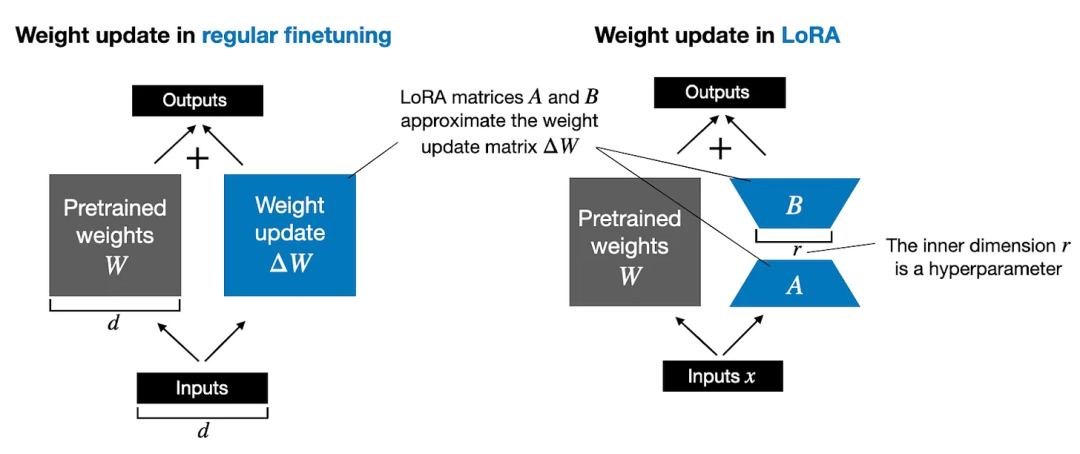
优化器是一种用于优化模型权重和偏差的算法,它根据训练数据更新模型参数,以模型的预测结果更加准确。
1. 常见的优化器
SGD(Stochastic Gradient Descent):SGD是一种基本的优化算法,它在每次迭代中随机选择一个样本进行梯度计算和参数更新。SGD使用固定的学习率,通常需要更多的迭代才能收敛,但在一些情况下也可以取得很好的效果,简单易于实现,但在非凸优化问题中可能会出现收敛速度慢的问题。
RMSprop(Root Mean Square Propagation):RMSprop是自适应学习率的一种方法,它在训练过程中调整学习率,以便更好地适应不同特征的梯度。RMSprop通过维护梯度平方的移动平均来调整学习率。
Adagrad(Adaptive Gradient):Adagrad是一种自适应学习率的优化器,它根据参数的历史梯度进行学习率调整。Adagrad适用于稀疏数据集,在训练初期对稀疏特征有较大的学习率,随着训练的进行逐渐减小。可能会在训练后期由于学习率过小导致收敛速度变慢。
Adadelta:Adadelta是Adagrad的改进版本,它通过引入梯度平方的衰减平均来解决Adagrad学习率过早衰减的问题。Adadelta不需要手动设置学习率,并且在训练过程中可以自适应地调整学习率。
Adam(Adaptive Moment Estimation):Adam是一种基于梯度的优化器,结合了自适应学习率和动量的概念。它在训练过程中自适应地调整学习率,并利用动量来加速梯度更新。Adam在很多NLP任务中表现良好。
Adamax:Adamax是Adam的变体,它使用了无穷范数(infinity norm)来对梯度进行归一化。
AdamW:AdamW是Adam的一种变体,它引入了权重衰减(weight decay)的概念。权重衰减可以有效防止模型过拟合。
Nadam(Nesterov-accelerated Adaptive Moment Estimation):Nadam是Adam与Nesterov动量法的结合,它在Adam的基础上加入了Nesterov动量的修正项。
2. 示例代码
python代码:
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import imdb
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD, RMSprop, Adagrad, Adadelta, Adamax, Nadam
from transformers import AdamW
from sklearn.model_selection import train_test_split
from tensorflow.keras.preprocessing import sequence
# 加载IMDB情感分类数据集
(X_train, y_train), (_, _) = imdb.load_data(num_words=10000)
X_train = X_train[:3000] # 只使用部分数据进行演示
y_train = y_train[:3000]
# 数据预处理:将序列填充为相同长度
X_train = sequence.pad_sequences(X_train, maxlen=10000)
# 划分训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=36)
# 构建模型
model = Sequential()
model.add(Dense(64, activation='relu', input_dim=10000))
model.add(Dense(1, activation='sigmoid'))
# 定义优化器列表
optimizers = [Adam(), SGD(), RMSprop(), Adagrad(), Adadelta(), Adamax(), Nadam()]
optimizer_names = ['Adam', 'SGD', 'RMSprop', 'Adagrad', 'Adadelta', 'Adamax', 'Nadam']
# optimizer_names = ['Adam', 'SGD', 'RMSprop', 'Adagrad', 'Adadelta', 'Adamax', 'Nadam', 'AdamW']
histories = []
# 训练模型并记录历史
for optimizer in optimizers:
model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])
history = model.fit(X_train, y_train, validation_data=(X_val, y_val), epochs=160, batch_size=32, verbose=0)
histories.append(history)
# 绘制学习曲线
plt.figure(figsize=(12, 6))
for i, history in enumerate(histories):
plt.plot(history.history['val_loss'], label=optimizer_names[i])
plt.title('Validation Loss Comparison')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
运行结果: