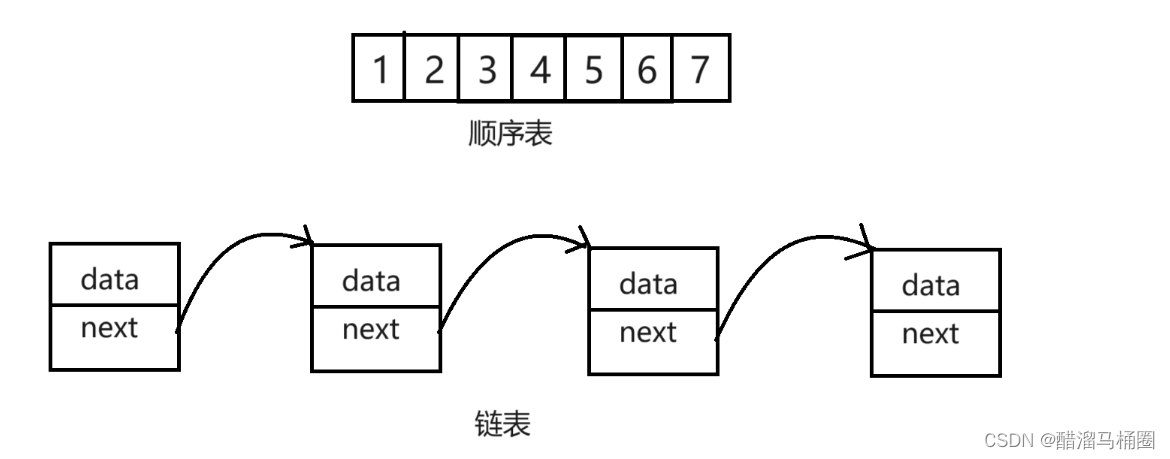
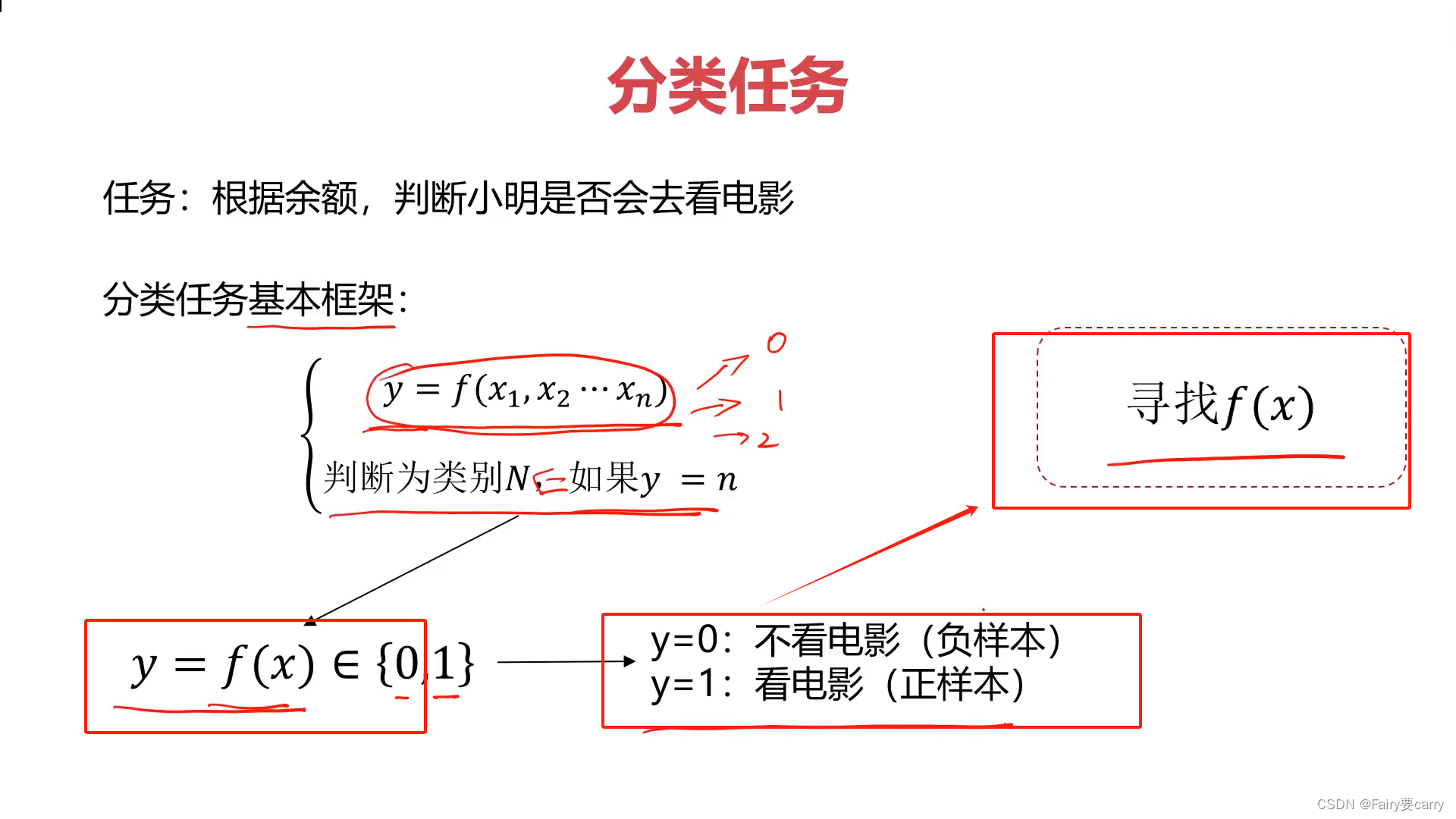
为什么需要链表
数组的底层原理是顺序存储,是一块连续的内存空间,有了这块内存空间的首地址,就能直接通过索引计算出任意位置的元素地址。
链表不一样,一条链表并不需要一整块连续的内存空间存储元素。链表的元素可以分散在内存空间的天涯海角,通过每个节点上的next, prev 指针,将零散的内存块串联起来形成一个链式结构。
这样做的好处很明显,首先就是可以提高内存的利用效率,链表的节点不需要挨在一起,给点内存 new 出来一个节点就能用,操作系统会觉得这娃好养活。
可以抽象为一条弯曲的链子,通过一个个环连接在一起。
另外一个好处,它的节点要用的时候就能接上,不用的时候拆掉就行了,从来不需要考虑扩缩容和数据搬移的问题,理论上讲,链表是没有容量限制的(除非把所有内存都占满,这不太可能)。
当然,不可能只有好处没有局限性。数组最大的优势是支持通过索引快速访问元素,而链表就不支持。
这个不难理解吧,因为元素并不是紧挨着的,所以如果你想要访问第 3 个链表元素,你就只能从头结点开始往顺着 next 指针往后找,直到找到第 3 个节点才行。
单链表
链表的创建
class Listnode:
def __init__(self, x):
self.val = x
self.next = None
def create_linked_list(nums):
head = Listnode(nums[0])
cur = head
for i in range(1, len(nums)):
cur.next = Listnode(nums[i])
cur = cur.next
return head
def print_linked_list(current_node):
while current_node:
print(current_node.val, end='->')
current_node = current_node.next
print('None')
if __name__ == '__main__':
nums = [1, 2, 3, 4, 5]
linked_list = create_linked_list(nums)
print_linked_list(linked_list)
最终的输出结果:1->2->3->4->5->None
链表的实现
class ListNode:
def __init__(self, val):
self.val = val
self.next = None
class MyLinkedList(object):
def __init__(self):
self.size = 0
self.head = ListNode(0)
def get(self, index):
"""
从链表中获取指定位置的元素值。
:param index: 要获取元素的位置索引,从0开始计数。
:type index: int
:return: 如果索引有效,则返回对应位置的元素值;否则返回-1。
:rtype: int
"""
# 检查索引是否超出链表范围
if index < 0 or index >= self.size:
return -1
cur = self.head
# 遍历链表至指定索引位置
for _ in range(index + 1):
cur = cur.next
return cur.val # 返回指定位置的元素值
def addAtHead(self, val):
"""
:type val: int
:rtype: None
"""
self.addAtIndex(0, val)
