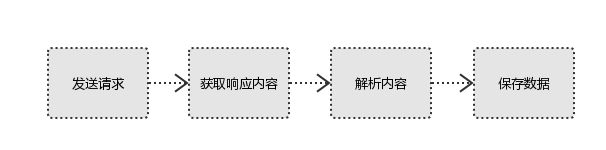
import requests
import json
yes=input('输入页数:')
yes=int(yes)
headers = {
"accept": "application/json, text/plain, */*",
"accept-language": "zh-CN,zh;q=0.9",
"content-type": "application/json",
"origin": "https://www.gaokao.cn",
"referer": "https://www.gaokao.cn/",
"sec-ch-ua": "\"Google Chrome\";v=\"123\", \"Not:A-Brand\";v=\"8\", \"Chromium\";v=\"123\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "cross-site",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
}
url = "https://api.zjzw.cn/web/api/"
ff=open('x.csv','w')
for paga in range(1,yes):
params = {
"big_min": "750",
"keyword": "",
"local_batch_id": "",
"local_province_id": "32",
"local_type_id": "2073",
"page": str(paga),
"province_id": "",
"size": "20",
"small_min": "0",
"type": "",
"uri": "apidata/api/gk/score/province",
"year": "2023",
"zslx": "0",
"signsafe": "7c6422ab7db981d40fe7115c1b439de2"
}
data = {
"big_min": 750,
"keyword": "",
"local_batch_id": "",
"local_province_id": "32",
"local_type_id": "2073",
"page": paga,
"province_id": "",
"signsafe": "7c6422ab7db981d40fe7115c1b439de2",
"size": 20,
"small_min": 0,
"type": "",
"uri": "apidata/api/gk/score/province",
"year": "2023",
"zslx": "0"
}
data = json.dumps(data, separators=(',', ':'))
response = requests.post(url, headers=headers, params=params, data=data)
res=response.json()
for i in res['data']['item']:
a=i['city_name']
b=i['county_name']
c=i['dual_class_name']
d=i['local_batch_id']
e=i['local_batch_name']
f=i['local_province_name']
g=i['local_type_name']
h=i['name']
j=i['nature_name']
k=i['province_name']
l=i['sg_info']
m=i['zslx_name']
n=str(i['min'])
ab=a+b
sg_name='专业组'+i['sg_name']
ff.write(','.join([h,a,b,g,e,c,sg_name,l,n,d,f,m,j,k,'\n']))
ff.close()