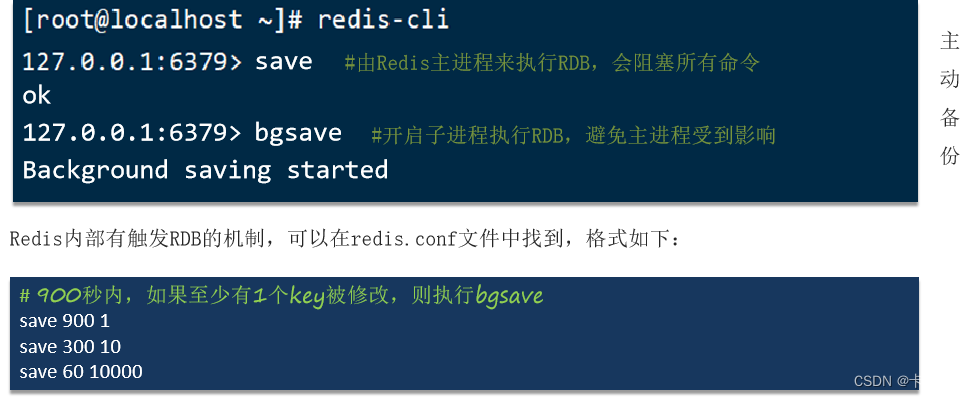
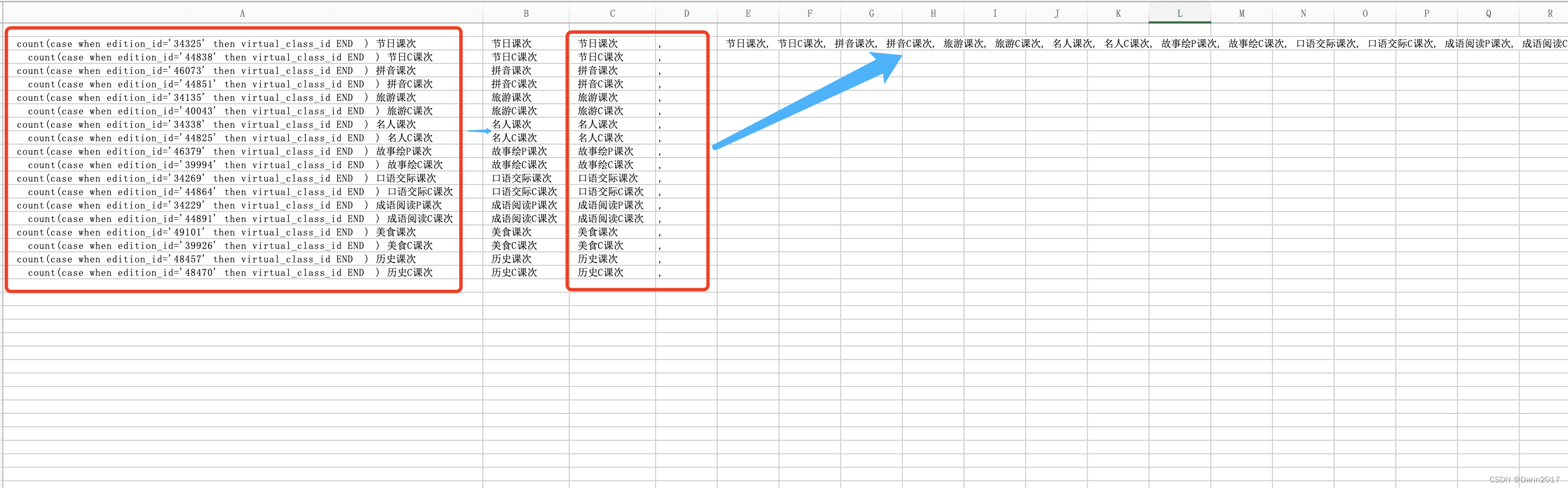
背景
本篇文章基于最新版本:kafka 3.7,其他版本的设计,请参考官网:
https://kafka.apache.org/documentation/
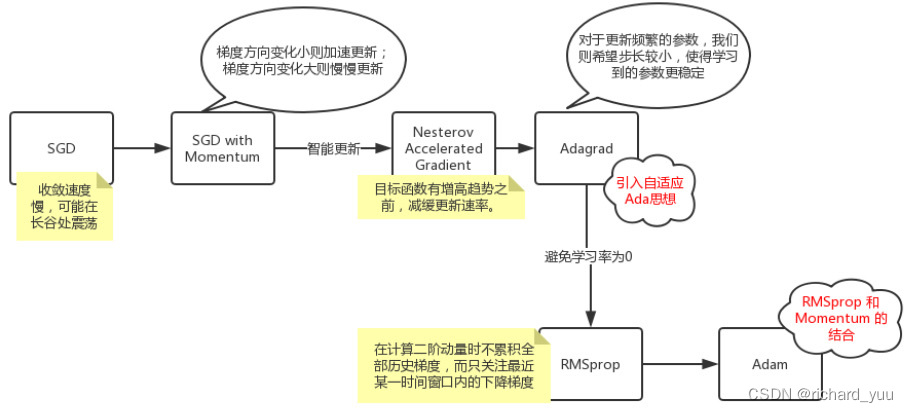
设计动机
任何组件都有它存在的必要,必然是要解决某一类问题的。我们来看看kafka设计的初衷如何。
kafka定位:一个能够处理所有实时数据的统一平台。
注意这里有两个关键词:实时数据、统一的平台。
实时数据:我们可以大致解释为,kafka设计之初是专门针对实时数据流场景的。真实生产环境中也是如此,我们一般利用kafka用来接收实时流数据,而且往往是大数据量的场景,它能轻松的抗住上万的qps,并且具备消息持久化的能力。
统一平台:这里平台的意思,我个人理解是,不仅提供了消息中间件的能力,还提供了一系列配套的功能,来辅助完成消息的认证、接入、加工处理。这里分别指的是:SASL、Connect和Kafka Streaming。
基于以上目标,kafka必须拥有高吞吐,才能支持像实时日志聚合这样的大体量数据流,通常大公司,实时日志数据量会非常多,一天能到亿级别甚至更高。它还需要能够优雅的处理大量的积压数据,来支持离线场景周期的数据加载。这也意味着,这个系统需要能够具备低延迟的发送,来处理更加传统的消息使用场景。
最后,在提供数据流给其他数据系统过程中,我们需要保证机器在出现故障时的容错能力。
综上:kafka这个系统,最少需要具备以下能力:
- 高吞吐
- 大数据量场景
- 低延迟的消息处理
- 很强的容错能力
持久化
不要害怕文件系统!
Kafka很大程度的依赖文件系统来存储和缓存消息。在目前看来,与固态硬盘、内存等相比,大家总认为磁盘非常慢,这也让大家抱有怀疑,利用磁盘来进行持久化是否能够提供有竞争力的性能。
事实上,磁盘的效率取决于大家怎么用,他会比我们想象中的更快(用得好)或更慢(用的差),并且适当的磁盘结构设计往往能够像网络一样快。
