一、目录
- deepspeed 简介
- 库安装配置
- deepspeed 实现demo
- 如何配置deepspeed参数
- 案例分析
二、实现
- deepspeed 简介
Deepspeed是微软的大规模分布式训练工具。专门用于训练超大模型。主要目标是降低训练期间的内存占用、通信开销和计算负载,从而使用户能够训练更大的模型并更高效地利用硬件资源。
增加的功能主要有:
- Zero:零冗余优化,减少模型的内存占用,让模型可以在显卡上训练,内存占用主要分为Model States和Activation两个部分,Zero主要解决的是Model States的内存占用问题。
- Zero offload:零卸载,将训练阶段的某些模型状态放(offload)到内存以及CPU计算。
- 混合精度:混合精度训练是指在训练过程中同时使用FP16(半精度浮点数)和FP32(单精度浮点数)两种精度的技术。使用FP16可以大大减少内存占用,从而可以训练更大规模的模型
Deepspeed 与torchrun 的区别: deepspeed 包含ZeRO零冗余优化器,模型并行、数据并行、混合。
torchrun 为数据、模型 并行训练。
2.库安装配置
1. pip install deepspeed 。 (直接查看是否存在ds_report, 有的环境不需要配置)
2. 到pyhton 安装目录 python/bin 中查看 ds_report .
3. 建立软连接:
ln -s /usr/local/python3/bin/ds_report /usr/bin/ds_report
ln -s /usr/local/python3/bin/deepspeed /usr/bin/deepspeed
配置教程端口:
https://huggingface.co/docs/transformers/v4.26.1/en/main_classes/deepspeed
https://www.deepspeed.ai/docs/config-json/#fp16-training-options
- deepspeed 实现demo
1. 初始化引擎。初始化分布式环境、分布式数据并行、混合精度训练设置等。可以根据配置文件参数构建和管理训练优化器、数据加载器和学习率调度器。
#Construct distributed model
model= BertMultiTask()
# Construct FP16 optimizer
model, optimizer, _ ,_=deepspeed.initialize(
args=args,
model=model,
model_parameters=model_parameters)
- 训练。引擎初始化后,即可通过3个api训练模型,用于前向传播、后向传播和权重更新。
#Construct distributed model
model= BertMultiTask()
…..
# Construct FP16 optimizer
model_engine, optimizer, _ ,_=deepspeed.initialize(
args=args,
model=model,
model_parameters=model_parameters)
for step,batch in enumerate(data_loader):
# Forward pass
loss = model_engine(batch) #前向传播
# Backward pass
model_engine.backward(loss) #反向传播
# weight update
model_engine.step() #参数更新
- 启动训练程序
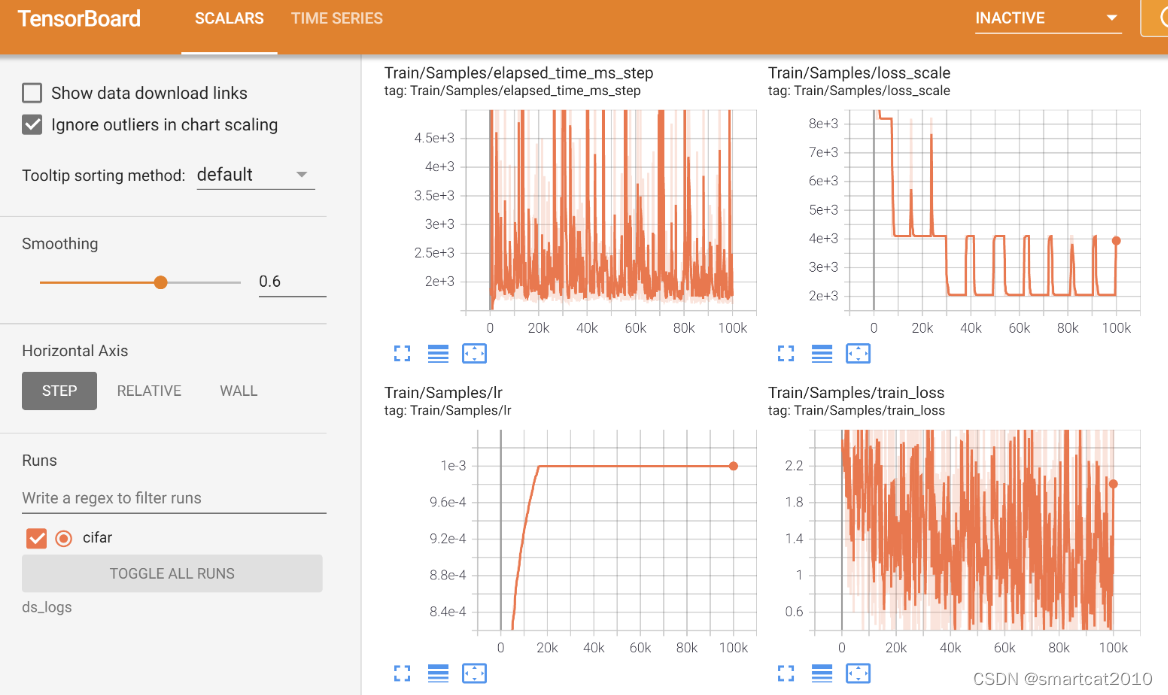
训练过程中的配置参数,可以通过配置文件configjson文件决定某个功能是否启用,如下图中,设置batch_size大校,梯度累积的步数、优化器类型、学习率、训练精度、是否使用零冗余优化等。 1. 使用单节点(一台服务器)启动,如指定gpu worker-2, 0卡和1 卡。
1. 使用单节点(一台服务器)启动,如指定gpu worker-2, 0卡和1 卡。
deepspeed --include="worker-2:0,1" train.py --deepspeed --deepspeed_config ds_config.json
1.1 deepspeed 与trainer 接口结合时,可以将配置文件配置到trainer 参数上,启动可为:
export NCCL_IB_DISABLE=1; export NCCL_P2P_DISABLE=1; NCCL_DEBUG=INFO deepspeed --include=localhost:0,1 test1.py>output.log 2>&1 &
#日志打印到文件夹
#NCCL_DEBUG :从NCCL显示的调试信息
#NCCL_IB_DISABLE: 是否关闭IB通信 设置成1来启用TCP通信,一般需要设置成0或者默认不动
# NCCL_P2P_DISABLE=1 : p2p通信,为1时禁用。
如何配置deepspeed参数
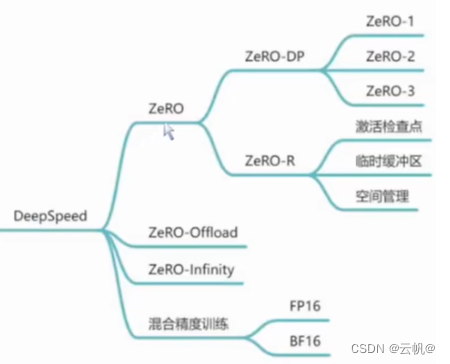
4.1 deepspeed 配置主要包括:精度配置模块,优化器模块、零冗余优化器模块、预热调度器模块、batch_size/梯度等模块。
1 混合精度配置模块对应:“fp16”:{} 部分。 核心 (对应混合精度训练)
2 优化器配置模块对应:“optimizer”:{}。
3 零冗余优化器模块对应:“zero_optimization”:{}。 核心:对应ZeRO 技术, 内含 ZeRO-Offload、ZeRO-Infinity。
4 预热调度器模块:“scheduler”:{}。
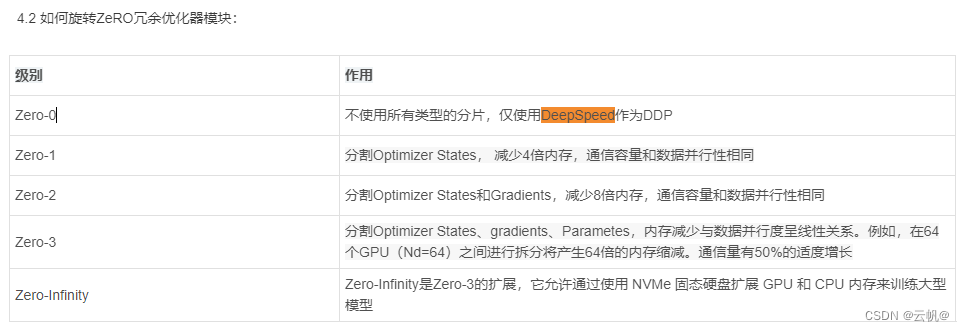
5 其他配置。4.2 如何旋转ZeRO冗余优化器模块:
 总结:
总结:
1. ZeRO-1、ZeRO-2和ZeRO-3是递进的优化级别,每个级别都在前一个级别的基础上减少更多的内存冗余。
2. ZeRO-1主要优化优化器的存储,ZeRO-2进一步优化模型参数和优化器状态的存储,而ZeRO-3还包括对激活的优化。
3. 随着优化级别的提高,能够支持的模型大小也随之增加,但同时对集群的通信和计算能力要求也更高。
4. 如果其他配置相同,ZeRO-3 可能会比 ZeRO-2 慢,因为除了 ZeRO-2 之外,前者还必须收集模型权重。如果 ZeRO-2 满足您的需求,并且您不需要扩展到几个 GPU 之外,那么您可以选择坚持使用它。重要的是要了解,ZeRO-3 以速度为代价实现了更高的可扩展性。速度方面(左边比右边快)
阶段 0 (DDP) > 阶段 1 > 阶段 2 > 阶段 2 + 卸载 > 阶段 3 > 阶段 3 + 卸载
GPU 内存使用情况(右侧的 GPU 内存效率高于左侧)
阶段 0 (DDP) < 阶段 1 < 阶段 2 < 阶段 2 + 卸载 < 阶段 3 < 阶段 3 + 卸载
首先将批量大小设置为 1(您始终可以使用梯度累积来获得任何所需的有效批量大小)。
启用--gradient_checkpointing 1(HF Trainer)或直接model.gradient_checkpointing_enable()- 如果 OOM 那么
首先尝试 ZeRO 第 2 阶段。如果 OOM 那么
尝试 ZeRO 阶段 2 + offload_optimizer- 如果 OOM 那么
切换到 ZeRO 阶段 3 - 如果 OOM 那么
启用offload_param-cpu如果 OOM 那么
启用offload_optimizer-cpu
4.3. 参数详解
每个模块可参考配置文档:DeepSpeed Integration (huggingface.co)
{
"optimizer": { #优化器配置模块
"type": "Adam",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"fp16": { #精度配置模块,此处选择float16
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"zero_optimization": { #零冗余配置
"stage": 3, #zero-3 技术
"offload_optimizer": { #内存溢出,将优化器参数卸载到cpu中。
"device": "cpu",
"pin_memory": true
},
"offload_param": { #内存溢出,将模型参数卸载到cpu中。
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true, #性能微调参数
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"scheduler": { #预热调度器配置
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"gradient_accumulation_steps": "auto", #梯度累积
