引言
在大数据处理中,日志数据的采集是数据分析的第一步。Apache Flume是一个分布式、可靠且可用的系统,用于有效地收集、聚合和移动大量日志数据到集中式数据存储。本文将详细介绍如何使用Flume采集日志数据,并将其上传到Hadoop分布式文件系统(HDFS)中。
Flume简介
Apache Flume是一个高可用的、高可靠的,分布式的海量日志采集、聚合和传输的系统。它基于流式架构,提供了灵活性和简单性,能够实时读取服务器本地磁盘的数据,并将数据写入到HDFS。
系统要求
- Hadoop已经搭建并配置好。
- Flume 1.9.0或更高版本。
安装Flume
- 从Flume官网下载所需版本的Flume。
- 将下载的tar.gz文件上传到服务器的指定目录。
- 解压缩并配置环境变量。
Flume配置
Flume的配置文件定义了数据流的来源和去向。以下是一个基本的配置示例,它定义了一个简单的Flume Agent,该Agent从一个本地端口收集数据,并将其输出到控制台。
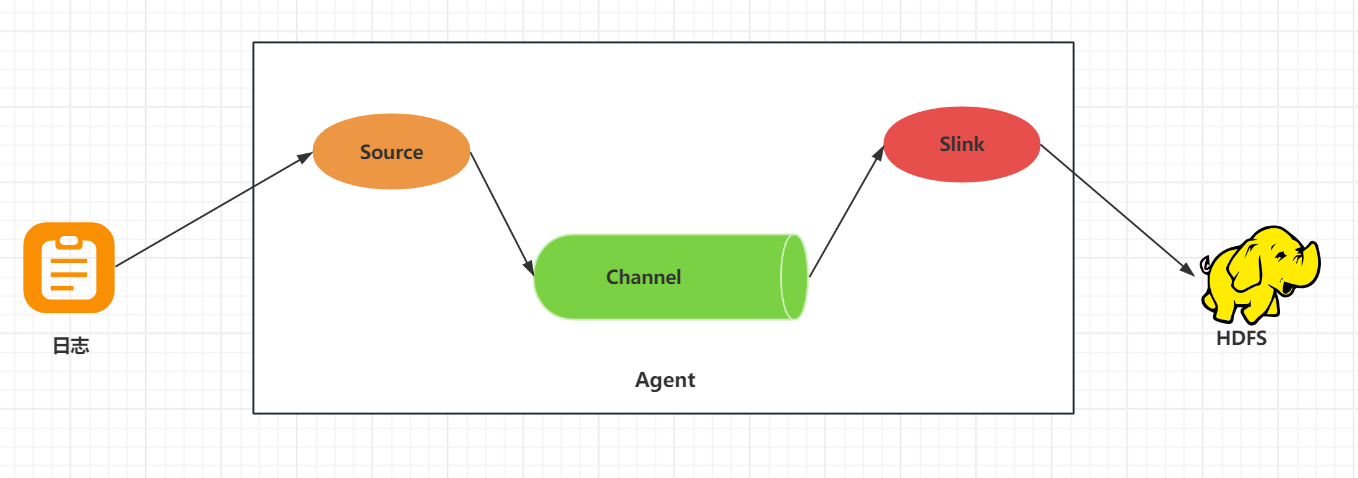
Flume的架构上可以知道,它主要分为三部分source、sink和channel:
在flume/conf目录下创建flume-hdfs.conf文件
vim flume-hdfs.confflume-hdfs.conf的内容
# 定义agent的组件名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 配置source
a1.sources.r1.type = exec # 设置source类型为exec,表示执行一个命令
a1.sources.r1.command = tail -F /var/log/flume-test.log # 设置要执行的命令,实时读取指定日志文件的最新内容
# 配置sink
a1.sinks.k1.type = hdfs # 设置sink类型为hdfs,表示数据将被写入HDFS
a1.sinks.k1.hdfs.path = hdfs://localhost:9000/flume/logs/ # 设置HDFS的目标路径
a1.sinks.k1.hdfs.filePrefix = fluem-logs- # 设置写入HDFS的文件前缀
a1.sinks.k1.hdfs.fileType = DataStream # 设置文件类型为DataStream,表示数据将以流的形式写入
# 配置channel
a1.channels.c1.type = memory # 设置channel类型为memory,表示使用内存作为中转
a1.channels.c1.capacity = 1000 # 设置channel的容量
a1.channels.c1.transactionCapacity = 100 # 设置每个事务的容量
# 将source和sink绑定到channel
a1.sources.r1.channels = c1 # 将source r1绑定到channel c1