磁盘性能的关键因素是在近十年来硬件驱动器的吞吐量已经和磁盘寻址延迟不同。因此,在具有六个7200转速的SATA RAID-5阵列的JBOD配置上,线性写入的性能约为600MB/秒,但是随机写入的性能只有大约100k/秒,两者之间相差6000倍。这就是为什么上面说的,磁盘用得好比我们想象中的快,用不好比我们想象的慢。这些线性读写是所有使用场景中最容易预测的,操作系统做了很多的优化。一个现代操作系统提供了预读和后写的技术,以大块倍数进行数据预读取并且将较小的写入操作合并为一次较大的物理写入,写入这里可以理解为微批的思路。关于磁盘的一些研究发现,顺序的磁盘访问在一些场景下,能够比随机内存访问更快。
为了弥补性能的差异,现代操作系统积极的使用主存进行磁盘缓存。一个现代的操作系统在回收内存时,会很高兴的将所有可用内存转移到磁盘缓存,而几乎不会对性能造成影响。所有的磁盘读写操作都会通过这个统一的缓存(文件缓存)。这个特性在不使用直接I/O的情况下,不能轻松的被关闭,所以即使一个进程维护了一份数据的进程内的缓存,这份数据也会在操作系统的页缓存中被复制一份,会有效的将数据存储两次。
而且,我们是建立在JVM之上的,并且任何一个花时间使用过java内存的人知道这两件事:
- 对象的内存开销非常高,经常使存储的数据的大小翻倍,甚至更大。
- 当堆内的数据变大,Java的垃圾回收变得繁琐和缓慢。
由于上述这些因素,使用文件系统以及依赖页缓存更优于保持内存级的缓存或其他结构。通过自动的访问所有可用内存,我们至少能够将可用缓存翻倍,甚至通过存储紧凑的字节结构,而不是独立的对象,还能够再次翻倍。这样做能够在32G的机器上获得28-30G的内存空间,而不会受到GC的影响。
而且这部分缓存即使服务重启也会保持在热状态,然而进程内缓存是需要重建的(10GB缓存数据,可能需要10分钟),或者说需要从一个完全冷缓存中进行预热,这也伴随着很糟糕的性能。这极大地简化了代码,现在所有保持缓存和文件系统一致性的逻辑都在操作系统中,这也意味着比进程内一次性的尝试更加的高效和正确。如果你的磁盘使用场景倾向于线性读取,那么预读机制会在每次磁盘读时更有效的将有效数据填充到缓存中去。
这表明了一种非常简单的设计:并非在内存中保存越多的数据,然后在我们快用完空间时,恐慌的将数据刷入到文件系统中去,我们恰恰相反。所有的数据会被立即写到文件系统中的持久化日志文件中去,即不需要刷入到磁盘了。实际上这只意味着它被转移到内核的页缓存中去。真正刷盘的动作,由操作系统来保证。
