🚀 作者 :“大数据小禅”
🚀 文章简介 :从零开始部署ChatGLM-6B语言模型,本专栏后续将持续更新大模型相关文章,从开发到微调到应用,需要下载好的模型包可私。
🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬
1.什么是ChatGLM-6B
ChatGLM-6B 是的一种自然语言处理模型,属于大型生成语言模型系列的一部分。"6B"在这里指的是模型大约拥有60亿个参数,这些参数帮助模型理解和生成语言。ChatGLM-6B 特别设计用于对话任务,能够理解和生成自然、流畅的对话文本。
这个模型通过大量的文本数据进行训练,学习如何预测和生成语言中的下一个词,从而能够参与到各种对话场景中。它可以用于多种应用,比如聊天机器人、自动回复系统和其他需要语言理解的技术中,ChatGLM-6B 的能力取决于它的训练数据和具体的实现方式,通常能够处理复杂的语言任务,提供有用和合理的回复。
2.开源仓库
- ChatGLM的github地址如下
- https://github.com/THUDM/ChatGLM-6B
- 有非常详细的文档介绍
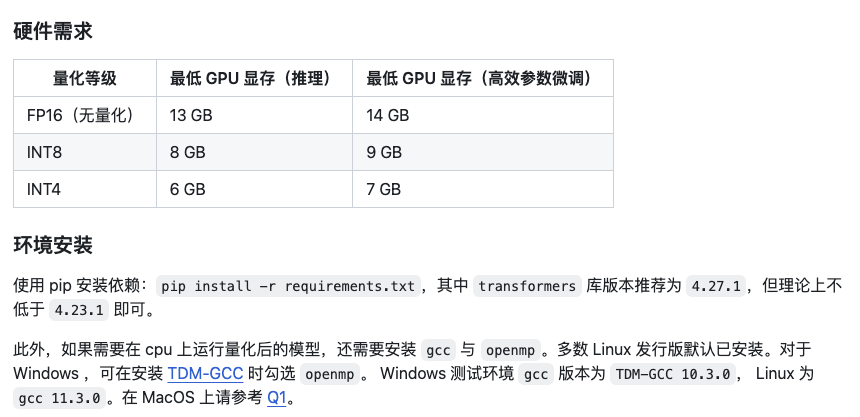
2.1硬件要求
3.模型运行环境搭建
- python环境
- 建议使用Anaconda方便对管理相关的库进行python环境的隔离
- 版本要求:为了避免一些千奇百怪的兼容错误,版本要求大于3.10
- conda创建虚拟环境
conda create -n chatglm-6b python==3.10.4conda activate chatglm-6b
- ChatGLM-6B代码下载
- 使用git命令进行代码拉取
git clone https://github.com/THUDM/ChatGLM-6B.git- 进入到下载好的文件目录,下载相关依赖