a1.sinks.k1.channel = c1 # 将sink k1绑定到channel c1
启动Hadoop
start-dfs.sh启动Flume Agent
配置文件准备好后,可以使用以下命令启动Flume Agent:
cd /usr/local/flume
flume-ng agent --conf ./conf --conf-file flume-hdfs.conf --name a1 -Dflume.root.logger=INFO,console给fluem-test.log追加一行日志
echo hello world! 2024 >> /var/log/flume-test.log
回到flume启动窗口会增加日志

验证
启动Flume Agent后,可以通过查看HDFS上的文件来验证数据是否成功上传。
hdfs dfs -ls /flume/logs/在hdfs上已经增加了文件了

我们用网页来看一下
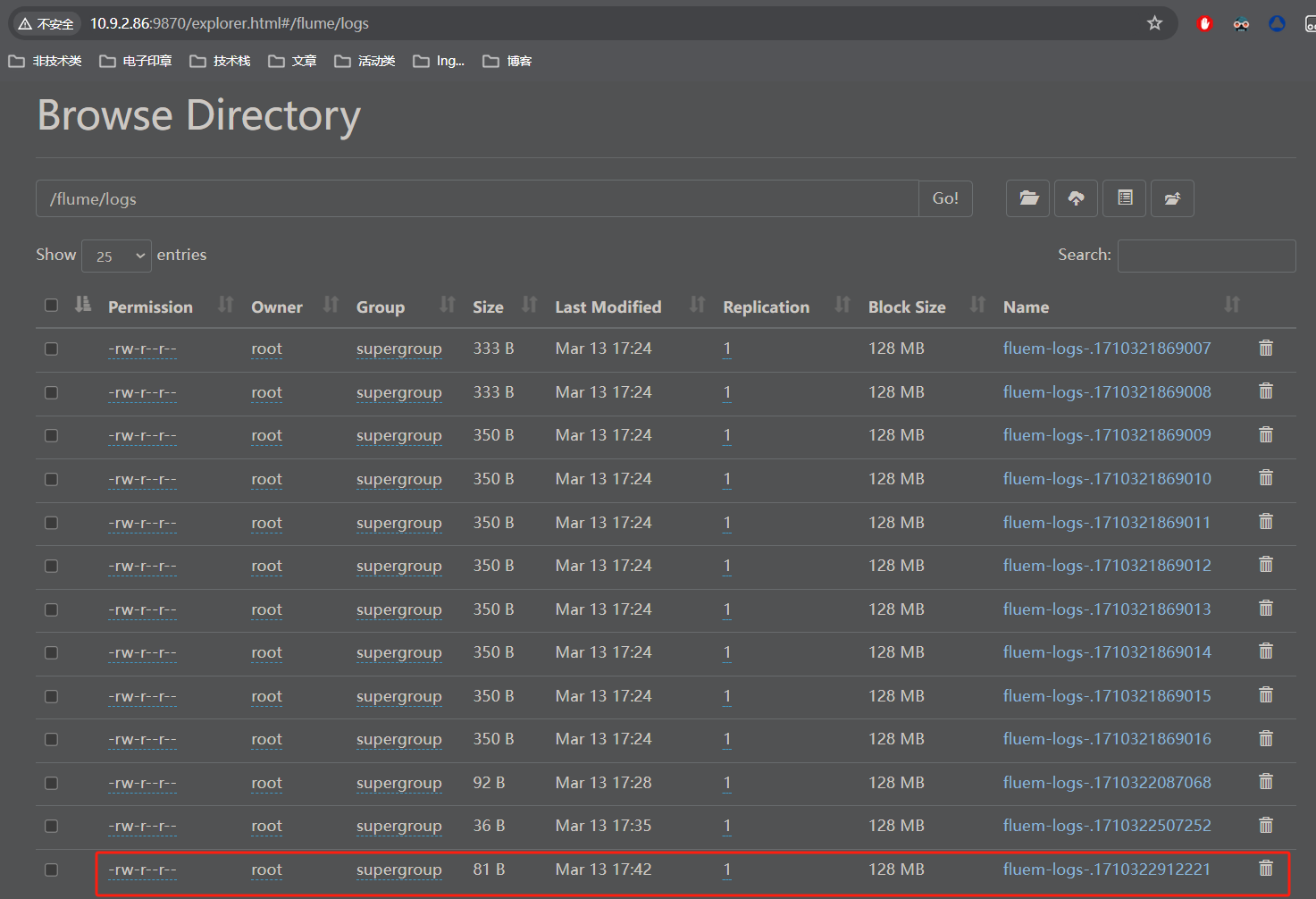
至此就完成了flume采集日志并上传至hdfs了。
补充:
以上使用的channel是memory的方式,也可以换成file模式,memory的弊端是中断会丢失数据。
# 定义agent的组件名称
a1.sources = r1 # 定义source组件的名称为r1
a1.sinks = k1 # 定义sink组件的名称为k1
a1.channels = c1 # 定义channel组件的名称为c1
# 配置source
a1.sources.r1.type = exec # 设置source类型为exec,用于执行指定的命令
a1.sources.r1.command = tail -F /var/log/flume-test.log # 设置要执行的命令,这里使用tail命令实时读取日志文件
# 配置sink
a1.sinks.k1.type = hdfs # 设置sink类型为hdfs,用于将数据写入Hadoop分布式文件系统
a1.sinks.k1.hdfs.path = hdfs://localhost:9000/flume/logs/ # 设置HDFS的目标路径,数据将被写入这个路径
a1.sinks.k1.hdfs.filePrefix = flume-logs- # 设置写入HDFS的文件前缀
a1.sinks.k1.hdfs.fileType = DataStream # 设置文件类型为DataStream,数据将以流的形式写入文件
# 配置channel为文件模式
a1.channels.c1.type = file # 设置channel类型为file,表示使用文件系统进行数据缓存
a1.channels.c1.checkpointDir = /var/lib/flume/checkpoint # 设置checkpoint目录,Flume将在这里存储已经处理的数据的状态
a1.channels.c1.dataDirs = /var/lib/flume/data # 设置数据目录,Flume将在这里缓存尚未传输到sink的数据