"gradient_clipping": "auto", #梯度截断
"steps_per_print": 200,
"train_batch_size": "auto", #batch
"train_micro_batch_size_per_gpu": "auto", #每个gpu训练batch_size
"wall_clock_breakdown": false,
}
- 案例分析
案例1: firefly 框架 ds_z3配置,采用zero-3, fp16精度。
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 200,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false,
"optimizer": {
"type": "Adam",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
}
}
案例2: chatglm3 采用zero-3与bf16。
{
"train_micro_batch_size_per_gpu": "auto",
"zero_allow_untested_optimizer": true,
"bf16": {
"enabled": "auto"
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"zero_optimization": {
"stage": 3,
"allgather_partitions": true, #每个step 结束时,收集gpus 更新后的参数
"allgather_bucket_size": 5e8, #搜集元素的数量,将张量分成较小的桶有助于在通信中更高效的传输数据。这个值越大,每个桶的大小就越大,通信操作可能会变得更快。
"reduce_scatter": true, #平均梯度
"contiguous_gradients": true, #默认为True
"overlap_comm": true, #推荐设置为True,deepspeed将在梯度计算时尝试并执行梯度通信。可以有效的减少通信时间,从而加速整个训练过程。
"sub_group_size": 1e9, #控制在优化器步骤中参数更新的粒度。当出现omm时,减小该值;当优化器迭代较缓慢时,也可以考虑增大该值,默认值是1e9
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto", #预取参数的固定缓冲区大小。较小的值使用的内存较少,但也可能会因为通信而增加停顿。默认值是5e8。
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9, #保留在gpu上的完整参数数量的上限。默认值是1e9
"stage3_max_reuse_distance": 1e9, #根据参数在未来何时再次使用的指标来决定是舍弃还是保留参数。如遇omm,可减小stages_max_live_parameters和stages_max_reuse_distance
"stage3_gather_16bit_weights_on_model_save": true #在保存模型时启用模型fp16权重合
}
}
案例3,qwen1.5 ,采用bf16与fp16混合精度 zero-3 训练
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "none",
"pin_memory": true
},
"offload_param": {
"device": "none",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 100,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "none",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 100,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
























![[Linux] git工具的安装和使用](https://img-blog.csdnimg.cn/direct/0653c0827d2c4df09003b1502cafb9c1.gif)