倍的列表结果
三、随机函数
Python 中的 random 模块用于生成一个随机数。它提供了很多函数,接下来针对常见的几种随机数函数进行举例:
1.random.random( )
import random
print("生成的随机数:",random.random())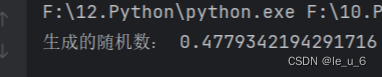
random( )函数,只随机生产一个 [ 0 , 1 ) 区间的浮点数
2.random.uniform(a, b)
返回一个 [ a , b ) 区间内的浮点数
import random
print("一个10-20的随机数:", random.uniform(10, 20))
print("一个10-20的随机数:", random.uniform(20, 10)) 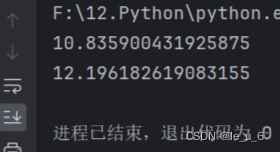
返回a与b之间的一个随机浮点数 ‘N’,区间为 [ a , b ]
如果a的值小于b的值,则生成的随机浮点数 N的取值范围为a<=N<=b
如果a的值大于b的值,则生成的随机浮点数 N的取值范围为 b<=N<=a
3.random.randint(a, b)
返回一个 [a,b] 范围内的整数
import random
print(random.randint(10, 20)) # 生成一个10-20的随机整数
print(random.randint(10, 10)) # 只会生成一个10的整数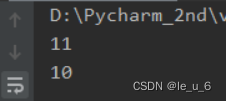
需要注意randint函数,下限必须小于上限 !否则报错:


4.random.randrange(start, stop[, step])
返回一个 [ start, stop ) 范围内的整数,可以指定步长step
start : 表示你想定的范围的开始值,这个开始值包含在范围内
stop : 表示你想定的范围的结束值,这个开始值不包含在范围内
step : 表示你想在这个范围内跨过固定的长度,可以根据上限/下限的长度取:正/负值,但就是不能取0
栗子:
import random
print(random.randrange(90, 100, 1))
print(random.randrange(110, 100, -1))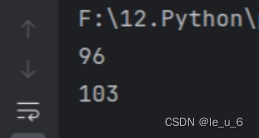
如果 step取0,意味着,持续随机的都只会是同一个数,那就不随机了,陷入循环,报错!
那如果想,得出范围内的所有数据,不再只得单个的,则用到下面的choices函数
5.random.choice (sequence)
从非空的序列中随机选取一个元素。
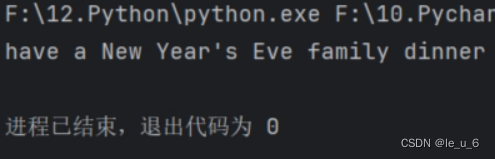
import random
print(random.choice(['Spring Festival', "have a New Year's Eve family dinner",
'Mid-Autumn Festival', 'have a mooncake',
'Dragon Boat Festival', 'row-dragon-boat']))直接随机打印列表中的一个结果
5.5 random.choices(population,weights=None,k=1)
它允许从给定的 population 序列中随机选取k个元素。
population: 一个非空序列,如列表、元组或字符串,从中进行选择。
weights:这是一个可选参数,必须是和 population 同样长度的序列,表示每个元素被选中的概率权重。如果没有提供 weights,则每个元素被选中的概率相等。
k:一个整数,表示要选取的元素数量。默认值为1,表示只选取一个元素。
返回值:
如果k等于1,则返回一个元素。
如果k大于1,则返回一个列表,包含k个随机选取的元素。
例如:
import random
# 生成一个步长为2,包含90到99所有整数的列表
number_list = list(range(90, 100, 2))
# 使用 random.choices 随机选择 number_list 中的所有元素
# 使用变量 num_elements 来指定选择的元素数量
num_elements = len(number_list)
selected_elements = random.choices(number_list, k=num_elements)
print(selected_elements)在random.choices(number_list , k=num_elements) 中,函数会从 number_list 中选取5个元素,并且这些元素的选取是随机的,就可能会有重复。意味着,在 selected_elements 列表中,原来列表中的每个元素都可能出现多次,甚至可能出现全部。
具体详情可访问以下网站:

—————————————————— 分割线 ————————————————————
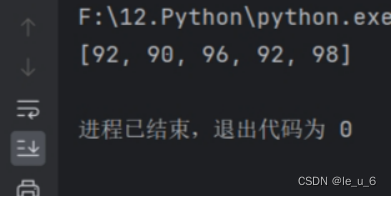
打印结果在范围内,且’92’重复出现了...如果想要多个且不重复的,我们可用下面介绍的sample( )函数。
6.random.sample(population, k)
从 population 序列中随机选取 k个不同的元素。
从你想定的范围中随机获取 k个元素作组成一个新的子序列进行返回,而不会修改原来的序列。
示例如下:
import random
list_occupation = ['musician', 'director', 'model',
'postman', 'headmaster', 'pilot',
'nurse', 'engineer', 'scientist',]
# 从 list_occupation 中随机抽5个元素,作为一个片段返回
fragment = random.sample(list_occupation, 5)
# 打印出随机抽的元素和打印原来的列表元素
print(fragment)
print(list_occupation)
有兴趣的可以和 slice( ) 函数 来比较着学习,也是关于序列截取的用法!
最后讲个shuffle( )函数...
7.random.shuffle(x [, random] )
用于将序列x 中的元素随机打乱顺序。例如:

第91行用了for循环语句中的字典推导式,能够进行更复杂的一些循环结构,所以你也可以尝试将所有键值对的“键”和“值”都打乱顺序.../^ u ^/,然后再重组成新的字典 !

P.S.
下回再做个有意思的随机系统(p^ - ^p)























![[已解决]ModuleNotFoundError: No module named ‘einops‘](https://img-blog.csdnimg.cn/direct/177b0e299d9048beaec77e973a9f3a81.png)