def addAtTail(self, val):
"""
:type val: int
:rtype: None
"""
self.addAtIndex(self.size, val)
def addAtIndex(self, index, val):
"""
在指定索引处插入一个新节点。
:param index: 要插入节点的索引位置。如果索引大于当前链表长度,则不做任何操作;
如果索引小于0,则将节点插入到链表开头。
:param val: 要插入的节点的值。
:return: None
"""
if index > self.size: # 如果索引大于链表长度,则直接返回,不做任何操作
return
if index < 0: # 如果索引小于0,将节点插入到链表开头
index = 0
self.size += 1 # 更新链表大小
pre = self.head
# 定位到要插入节点的前一个节点
for _ in range(index):
pre = pre.next # 逐个遍历,找到正确的位置
to_add = ListNode(val) # 创建新节点
to_add.next = pre.next # 新节点指向pre节点的next节点
pre.next = to_add # pre的next指向新节点
def deleteAtIndex(self, index):
"""
从链表中删除指定索引的元素。
:param index: 要删除的元素的索引。如果索引无效(小于0或大于等于链表长度),则不进行任何操作。
:type index: int
:return: None
"""
if index < 0 or index >= self.size:
return
self.size -= 1
pre = self.head
# 移动到要删除节点的前一个节点
for _ in range(index):
pre = pre.next
# 要删除节点的前一个节点next指向删除节点的后一个节点
pre.next = pre.next.next
双链表
链表的创建
class ListNode:
def __init__(self, val):
self.val = val
self.next = None
self.prev = None
def create_double_linked_list(arr):
if not arr:
return None
head = ListNode(arr[0])
cur = head
for i in range(1, len(arr)):
node = ListNode(arr[i])
cur.next = node
node.prev = cur
cur = cur.next
return head
def print_double_linked_list(head):
while head:
print(head.val, end='->')
head = head.next
if __name__ == '__main__':
head = create_double_linked_list([1, 2, 3, 4, 5])
print_double_linked_list(head)
链表的实现
class ListNode:
def __init__(self, x):
self.val = x
self.next = None
self.prev = None
class MyLinkedList:
def __init__(self):
self.size = 0
self.head, self.tail = ListNode(0), ListNode(0)