下图简单描述了下页缓存和磁盘文件的关系:

这里简单总结下使用文件系统的好处:
- 顺序读写场景,比内存随机读更快
- 页缓存由os维护,一致性也由操作系统保证,对象存储效率更高
- 能够使用更大的缓存空间32G机器最高能用到30G的缓存,且不会受到gc的影响
因此,后续我们在设计系统时,不一定仅仅考虑数据在内存中保持,可以适当的考虑文件系统,充分利用操作系统的预读 + 批量刷盘机制。
恒定时间保证
消息系统中的持久化数据结构往往使用相关联的B树或其他通用的随机访问数据结构,来保存消息的元数据。B数是最通用的可用数据结构,并且在消息系统中支持多种事务和非事务的语义。但是B树有相当高的代价,对Btree的操作时间复杂度是O(log N)。一般来说O(log N)被认为基本等同于恒定时间,但是在磁盘操作中,这个结论不成立。磁盘寻址一次10ms,且磁盘同一时间只能做一次寻址操作,并行是有限制的。因此即使少量的磁盘寻址操作也会导致很高的代价。由于存储系统混合了非常快的缓存操作和非常慢的物理磁盘操作,树结构的观测性能常常随着混合数据的增长是超线性增长的,即:一倍的数据往往是性能降低一倍以上。
直观来说,持久化队列可以被构建为简单的读和文件追加的方式,这在日志解决方案中很常见。这个结构的优势是所有的操作是O(1)并且读写不会互相阻塞。这有很明显的性能优势,因为性能和数据规模是完全分离的,一个服务器可以使用便宜的、低转速的、1TB以上的 SATA磁盘设备。尽管他们的寻址性能很差,但是他们有着可接受的大数据量读写的性能并且只有1/3的价格以及3倍的容量。

可以访问几乎无限的磁盘空间而不会有性能衰减意味着我们可以提供一些其他消息系统不常见的功能。例如,在kafka中,当消息被消费后,我们不会尝试去尽快的删除消息,我们可以把消息保留相当一段时间,比如说一周(默认)。这使得消费者可以非常的灵活,比如说可以通过多个消费组,多次消费历史的消息。
随着数据量增大,kafka消息持久化以及读取,始终是恒定的时间:O(1)。
这也是一个亮点。特别是现在磁盘的转速越来越高,价格也始终保持很低,也让kafka越发的有优势。