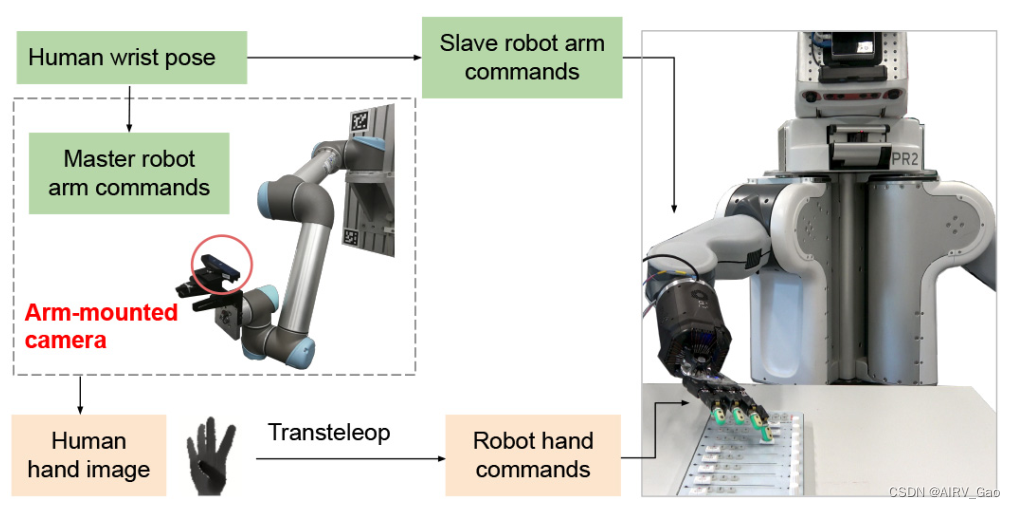
第一步 导入包
import jieba.posseg as psg
import pandas
from wordcloud import WordCloud
from PIL import Image
import numpy as np
import matplotlib.pyplot as pltjieba分词库,作用是将长文本可以分成一个一个词汇,而我们的词云正是基于词汇频率生成的
wordcloud词云库,用来生成词云图片
matplotlib用于保存和显示图片
第二步 读取文本
这里以文本保存在txt格式为例,如果想知道保存在csv、xlsx或者其他格式文档中的数据如何进行读取并生成词云,请滑动到最底部关注公主号,留言,会进行回复。
with open("文本.txt", 'r', encoding='utf-8') as f:
lines = f.readlines()第三步 分词
分词这里可以做的工作有很多,首先可以从互联网下载专用的中文停用词表,里面是已经整理好的一些不重要的词。
我这里采用了其他方法进行词汇过滤,大家进行词云生成的时候可以效仿,注意我这里导入的是jieba.posseg 而非 jieba,因为前者可以进行更进一步的词性和词汇长度的筛选。
s= "".join(lines)
result=psg.cut(s)
text_split = []
for x in result:
if len(x.word)>=2 and len(x.word)<=3: #筛选文本中2个字的词和3个字的词
text_split.append(x.word)
text_split = pandas.Series(text_split)
articleDict = dict(text_split.value_counts())首先将txt中读取到的文本合并成一个长句子,然后进行分词保存在result中(<class 'generator'>),依次访问result中的词汇进行过滤,利用.word可以直接提取该词的内容,而.flag可以提取该词的词性,这里我只对词的长度进行了过滤,如果你想只要名词这里可以添加一个判断(x.flag == 'n'),.flag对应词性分别缩写是什么可以去该库的使用方法里查询
将过滤后的词保存在列表中,然后组装成字典形式,因为词云的源数据格式必须为字典格式
第四步 生成词云
# 加载遮罩图片
mask_image = Image.open("1.jpeg")
mask_array = np.array(mask_image)
# 生成词云
wc = WordCloud(background_color="white",
width=800,
height=800,
font_path='msyh.ttf',
max_words=1000,
mask=mask_array,
).generate_from_frequencies(articleDict)
# 保存和显示词云
wc.to_file('词云.png')
print("词云图片已保存")加载蒙版图片,这一步非必须,如果不自己指定蒙版的话,生成的图片就是一个正方形轮廓。指定了蒙版词云生成时会有一个图案轮廓。width和height分别对应这个词云图片的宽和高,font_path这个很重要,如果没有指定的字体文件,默认生成的词云是不显示中文的将会看到一个个空白方框。这个文件需要大家自行百度下载然后保存在你的项目文件夹下(或者其他地方也ok,只要这里路径指定正确能让程序找到这个字体文件就行)。max_words规定了这个词云图片中能容纳最多的词汇数目,如果你不想词云看起来拥挤这里的值就可以设置小一点。mask蒙版参数,如果没用蒙版这个参数可以删除。
第五步 展示词云
# 显示图片
plt.figure(figsize=(10, 10))
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()
这一步没啥好说的,就是把词云图展示出来。你也可以不要这一步,直接去找保存下来的词云图点击查看。


如果还有不会的欢迎关注我的公主号,留言询问,我会耐心解答,希望可以帮助每一个初学python的同学。
注意事项(完整的代码和数据在公主号和Github)
大家白嫖代码的时候一定要注意我标明的三方库版本,版本不对很有可能会出错,此外最后保存数据的方法有很多大家可以自行挑选更改。
最重要的一点,如果大家觉得有用跪求大家给我一个关注和点赞,有不懂的问题可以私信或者留言,欢迎大家关注我的公主号,上面有更多更详尽的代码,喜欢白嫖的有福了。

GitHub - Maekfei/Spider-projects: 爬虫实战,集合了数十个爬虫实战代码,全都亲测可用,借鉴麻烦点个star谢谢 同时欢迎访问我的github主页,copy代码的同时别忘了点个star 谢谢!


























![[C++] 类和对象:运算符重载](https://img-blog.csdnimg.cn/img_convert/565e1eccafb1168e88402956ea5604bf.png)