self.head.next = self.tail
self.tail.prev = self.head
def get(self, index: int) -> int:
"""
从链表中获取指定位置的元素值。
"""
# 检查索引是否超出链表范围
if index < 0 or index >= self.size:
return -1
# 选择从头结点还是尾结点开始遍历取决于索引的位置,以优化遍历效率
# 以索引值作为分割,左边短就从头结点开始遍历,右边短就从尾结点开始遍历
if index + 1 < self.size - index:
curr = self.head
# 遍历链表到达指定索引位置
for _ in range(index + 1):
curr = curr.next
else:
curr = self.tail
# 遍历链表到达指定索引位置
for _ in range(self.size - index):
curr = curr.prev
# 遍历链表到达指定索引位置
return curr.val
def addAtHead(self, val: int) -> None:
self.addAtIndex(0, val)
def addAtTail(self, val: int) -> None:
self.addAtIndex(self.size, val)
def addAtIndex(self, index: int, val: int) -> None:
"""
在双向链表的指定位置插入一个新节点,并保持双向链表的有序。
"""
# 处理index大于链表长度的情况,直接返回不进行操作
if index > self.size:
return
# 将负索引调整为0
if index < 0:
index = 0
# 确定插入位置的前驱节点和后继节点
if index < self.size - index:
# 当index在链表前半部分时,正常计算前驱节点和后继节点
pred = self.head
for _ in range(index):
pred = pred.next
succ = pred.next
else:
# 当index在链表后半部分时,从尾部向前计算前驱节点和后继节点
succ = self.tail
for _ in range(self.size - index):
succ = succ.prev
pred = succ.prev
# 更新链表大小
self.size += 1
# 创建新节点并插入到链表中
to_add = ListNode(val)
to_add.next = succ
to_add.prev = pred
pred.next = to_add
succ.prev = to_add
def deleteAtIndex(self, index: int) -> None:
if index < 0 or index >= self.size:
return
if index < self.size - index:
# 当index在链表前半部分时,正常计算前驱节点和后继节点
pred = self.head
for _ in range(index):
pred = pred.next
succ = pred.next.next
else:
# 当index在链表后半部分时,从尾部向前计算前驱节点和后继节点
succ = self.tail
for _ in range(self.size - index - 1):
succ = succ.prev
pred = succ.prev.prev
self.size -= 1
pred.next = succ
succ.prev = pred