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simplepip install -i https://pypi.tuna.tsinghua.edu.cn/simple streamlitpip install -i https://pypi.tuna.tsinghua.edu.cn/simple streamlit-chat- 环境隔离之后,这里的版本不影响其他项目的依赖版本,这里需要注意,每一个版本严格按照要求下载,否则容易出错
4. 模型下载
- 代码由 transformers 自动下载模型实现和参数。完整的模型实现可以在 Hugging Face Hub。如果你的网络环境较差,下载模型参数可能会花费较长时间甚至失败。此时可以先将模型下载到本地,然后从本地加载。
- 从 Hugging Face Hub 下载模型需要先安装Git LFS ,然后运行
git clone https://huggingface.co/THUDM/chatglm-6b
- Git LFS安装 -> https://docs.github.com/zh/repositories/working-with-files/managing-large-files/installing-git-large-file-storage
- 将模型下载到本地之后,上代码中的 THUDM/chatglm-6b 替换为你本地的 chatglm-6b 文件夹的路径,即可从本地加载模型。
5.模型调用
5.1 代码调用
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
#model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
#macbook需要调用mps后端
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().to('mps')
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。
如果你没有 GPU 硬件的话,也可以在 CPU 上进行推理,但是推理速度会更慢。使用方法如下(需要大概 32GB 内存)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).float()
- 如果你没有 GPU 硬件的话,也可以在 CPU 上进行推理,但是推理速度会更慢。使用方法如下(需要大概 32GB 内存)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).float()
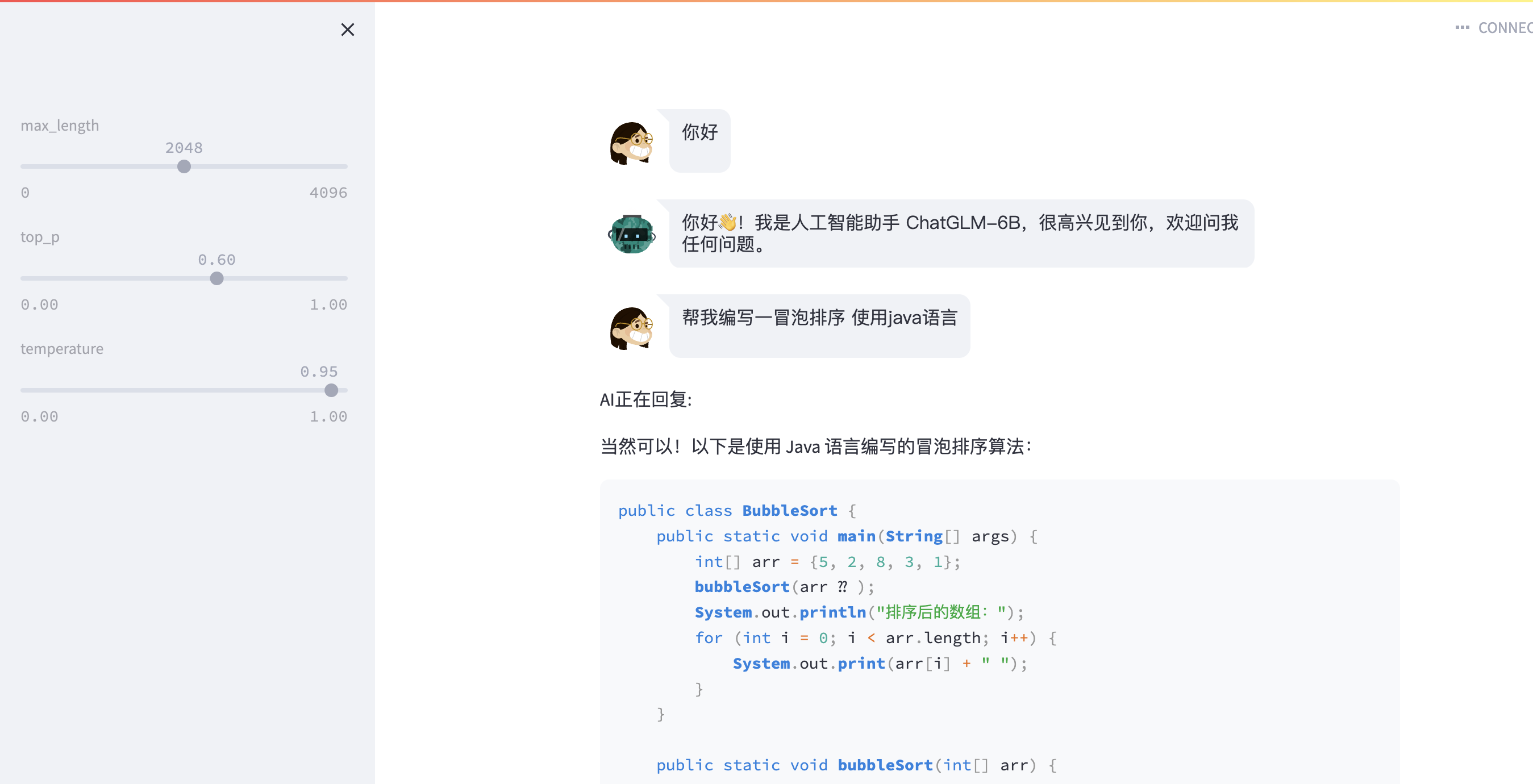
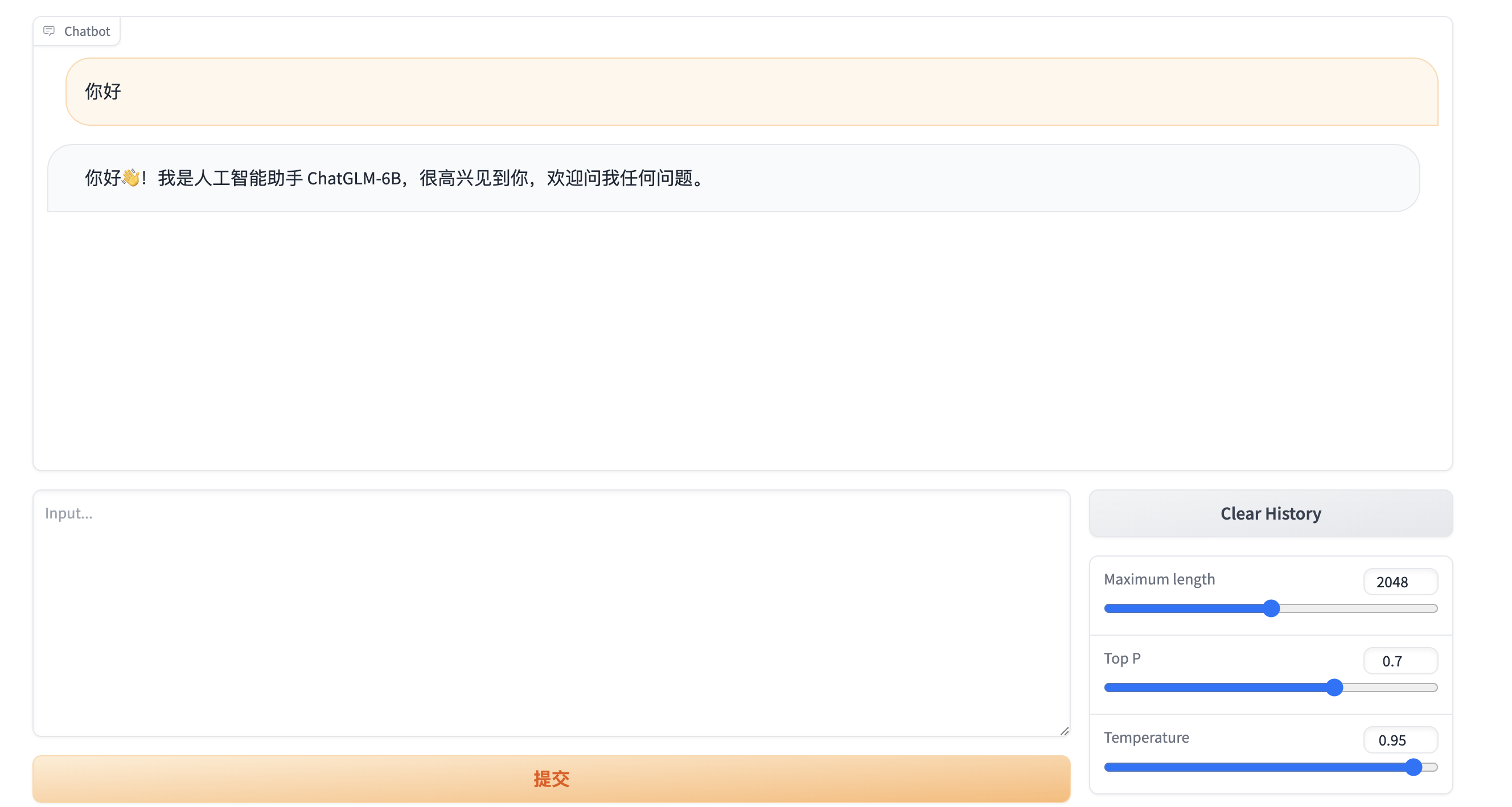
5.2 web页面调用
- 运行 streamlit run web_demo2.py 可直接进行web页面的对话
- 或者直接运行web_demo.py文件 使用 gradio
6.报错解决相关文章参考
-
- https://github.com/THUDM/ChatGLM-6B/issues/6#issuecomment-1471303336%20 运行时错误:未知平台:darwin
- https://github.com/THUDM/ChatGLM-6B/issues/281 LLVM ERROR: Failed to infer result type(s).